How Uber Uses Ray® to Optimize the Rides Business
Engineering Manager
Introduction
Computational efficiency is a significant challenge when scaling solutions to a marketplace as large and as complex as Uber. The running and tuning of the Uber rides business relies on substantial numbers of machine learning models and optimization algorithms. Luckily, many pieces of the system can be treated in parallel. Ray® is a general compute engine for Python® that’s designed for ML, AI, and other algorithmic workloads. We describe how Uber has adopted Ray to enable mission-critical systems. Using Uber’s mobility marketplace allocation tuning system as an example, we found performance improvements of up to 40 times that unlocked new capabilities. It also improved developer productivity by increasing iteration speed, reducing incident mitigation time, and lowering code complexity.
Motivation and Background
To manage the health and efficiency of the mobility marketplace, Uber has several levers it can adjust, such as offering incentives for drivers to complete a certain number of trips per week or promotions that provide riders with discounts on their trips. Figuring out how to set these levers to efficiently achieve various targets and maximize outcomes is both a technically challenging task and a high-value opportunity for the company.
One of the problems we’d like to solve is shown in Figure 1:
In this problem, we’d like to maximize some objective “f” that has some value to the business by changing the variables we control, “b.” Since these variables are controlled per city, we refer to the granularity as city-lever. We’re also subject to some constraints that are meant to keep the marketplace healthy. In practice, this is a problem that gets solved weekly, and the control variables remain in effect for a week.
To accomplish this, we leverage the vast amount of observational and experimental data at our disposal to inform these decisions. This requires building a system that can scale to handle large amounts of data for model training and inference, and accommodate many decision variables.
We designed a workflow shown in Figure 2 to achieve our goal. There’s a feature store system at the beginning to process the data and populate features for ML models for machine learning models. The second ML model training part does the model training and serving for predicting budget allocations. The third budget allocation part is doing the optimization and evaluation based on the equation in Figure 1 to find the most optimal budget allocation solution.
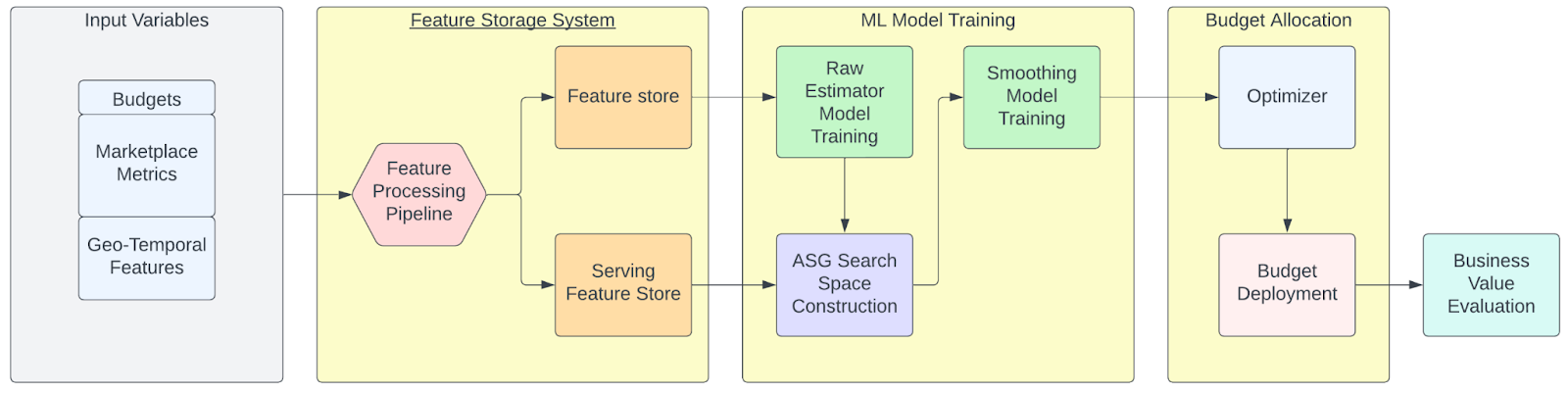
This original workflow is purely based on Apache Spark™ for distributed computations. Spark works pretty well when it comes to the data processing in the first feature store system part. However, when it comes to Pandas isn’t as good. We’ve tried Pandas UDF (User-Defined Function) or multi-threading for parallelism, but the speed improvement isn’t ideal. So, we decided to try Ray, as it’s designed for natural Python code parallelism.
Development and Deployment Challenges
There are some major bottlenecks in the original Spark-based budget allocation.
Parallel Nature of Spark vs. Ray: Distributed Framework Choice Bottleneck
As briefly introduced at the end of the previous section, Spark and Ray have their own pros and cons as a distributed framework. Spark is good at handling data processing given specific Spark/PySpark APIs, and it takes care of all the parallelisms between different Spark executors under the hood. However, Spark can’t accept Pandas operations or user-customized Python code and make them run in parallel automatically. On the contrary, Ray can easily make Pandas code or natural Python functions run in parallel, which is a perfect use case for applications that Spark can’t accelerate in our workflow. However, Ray can’t support Spark-related APIs so far and Ray itself has limited data processing API support like Spark. Ray data may be a potential solution in the future, but so far it’s mainly used for machine learning instead of general data processing purposes. So, it’s difficult to just use one simple distributed framework to achieve our goal. Both Spark and Ray have their own benefits we can take advantage of.
High-Concurrency, Lightweight Parallelism: Application Speed Bottleneck
We have many high-concurrency, lightweight parallel Python functions inside our applications. For example, we have an optimization function for each city and they can finish quickly in 1-2 seconds. However, if we want to do thousands of cities’ optimization functions simultaneously, the arrangement and allocation can be a problem. We’ve considered several methods:
- Spark: Since Spark doesn’t support Python functions in parallel without using Spark APIs, all these city optimization functions are running in series in Spark’s driver node only.
- Pandas UDF: We tried Pandas UDF on Spark to accelerate the Pandas dataframe operation speed. However, the speed improvement isn’t ideal. Also, Pandas UDF can’t parallelize general Python code.
- Independent job for each city: We need to launch a Docker® container for each city to run, which contains a launching overhead and potential computing resource waste.
Spark and Pandas-Based Codebase: Code Migration Bottleneck
Since we have legacy code running on a Spark-based cluster, there’s a lot of PySpark code written to do the data preprocessing and postprocessing. However, Ray doesn’t naturally support PySpark or Spark-related code. If we want to migrate all of our code to run on Ray, the code migration cost can be huge and requires many engineers to work together to convert all the legacy PySpark code to some equivalent Ray-understandabledable code.
Architecture Solutions
To address the bottlenecks mentioned in the previous section, we developed a hybrid mode with both Spark and Ray available in Figure 3. We think we should take advantage of the benefits from both Spark and Ray. The logic is simple and straightforward: put the data-processing related work on Spark and put the parallel Python functions on Ray.
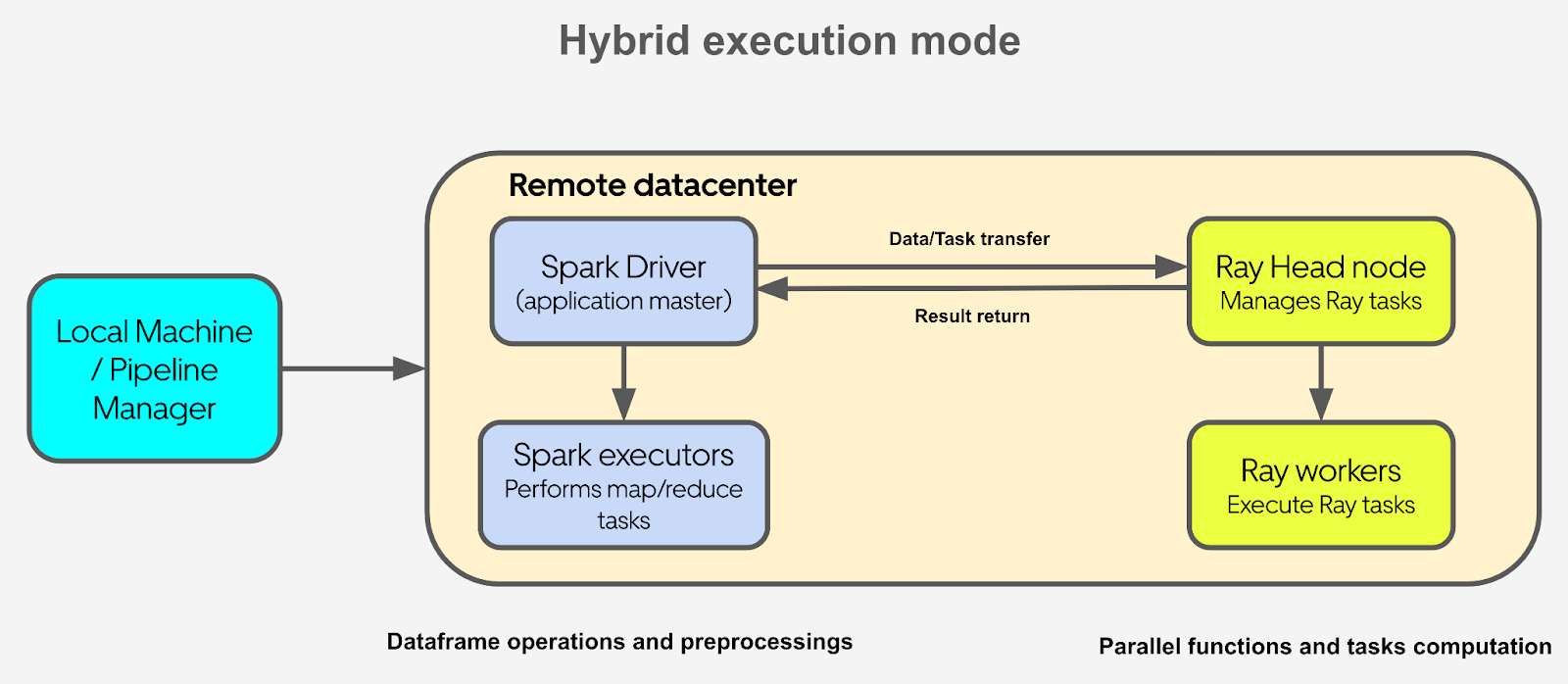
Figure 4 shows the application workflow. Spark driver plays an application master role here, and the application code mainly runs on Spark driver. When loading the data from Apache HDFS™ or doing data preprocessing, Spark driver distributes the workload to Spark executors and does any data-related computations. When the Spark driver encounters something that can’t be computed in parallel on Spark, it sends the task to Ray. The Ray cluster serves as an external computation server here on request. After receiving the function requests from Spark, it executes the functions sent from Spark driver in parallel and sends the results back to Spark driver when it’s done. Spark driver summarizes the output from Ray and does some data post-processing together with Spark executors. Finally, Spark writes the output data frame back to HDFS.
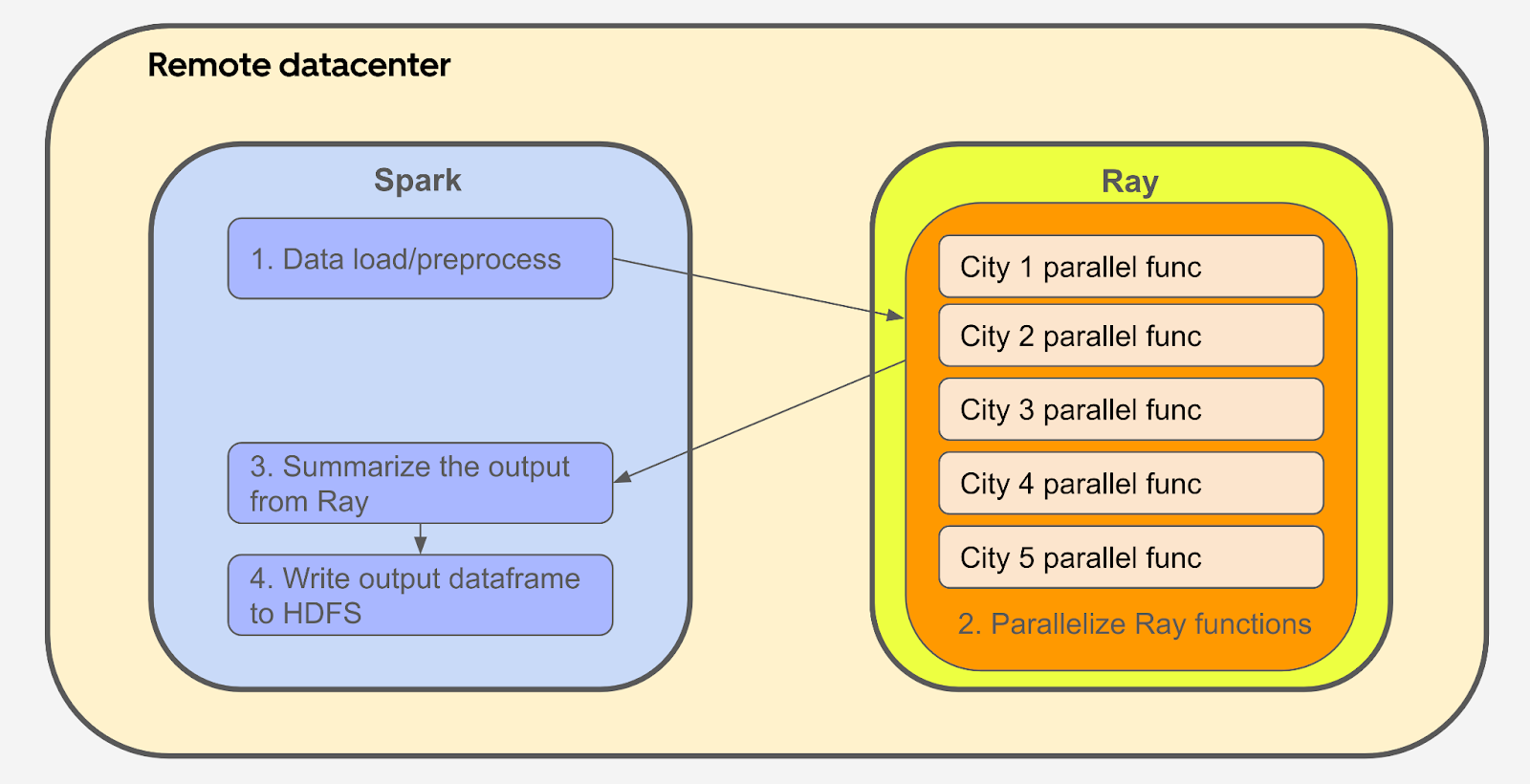
This design can resolve the previous main blockers for our applications. We don’t need to worry about the trade-offs between Spark and Ray because we have both of them. As an external server to Spark, Ray can accept any high-concurrent requests from Spark and return the compute result back to Spark efficiently. Since Ray has a controller inside to arrange the tasks sent to the Ray cluster, we don’t need to implement an orchestrator to monitor the existing tasks or a message queue to arrange all the waiting tasks. The code migration cost is also low because we can still keep most of the PySpark code inside the Spark cluster to be executed. Only the functions suitable for Ray will be moved to the Ray cluster to be executed in parallel.
Following up on this hybrid design, we have also developed several features and tools to help further improve our application speed and also help our engineers improve their developing iteration speed.
Deployment and Launch Time Optimization: Iteration Speed Improvement
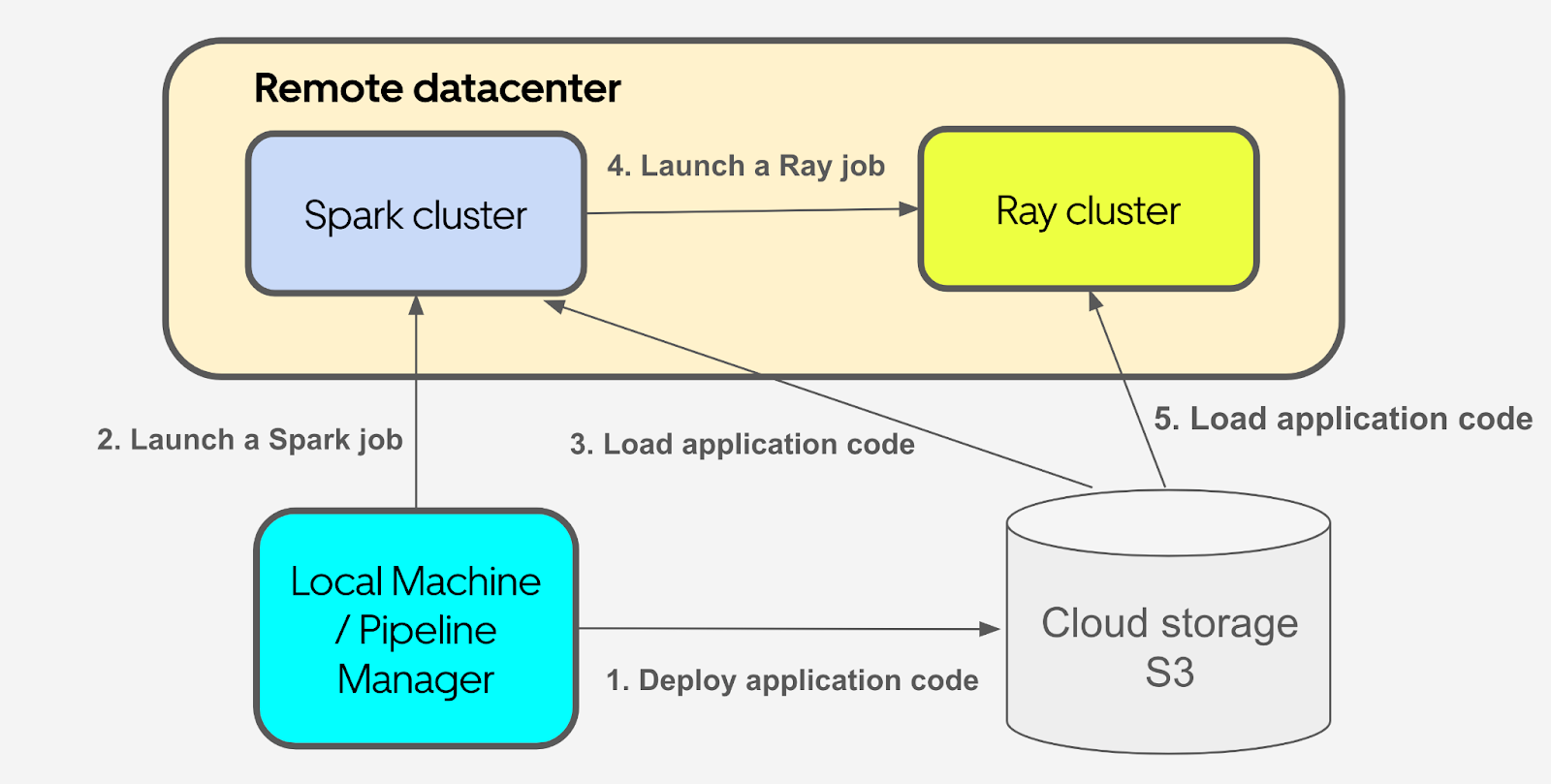
Figure 5 shows how we optimize our job deployment and launch methods for our engineers to improve the development iteration speed. We find that it can be time-consuming for users if they want to do a remote test because they need to build a new Docker image every time, even if they just do a small change to the application code. Usually it takes about 15-20 minutes to build a Docker image. To accelerate this process, we use an object store like Amazon S3® as an intermediate storage layer for application code. Every time a user launches a job, they just need to provide a basic Docker image that only stores the libraries. The changed application code gets deployed in real time, so they don’t need to build a new Docker image every time. As a result, we can control our job deployment and launch time within 2 minutes, which significantly increases our experiment iteration speed.
Data Transmission Speed Optimization
When introducing a Ray cluster as an external cluster, communication between the Spark cluster and Ray cluster can sometimes become an issue. It’s good when the data size is small so that we can send the data quickly and ignore the transmission overhead. However, when the data size is big at the GB or TB level, the transmission time can’t be ignored. If directly sending the data from a Spark cluster to Ray, several factors can affect the transmission rate:
- Internet bandwidth
- Data serialization and deserialization
- Spark driver Pandas converting speed
Since Ray doesn’t support Spark dataframe, Spark driver needs to collect the Spark dataframe from different executors into Spark driver and convert that into a Pandas dataframe. Also, it can potentially cause an out-of-memory issue on Spark driver if the Pandas dataframe is too large.
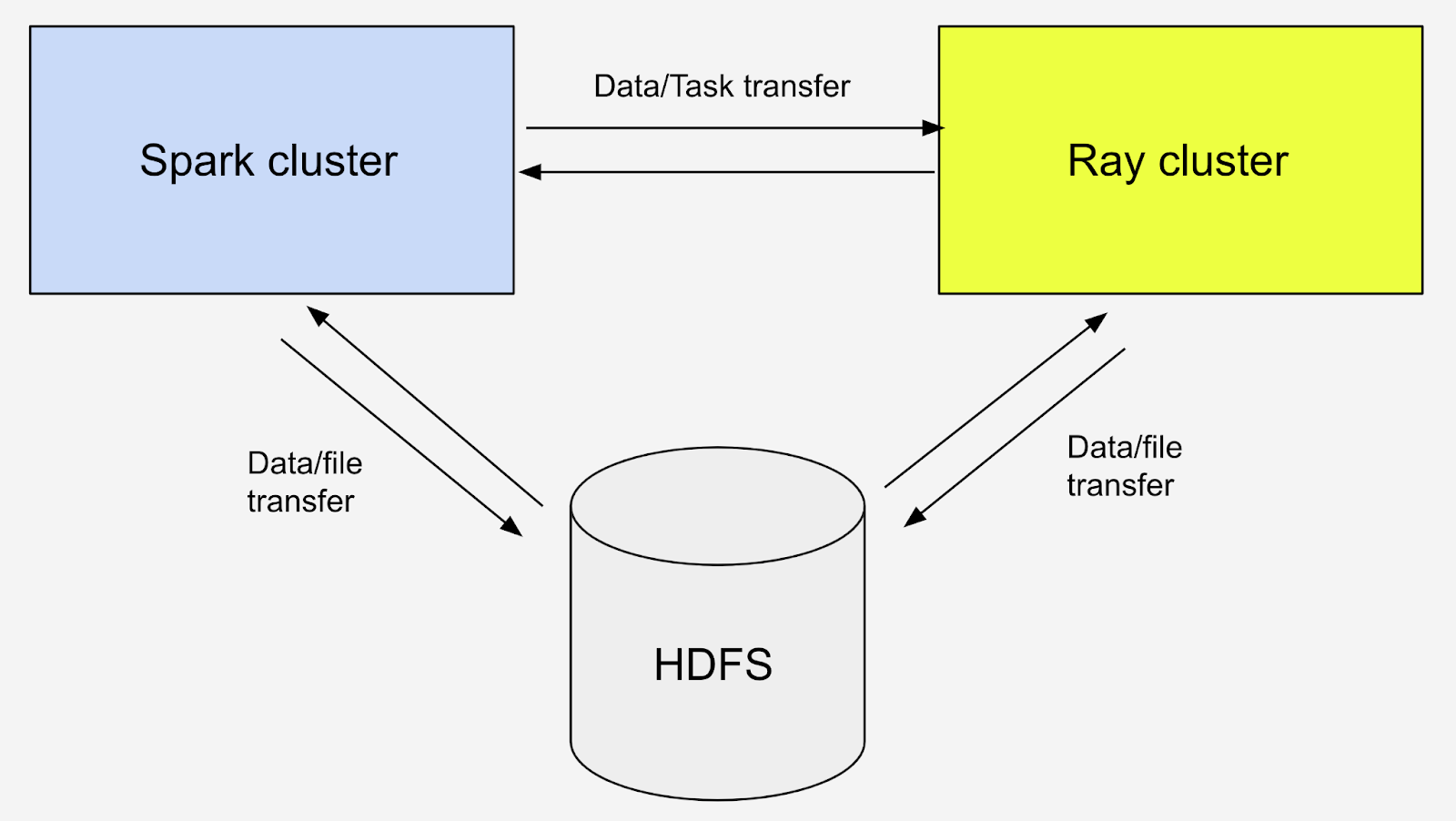
To accelerate data transfer speed and avoid the potential out-of-memory issue, we introduced HDFS as an intermediate storage layer for large dataset transfers. We get a bigger bandwidth when communicating with HDFS. More importantly, we can directly use Spark to write data to HDFS as Parquet files and use Ray’s data API to load the data from HDFS to Ray.
Production and Development Environment-Aligned Notebook
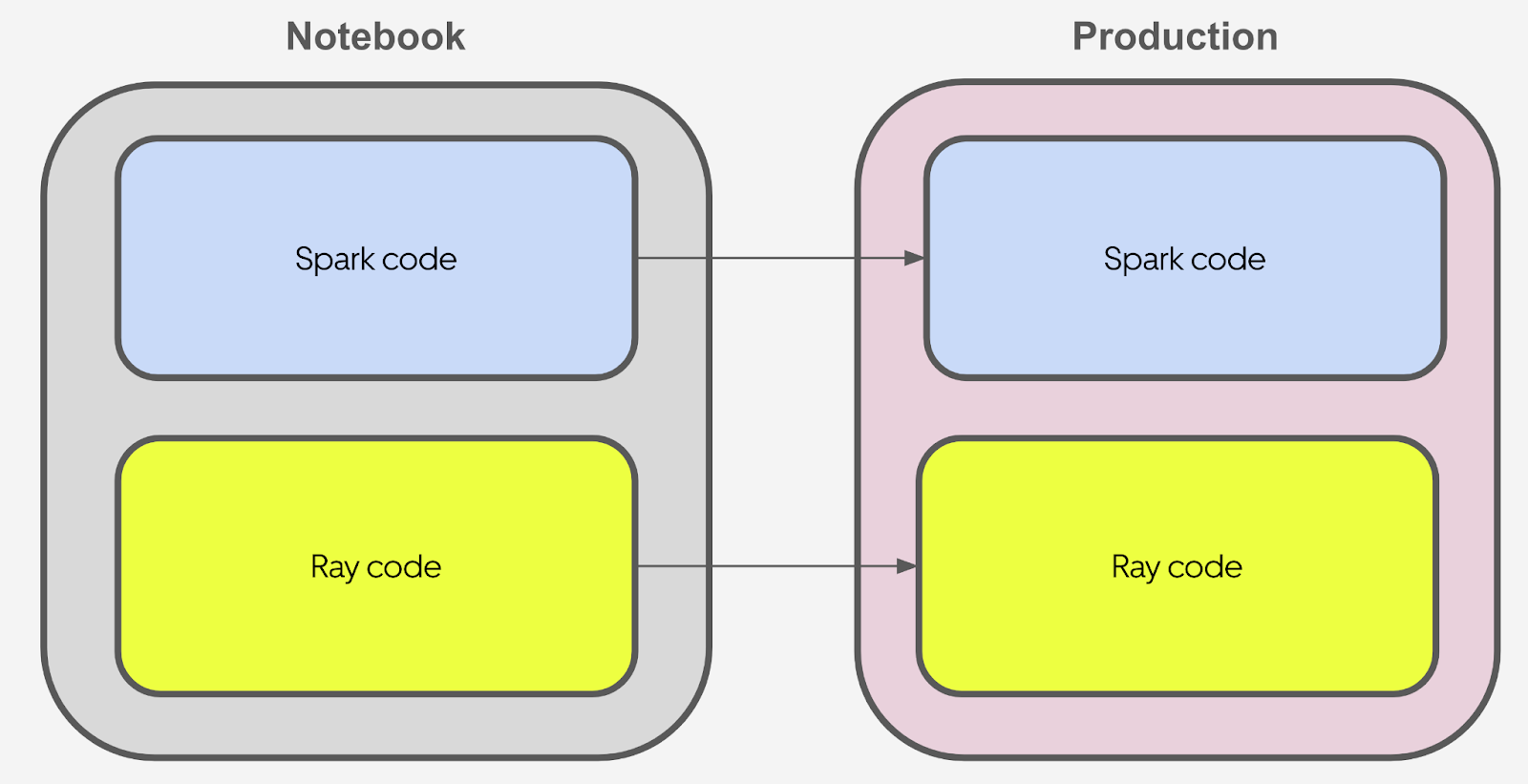
To help developers improve their speed and decrease the workload to convert staging code into production, we designed a notebook that has the same environment setup and standard as the production environment. Our developers can test their code in the notebook. After they make the program run in Notebook, the same code can also run in production. A classic example is our data scientists prefer to write Pandas related code in Notebook. However, previously we didn’t have a good method to accelerate Pandas operations in parallel in production. Sometimes backend engineers need to manually convert these operations into Pyspark to make the program faster. After adopting Ray, data scientists can directly write their Pandas code in the Notebook and backend engineers can easily migrate those Pandas code into production without much conversion.
Use Cases at Uber: ADMM Optimizer
In this section, we describe the implementation of one component within our incentive budget allocation system with Ray, the optimizer that divides a total budget into a vector of allocations for each city-lever.
Because we impose simple, conic constraints on the allocations and impose smoothness conditions on our machine learning models, the ADMM (Alternating Direction Method of Multipliers) is a good fit solving our allocation problem, given its ability to solve non-linear, non-convex, differentiable problems.
One additional advantage of the ADMM algorithm is that it can parallelize well, which allows our system to scale when we add cities or levers.
To solve our optimization problem, we translate it to a slightly different formulation in Figure 8:
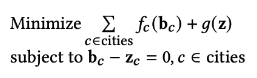
That results in update steps, which we solve to execute the ADMM algorithm in Figure 9:
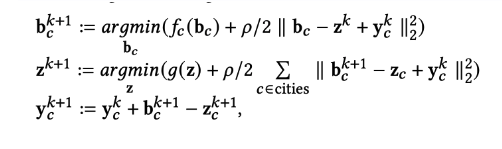
The first step is solved in parallel, using Ray, with a primal-dual interior point algorithm implemented in cvxopt. Rho can be tuned to ensure this problem has a positive semi-definite Hessian. The second step can be solved analytically, and the third step is trivial.
This is the workflow for our ADMM optimization algorithm and how Ray is applied to this architecture in Figure 10. Basically, it’s a loop for recurrent budget allocation ADMM optimization. It can be divided into the following steps:
Step 1: Initialize the problem.
Step 2: Optimization in a for loop.
- Solve the individual city problems for each week in parallel [Ray].
- Summarize the city optimization result [Spark].
- Update cross-city constraint variables [Spark].
- Update the slack variables. [Spark].
- Check convergence criteria [Spark].
Step 3: Record optimal allocation values, metadata, and convergence variables.
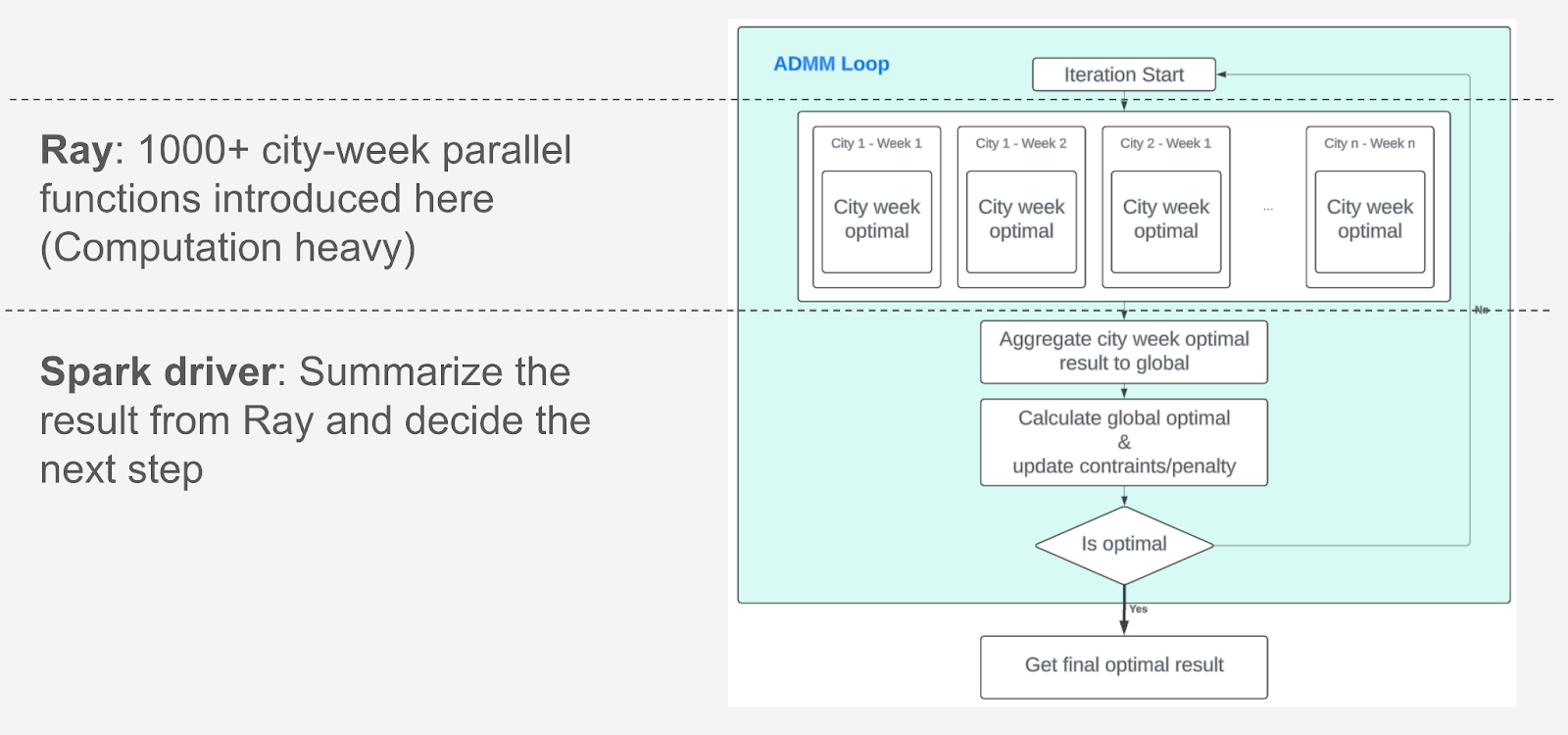
Each city week optimization function with ADMM is very lightweight, which takes about 1-2 seconds to finish. However, due to the large volume of high-concurrent optimization functions, the optimization speed becomes a bottleneck for our optimizer. After applying Ray for the city parallel optimization computations, we’ve achieved about a 40-time improvement for our budget allocation optimizer.
KubeRay Back End Support from Uber Michelangelo
A good Ray application should have a good parallelism strategy at the application level and a solid Ray back end to support all these parallel computations. In this section, we describe how the Michelangelo (Uber’s AI platform) team built a reliable Ray back end for all the client teams to use in Uber.
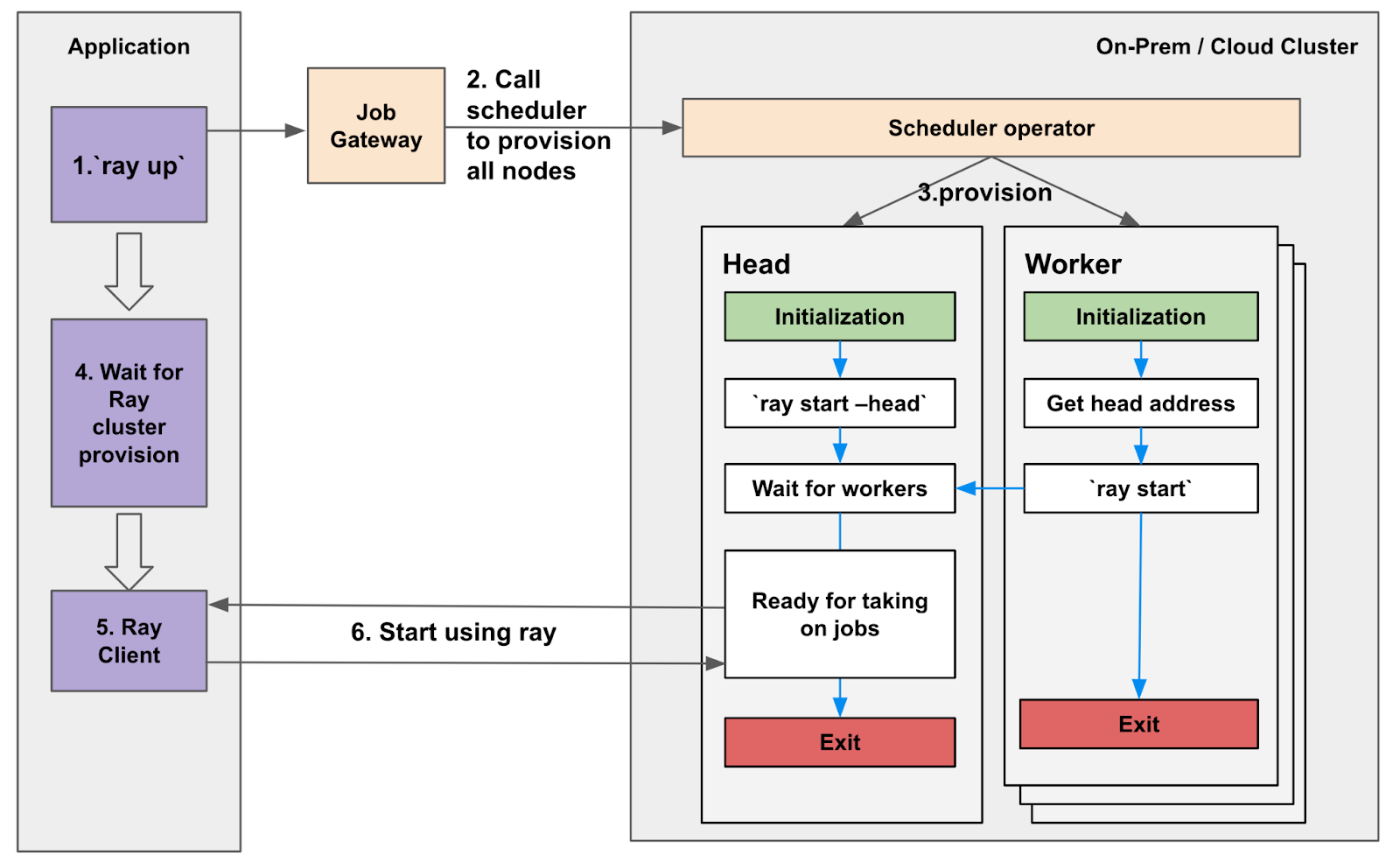
Figure 11 shows how the Ray cluster is provisioned in the back end. When Ray clusters are initiated upon job submission, resources for the Ray cluster are provisioned dynamically based on the job’s requirements, such as the number of nodes, CPU, GPU, and memory specifications. Once the Ray cluster is provisioned, the Ray head node is first established, then it discovers and connects all of Ray’s worker nodes. The application connects to the Ray head node, which coordinates the distributed execution of Ray tasks across worker nodes. The connection details (IP address and port) for the Ray head node are automatically discovered and provided to the application, allowing seamless execution without manual intervention. After job completion, the application sends a request to the compute layer and releases the allocated resources back to the pool, ensuring efficient utilization across the platform.
We also investigated and adopted other modules outside of Ray’s Core service. Ray integrates well with a variety of open-source frameworks and libraries in the ecosystem, and makes it easier to experiment with new techniques from industry. We integrated Horovod with Ray, adopted Ray XGBoost, Ray Data, Heterogeneous training cluster, and Ray Tune, which made Ray the common layer in Michelangelo for training and fine tuning XGB, DL, and LLM models.
In 2023, we modernized our resource cluster from Peloton (old resource scheduler) to a new Kubernetes® based Michelangelo Job Controller service, and uplevel the resource management experience for both CPU and GPU training jobs.
Despite infrastructure constraints across on-premises and cloud providers, the service abstracts compute cluster and hardware complexities from the user, and ensures a dynamic resource selection, high scalability and flexibility, and more efficient resource scheduling, which makes it well-suited for diverse user needs in Uber. Benefits include:
- Automated Resource Allocation: The design uses CRDs to define resource pools, automatically assigning jobs to appropriate pools based on organizational hierarchy, cluster size, and HW type requirements. This eliminates manual resource allocation, reducing contention and oversubscription.
- Dynamic Scheduling: A federated scheduler intelligently matches jobs to clusters, considering factors like resource availability, affinities, and job priorities. This ensures optimal resource usage and prevents scheduling failures.
- Cluster Health Monitoring: Continuous monitoring of cluster health and maintaining an up-to-date resource snapshot ensures jobs are only scheduled on healthy clusters with available resources.
- Simplified User Experience: Users don’t need to manage the underlying infrastructure—the system abstracts complexities, allowing them to focus on their workloads while the system handles resource management.
- Scalability and Extensibility: The design supports new hardware, cloud bursting, and is compatible with emerging technologies, ensuring it can scale and adapt to future needs while maintaining efficient resource management.
Later in early 2024, we successfully migrated all existing XGB and deep learning training jobs to the Michelangelo Job controller. With the benefits from the job controller, we keep unblocking more use cases, like large language model fine-tuning and optimization applications.
Conclusion
Ray has become a critical tool in Uber for machine learning and everything that has the potential to be parallelized, like optimization algorithms, evaluation algorithms, and more. Ray is now widely used at Uber, starting with the Uber Michelangelo team as a fundamental back end and applied to different application teams like the Marketplace Investment team to do budget allocation optimization for Uber. By using Ray in Uber applications, we’ve achieved a huge performance improvement and provided a more friendly user experience to our data analysts and developers.
Acknowledgments
Thanks to all the members from the Uber Marketplace Investment team and the Uber Michelangelo team for the great effort. Thanks to Ryan Clark for actively reviewing the blog and giving valuable feedback.
Cover Photo Attribution: ”Fast Train” by Sander van der Wel is licensed under CC BY-SA 2.0.
Amazon Web Services, AWS, Amazon S3, and the Powered by AWS logo are trademarks of Amazon.com, Inc. or its affiliates.
Apache®, Apache Spark™, HDFS, and the star logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Docker® is a registered trademark of Docker, Inc in the United States and/or other countries. No endorsement by Docker, Inc is implied by the use of this mark.
Kubernetes®, etcd®, and Kubernetes® logo are registered trademarks of the Linux Foundation in the United States and/or other countries. No endorsement by The Linux Foundation is implied by the use of these marks.
Python® and the Python logos are trademarks or registered trademarks of the Python Software Foundation.
Peng Zhang
Engineering Manager
Peng Zhang is an Engineering Manager on the AI Platform team at Uber. He supports the teams dedicated to developing training frameworks, managing GPU-based resources, and enhancing ML efficiency for training classical, deep learning, and generative AI models
Kaichen Wei
Kaichen Wei is a Senior Software Engineer on Uber’s Marketplace Investment team. He’s working on modeling infrastructure for the team, mainly responsible for distributed computation, model training, and serving on GPU and ML infra.
Matt Walker
Matt Walker is a Senior Staff ML Engineer in Uber’s Marketplace organization. Before getting his start in ML, he earned his PhD in physics.