Uber’s backend is an exemplar of microservice architecture. Each microservice is a small, individually deployable program performing a specific business logic (operation). The microservice architecture is a type of distributed computing system, which is suitable for independent deployments and scaling of software programs, and so is widely used across modern service-oriented industries. Uber has a few thousand microservices interacting with one another via remote procedure calls (RPC).
A service request arriving at an entry point (aka end-point) to the Uber backend systems undergoes multiple “hops” through numerous microservice operations before being fully serviced. The life of a request results in complex microservice interactions. These interactions are deeply nested, asynchronous, and invoke numerous other downstream operations. As a result of this complexity, it is very hard to identify which underlying service(s) contribute to the overall end-to-end latency experienced by a top-level request. Answering this question is critical in many situations, for example:
- Identifying optimization opportunities for a top-level microservice
- Identifying common bottleneck operations affecting many services
- Setting appropriate time-to-live values for downstream RPC calls
- Diagnosing outages and error conditions
- Capacity planning and reduction
While latency is one of the metrics of interest, other metrics such as time-to-live, error rates, etc., also fall in the scope.
We have developed a tool, CRISP (named taking letters from critical and span), to pinpoint and quantify underlying services that impact the overall latency of a request in a microservice architecture. CRISP identifies the critical path in a complex service dependency graph and does so on a large number of traces. Critical path is the longest chain of dependent tasks in a microservice dependency graph. Reducing the critical path length is necessary to reduce the end-to-end latency of a request. Hence, a latency optimization effort benefits by prioritizing the services that are on the critical path.
CRISP uses RPC tracing facility provided by Jaeger™ and it constructs the critical path through a request’s graph of dependencies. It does so for a large volume of traces and then summarizes critical paths into digestible and actionable insights via rich heat maps and flame graphs. CRISP provides knobs to dissect the details with different percentile values.
Background
Critical Path in a Parallel Computation Graph
RPC calls among microservice operations form a directed acyclic graph (DAG). The parallel computing community has a very rich literature in analyzing computational graphs formed out of parallel computing tasks, irrespective of the programming model used. The computational DAG is formed of nodes and edges; nodes represent tasks (units of serial execution) and edges represent dependencies between tasks. A node with an out-degree greater than one spawns children tasks and a node with an in-degree greater than one waits (syncs) for the children to finish. Total work is the sum of weights of all nodes and critical path is the longest weighted path in the DAG as shown below in Figure 1. The longest path through the DAG is called the critical path in a parallel execution.

Formally, the critical path in a parallel computation DAG is the longest weighted (where each node has an associated weight) path through the DAG. The critical path is the sequence of late arrivers on whom the next tasks depend upon and hence the critical path has no wait states in it.
The critical path in a parallel program DAG represents the components of the program speeding which will speed the overall execution time of the parallel program.
Jaeger™ Microservice Tracing
Uber’s microservice architecture comprises a few thousand microservices. Each microservice exposes tens of operations (APIs), resulting in nearly a hundred thousand operations calling one another over RPC. Uber extensively employs Jaeger, an open-source tool software, for tracing transactions between microservices. Jaeger’s tracing allows microservice owners to observe and understand the complete chain of events that follow a service request. A Jaeger trace is a JSON blob consisting of several “spans.” A span is a unit of serial work (e.g., time spent in one microservice), analogous to a weighted node in the aforementioned computation DAG. Every span, except the root span, has a reference to its parent span, which establishes the caller-callee relationship among spans. The parent-child relationships come in 2 flavors: child-of and follows-from; the child-of relation represents a request-response relationship where the parent waits for the child (and its transitive closure) to finish; and the follow-from relation represents a “fire-and-forget” mode of operation where the parent does not wait for the child to finish. Every span also contains its host-local start time and duration of execution. Jaeger is language-independent, hence RPC calls through microservices written in myriad languages can be traced faithfully.
At Uber, most services are Jaeger enabled and hence we are able to collect a reliable dependency graph of RPC calls for a given request. However, the amount of data would be prohibitive if all requests were traced. Hence, we employ a sampling strategy to collect a fraction of requests. If a request is tagged for Jaeger monitoring at the system’s entry point, all its subsequent downstream calls made on behalf of the request are collected into a single trace. We store Jaeger traces in different data stores with different shelf lives. We refer the reader to the Jaeger Uber engineering blog and the open-source code base for further details about Jaeger.
Unfortunately, in a complex microservice environment, the Jaeger traces are hard to digest via visual inspection. Even a single trace can be very complicated as shown in the call graph and timeline views in Figure 2 below, which are taken from a real-world microservice interaction at Uber. This motivates the need for tooling to analyze and summarize the traces into actionable tasks for developers.


Critical Path Analysis of Jaeger Traces
Transforming Jaeger Traces into Computational DAGs
A distributed parallel program such as Uber’s microservices can be represented as a Directed Acyclic Graph (DAG) of its dependencies. Jaeger traces comprise “spans,” which represent the start and end of a service and each span can have children spans for the RPC calls that the service makes to the downstream services. The start and finish of these children spans represent the “spawn” and “sync” synchronization events, as we previously mentioned in the context of parallel computation DAGs.
The Critical Path Through a Jaeger Trace
The graph below shows a typical timeline view of the Jaeger trace augmented with the dependency edges; the critical path is highlighted in red color bars. Here, each bar is equivalent to a node in the previous classic DAG and the edges represent dependencies as usual. Node lengths represent their execution time (weight).
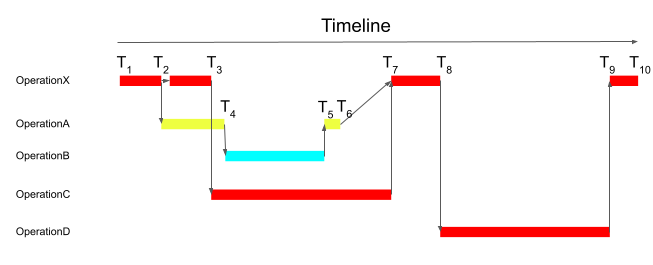
Here, OperationX is the top-level operation (for example, one of the entry points). OperationX runs from time T1 to T10. OperationX directly invokes operations OperationA, OperationC, and OperationD at different points in time. The calls to OperationA and OperationC overlap. OperationA in turn calls OperationB. The top-level operation OperationX is complete only when the transitive closure of all its descendant operations is complete. The critical path here is composed of the following fragments:
The time T2-T1 on OperationX,
The time T3-T2 on OperationX,
The time T7-T3 on OperationC,
The time T8-T7 on OperationX,
The time T9-T8 on OperationD, and
The time T10-T9 on OperationX.
Notice that OperationB does not appear on the critical path. This means that even though OperationB accounts for a significant portion of the total execution time (T5-T4), speeding OperationB has zero impact on speeding OperationX in the current setting; hence, performance tuning should deprioritize optimizing OperationB. In contrast, speeding OperationD, can reduce the time taken by OperationX by as much as T9-T8; hence performance tuning should prioritize optimizing OperationD. OperationC is more tricky. Speeding OperationC will definitely reduce the time taken by T7-T6 amount; but beyond that both OperationB and OperationC need to be sped up for further gains.
In summary, speeding up the components on the critical path is strictly necessary to speed up the service. Speeding up services on the critical path may not proportionately speed up the overall service, because they might overlap with other services; in such instances, the critical path shifts, which requires recomputing the critical path. However, the critical path provides strong evidence on which services to optimize first.
How to Compute the Critical Path from a Single Jaeger Trace
Computing the critical path from an individual trace involves replaying the trace in reverse order from the end of the trace to the beginning of the trace, looking for synchronization events.

Consider the example above in Figure 4: the walk begins from the end of the top-level span at time S1 at T10. The nearest synchronization event in the backward direction is the sync of a child span S3 at T9; the fragment T10-T9 is on the critical path. The focus shifts now to the last return child S3. Looking backward from T9 on S3, the last synchronization event is the sync of child S5 at T8; T9-T8 fragment (belonging to S3) is on the critical. The focus now shifts to the last return child S5. The last synchronization event on S5 is its creation at T5. The fragment T8-T5 is on the critical path. The focus now returns to S3. The last synchronization event on S3 before T5 is S3’s creation at T4. This puts the fragment T5-T4 on the critical path. Following this scheme, we add the fragments T4-T3, of S1, T3-T2 of S2, and T2-T1 of S1 onto the critical path. Although S4 has a nontrivial duration, it is not on the critical path since we meet the beginning and ending of S5, which enclose S4.
Critical Path (CP) Algorithm
The CP algorithm begins from the top-level span and sorts all its children based on their finish time. The result of the CP algorithm is all the components on the critical path. The algorithm iterates starting from the last finishing child (LFC) of the top-level Jaeger “span.” It recursively invokes CP on LFC, which computes the critical path for a given Jaeger span. On return from recursion, the CP algorithm walks backward and picks another child that returned immediately before the start of LFC (if there were any children that finished after the start of LFC, they will be ignored because they were not the late arrivers).
Inclusive vs. Exclusive Time
CRISP presents 2 views of the critical path time attributed to each operation S:
- Inclusive time on the critical path: This metric is the wallclock time elapsed in the S itself, plus the wallclock time elapsed in the transitive closure of all other operations S calls. This is also purely the duration of execution of S.
- Exclusive time on the critical path: This metric is the wallclock time spent in S itself. This metric neglects the time spent in S‘s children operation(s), say T, if T appears on the critical path.
As an example, if operation S is on the critical path and takes a total of 100ms for the entire call, and S calls T and T is also on the critical path and takes 80ms; then, the inclusive time on the critical path attributed S is 100ms and the exclusive time on the critical path attributed to S is 20ms.
Dealing with the Clock Skew
Jaeger spans use the local clock of the host serving its RPC to insert start and end times of spans. All times are in UTC but the clocks can have arbitrary skews. The only truth in Jaeger traces is the parent-child relationship. As a result, a parent span may start after its child span’s start; a child span may end after its parent span’s end, and any combination of these.
The clock skew can cause the following issues:
Serial Child Invocation Appearing as Overlapping Children

Consider an operation A that is a simple wrapper that invokes 3 underlying operations B, C, and D, in that order. The parent A waits for the prior call to return before invoking the next one. However, due to the time skew, in the Jaeger trace, operation B slightly overlaps with operation C and operation C also overlaps with D. The CP algorithm would only add D and B to the critical path and ignore C from the critical path. The algorithm would attribute the remaining time (time almost equal to the execution time of C) to A itself. This “misattribution” can mislead developers. We address this issue by allowing a small overlap among the overlapping children.
Child Span Outside Parent Span’s Time Range

In the span above in Figure 6, the recorded time shows that the child B ends after the parent A. In such situations, we truncate B (and recursively adjust span C in this case) to the finish time of A, as in Figure 7 below. Notice also that the process is recursive and adjusts C’s end time to that of the now adjusted end time of B.

CRISP employs similar truncation logic when a child starts before its parent’s start time, but ends after the parent’s start time. In a rare situation where a child’s operation appears completely outside its parent’s time range, we completely drop such a child (and its transitive closure) from consideration.
Aggregating Multiple Critical Paths from Many Traces
Each trace produces its own critical path. While analyzing the critical path from a single trace is interesting (and possible via CRISP), our goal is not so much to delve into an individual trace, but instead, by inspecting many traces, to offer general guidelines on which services often contribute (and how much) to end-to-end latency. With that in view, we summarize the data present in each critical path, collected from numerous traces, into an aggregate. The aggregation basically performs a summation of the time contributions of each operation on each critical path into a global pool of operations. A naive summation can provide a skewed world view since tail latency events overshadow the other events. With that in mind, we summarize at P50, P95, and P99 percentile of end-to-end latency values. In this aggregation step, we collapse the causality/time dimension present in the critical paths.
Presentation
We present the result in multiple ways to cater to different use cases. The result is an HTML summary file, which includes the following:
- Flame graphs
- A heatmap
- A textual summary
Figure 8 shows an example of interactive navigation of critical paths via flame graph:
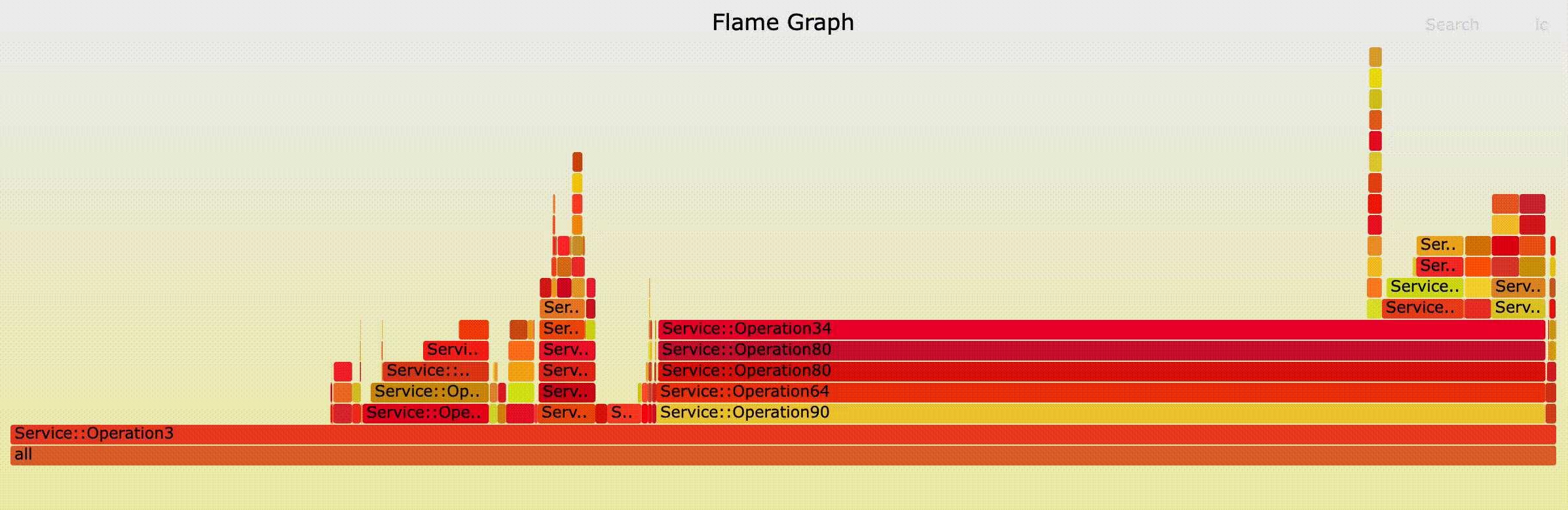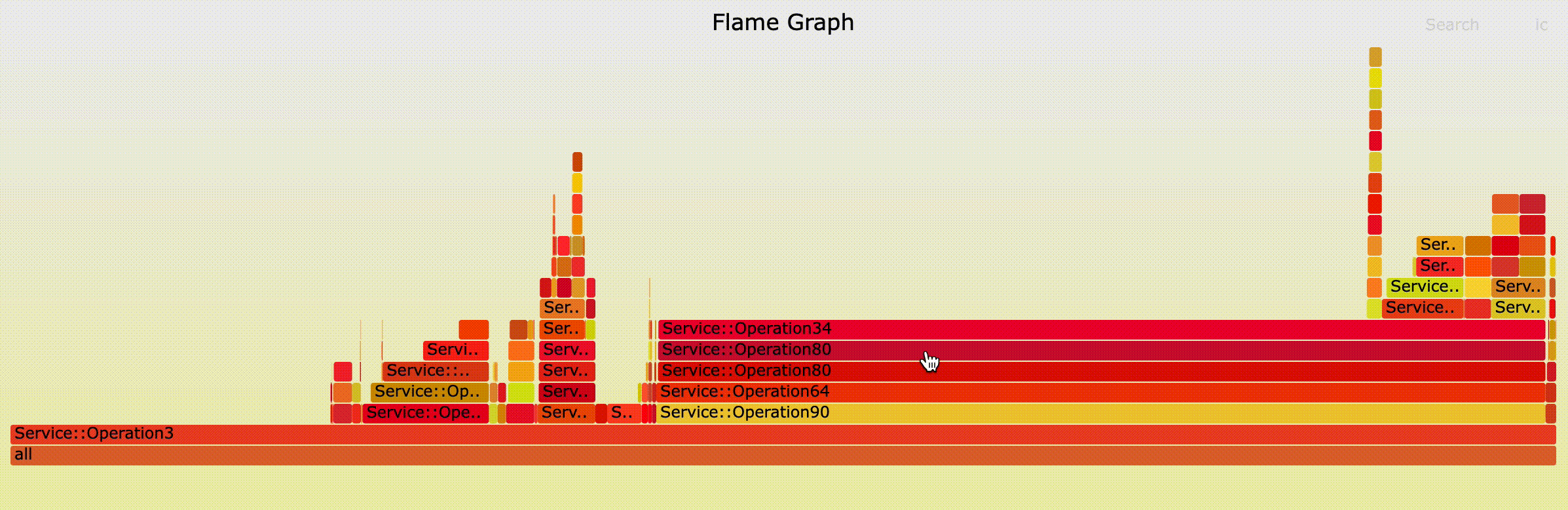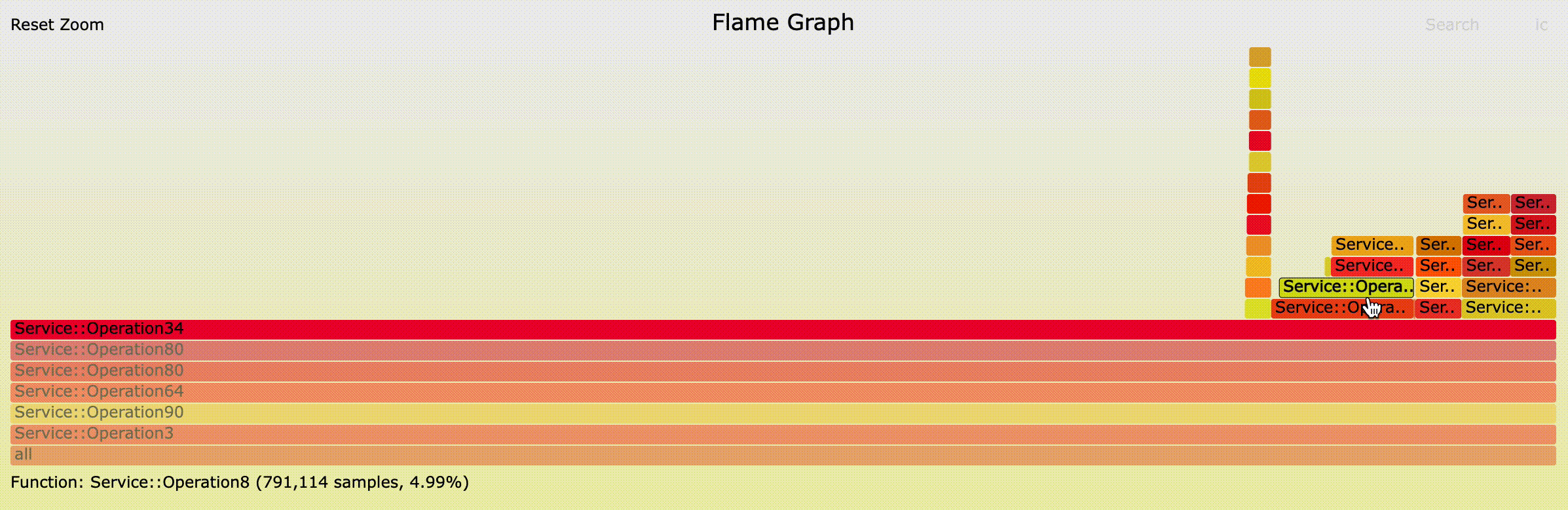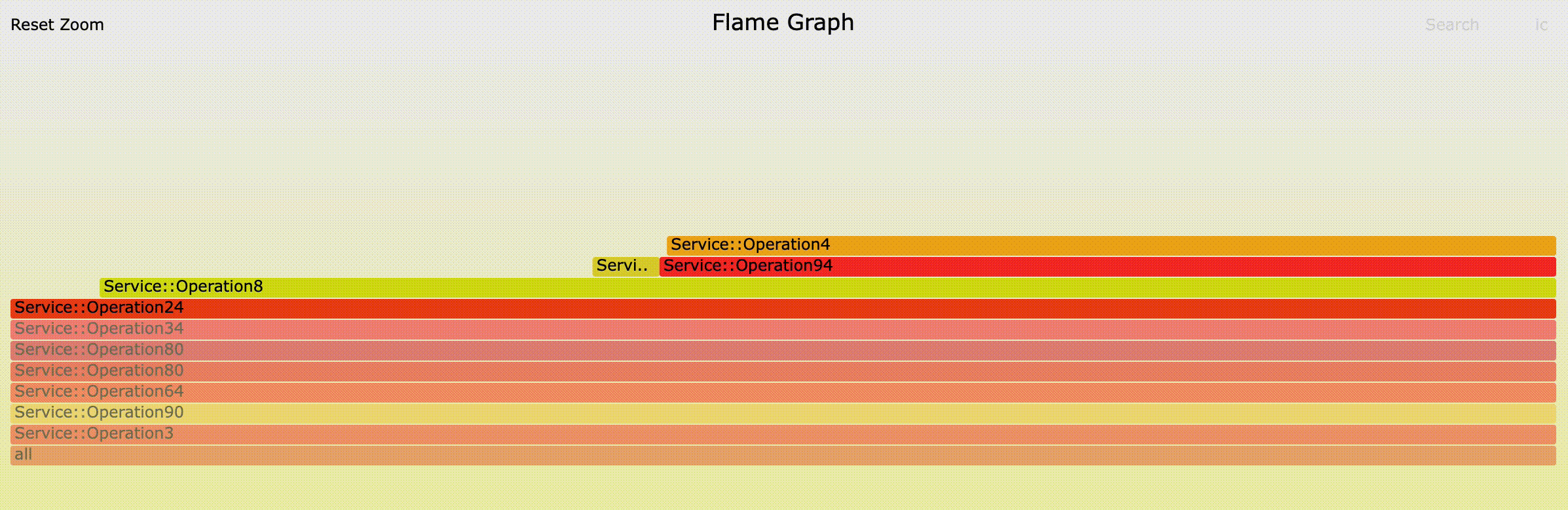
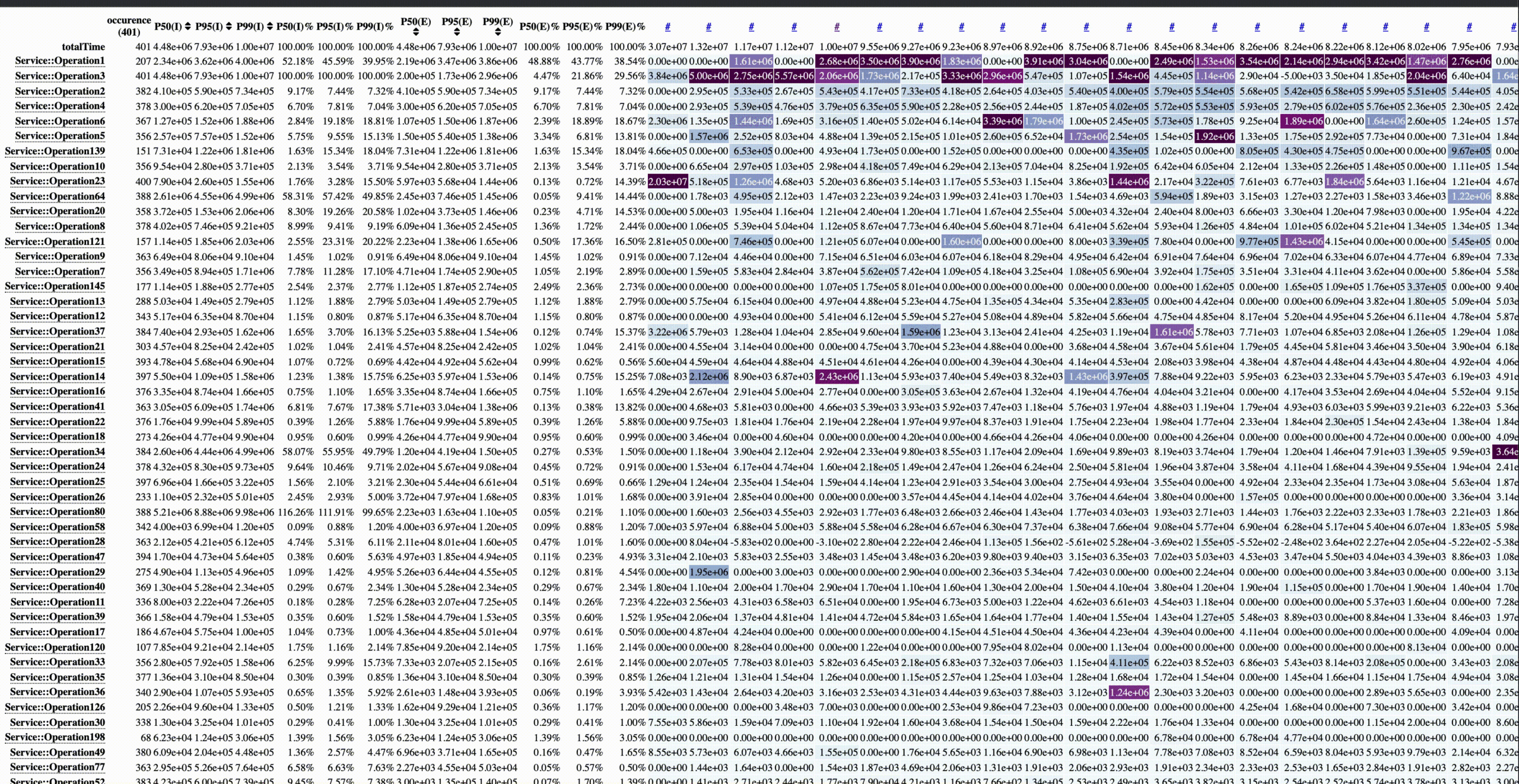
Figure 9 shows the full HTML which contains a heat map, 3 flame graphs, and a textual summary. The heat map allows a deep dive investigation showing the call paths reaching the top operations. It allows navigation via different percentile values and shows the significance of different components on the critical path in different traces.
Utility in Hardware Selection
In addition to the parent-child transitive relationships and times, Jaeger traces also contain additional information, such as the hostname on which the span was executed. Uber’s data center consists of diverse hardware CPU SKUs. Services can be installed on different hardware versions. Hence, a span executed on behalf of a request may run on different hardware on different requests.
We collected the critical path for one of our important services using CRISP and identified that a downstream operation “Op-M” was on the critical path. We further clustered the samples of Op-M based on the CPU version they were running on. The violin plot below, in Figure 10, shows how the latencies vary on 2 prominent CPU SKUs. The 2 SKUs are identical (i.e.., same vendor, microarchitecture, cache size, etc.) with the only exception that their CPU clock speeds are different. CPU-A runs at a slower 2.2 Ghz and CPU-B runs at a faster 2.4 GHz. This mild (9%) difference in the clock speed has a profound impact on the behavior of Op-M. The P50 value for SKU-B is ~15% lower than SKU-A. Moreover, the tail latency on SKU-A is 1.5x higher than the one on SKU-B.
To summarize, a slightly faster CPU clock proves to have a significant impact on reducing the tail latency and overall latency. This difference has a significant impact on the overall capacity allocation since tail latency (e.g., P95) is often used in capacity allocation. This observation demands further, systematic investigation into classifying critical path components as CPU SKU sensitive vs. insensitive; also, such categorization helps data center-wide microservice schedulers to favor SKU-sensitive services on the critical path onto their SKUs where they exhibit superior performance.

Conclusions
Prior efforts in tracing distributed microservices via Jaeger tracing have set the foundation for advanced performance analysis. In this work, we introduced CRISP, a tool to extract critical paths from numerous Jaeger traces. We demonstrated how to analyze and visualize complex microservice interactions with succinct critical path summary information via heatmaps and flame graphs. CRISP is deployed inside Uber for regular performance data collection and visualization for numerous microservices. Insights gained from CRISP are helping us identify and prioritize various performance problems. CRISP is made available at https://github.com/uber-research/CRISP.
Milind Chabbi
Milind Chabbi is a Staff Researcher in the Programming Systems Research team at Uber. He leads research initiatives across Uber in the areas of compiler optimizations, high-performance parallel computing, synchronization techniques, and performance analysis tools to make large, complex computing systems reliable and efficient.
Murali Krishna Ramanathan
Murali Krishna Ramanathan is a Senior Staff Software Engineer and leads multiple code quality initiatives across Uber engineering. He is the architect of Piranha, a refactoring tool to automatically delete code due to stale feature flags. His interests are building tooling to address software development challenges with feature flagging, automated code refactoring and developer workflows, and automated test generation for improving software quality.
Chris Zhang
Chris Zhang is a Software Engineer on the Programming System team at Uber. His research interests include computer architecture, compilers, operating systems, and microservices.