Lucene: Uber’s Search Platform Version Upgrade
Introduction
In the dynamic ecosystem of Uber, search functionality serves as the backbone for numerous critical operations, ranging from matching riders to drivers, to geo search functionalities within Uber ride apps, to facilitating seamless exploration of restaurants and dishes in Uber Eats. The reliance on search is paramount, given the diverse and extensive nature of Uber’s service offerings.
The Search Platform team at Uber has built an in-house search engine on top of Apache Lucene, with the primary objective of establishing a unified search infrastructure across all business verticals. Since its inception in 2019, the service has operated on Lucene version 7.5.0, which is two major versions and nearly four years behind the latest iteration.
Over the past four years, we’ve made significant strides in centralizing all search functions under one platform, catering to over 30 internal use cases. However, it’s clear that keeping up with the latest advancements is crucial. Lucene’s version 9+ introduces powerful semantic search capabilities through HNSW graphs, offering the potential for enhanced search accuracy and efficiency.
Last year, we made the decision to upgrade from version 7.5.0 to 9.4.2. Initially, we contemplated upgrading one major version at a time. However, after careful assessment of the required efforts and considering the significant demand from customers for semantic search support, it became evident that a direct leap to two major version upgrades was the most practical approach
Architecture Overview of Search Platform
The search platform at Uber is structured around a robust architecture that encompasses both the serving layer (read path) and the ingestion layer (write path), with additional components for offline processing.
Serving Layer (Read Path):
The serving layer of the search platform is responsible for handling user queries and retrieving relevant information from the Lucene indices. This layer comprises two key components:
- Routing Service: The routing service acts as a gateway for incoming user queries, directing them to the appropriate search nodes for processing. It manages load balancing and ensures efficient distribution of query traffic across the search nodes.
- Search Service: These nodes are responsible for executing user queries against the Lucene indices. They utilize Lucene’s powerful indexing and querying capabilities to retrieve relevant results in real time.
Ingestion Layer (Write Path):
The ingestion layer handles the process of updating the Lucene indices in response to changes in the underlying data. It consists of:
- Ingestion Service: Apache Flink is utilized as the ingestion service, responsible for processing real-time updates and propagating them to the Lucene indices. It ensures that the search indices remain up-to-date with the latest changes in the data.
Offline Processing:
In addition to real-time updates, the search platform incorporates offline processing for building and rebuilding the Lucene indices. This offline component is facilitated by:
- Offline Jobs: Apache Spark jobs are employed for offline processing, enabling the bulk construction and reconstruction of Lucene indices. These jobs leverage Spark’s distributed computing capabilities to efficiently process large volumes of data and generate the necessary index structures.
Version Upgrade Considerations
In the context of upgrading the Lucene version, all components of the search platform are involved, either directly or indirectly, due to their dependencies on Lucene libraries. Therefore, a comprehensive upgrade strategy must account for the interdependencies between these components and ensure seamless compatibility with the upgraded Lucene version.
Binary and Index Compatibility
Lucene only guarantees compatibility one version ahead for both binary and index formats. This means that Lucene 7 indexes are incompatible with Lucene 9, and vice versa. Consequently, upgrading Lucene versions requires careful consideration and planning to ensure a seamless transition without data loss or corruption. This also necessitated that build/deploy and rollout systems ensured that incompatible code or index was not rolled out.
Dependent Software Stack Upgrade
Upgrading Lucene also necessitates upgrading other components in the software stack, such as Java, Spark, and Scala. Managing these dependencies and ensuring compatibility across the entire stack pose a significant challenge, particularly in a complex and interconnected environment like Uber’s search platform.
Upgrading to Lucene 9 was a significant overhaul of our software ecosystem, requiring adjustments across various layers. This process began by raising the minimum supported Java version, as Lucene 9 uses the Java Module System introduced in Java 9. This Lucene 9 would not run on Java 8 and required us to move our services to Java 11. This transition to Java 11 required a concurrent upgrade of our Spark framework to Spark 3.0, as Spark 2 and Java 11 are not compatible. This upgrade also impacts our index-building processes, where Spark plays a crucial role. Furthermore, Spark 3 introduces dependencies on Scala version 2.12, mandating alignment with all associated dependencies and jars to maintain seamless interoperability.
Similarly, on the live ingestion side we had Flink jobs earlier running on Java 8 and we upgraded the ingestion pipeline to run on Java 11 as well. Refer to Figure 3 for understanding the dependencies.
We decoupled the upgrade in phases by first upgrading the Java, Scala, Spark, and Flink versions of offline and online services and then the actual Lucene library upgrade. This helped reduce the blast radius and limit scope to a defined changeset.
Upgrade Across Monorepo
Uber organizes all of its code in monorepo, consolidating all codebases for different languages into a single repository. While this approach offers benefits in terms of code sharing and version control, it introduces challenges in managing dependencies across diverse projects.
For the Lucene version upgrade, our focus was to upgrade it across Java monorepo. Additionally, with the growing demand for vector similarity, fueled by the rise of large language models, we are actively developing semantic search capabilities. This development is taking place in a separate branch. It was crucial to maintain synchronization across all these changes.
With monorepo, one of the major challenges is version control of different dependencies. FA typical build pipeline for a micro-repo-based setup would look like the following:
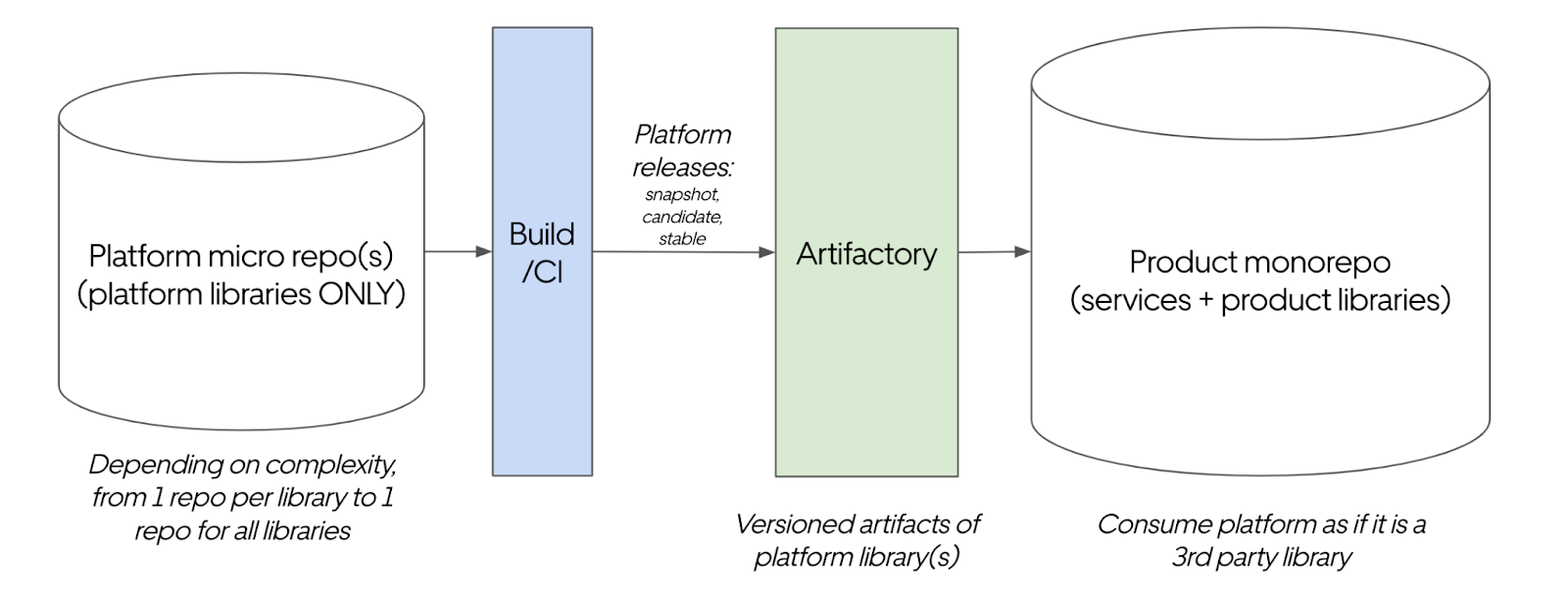
For example, as shown in Figure 4 for a typical micro-repo-based build pipeline, we can keep only the different dependencies as per need on a feature branch, and switch to using this branch in different build pipelines.
Another peculiar characteristic of monorepo is that with large diffs, Git merge becomes untenable. Hence, Uber’s monorepo uses Git rebase workflows for landing our diffs (code changes).
To solve this, all the upgrade related code changes were kept in a branch. We set up an auto-rebase pipeline. To ensure sanity of build after every rebase, we would run all the downstream builds and unit tests.
Diverse Query Patterns
We support numerous critical business flows, each with distinct query patterns and utilization of Lucene’s features. Ensuring performance and functional parity across different query types and use cases is paramount. The upgrade process must account for these variations to maintain the platform’s reliability and responsiveness.
The Upgrade Strategy
We made extensive changes in a separate feature branch: the “Lucene 9 branch,” which affected over 400+ files in the monorepo. These changes weren’t compatible with the current codebase in the monorepo. As a result, we decided to implement a phased rollout strategy for the Lucene update.
Since rolling out to 30+ use cases of different business criticality (external and internal) is a non-trivial and long-running effort, the branch had to be rebased with main to ensure it was regularly updated. The upgrade was done in a phased manner by first rolling it out to low-tier internal use cases and gradually moving up the tier. The entire upgrade took close to 6 months as it involved rigorous code reviews, validations, close collaborations with customer teams, and tiered rollout and branch merge.
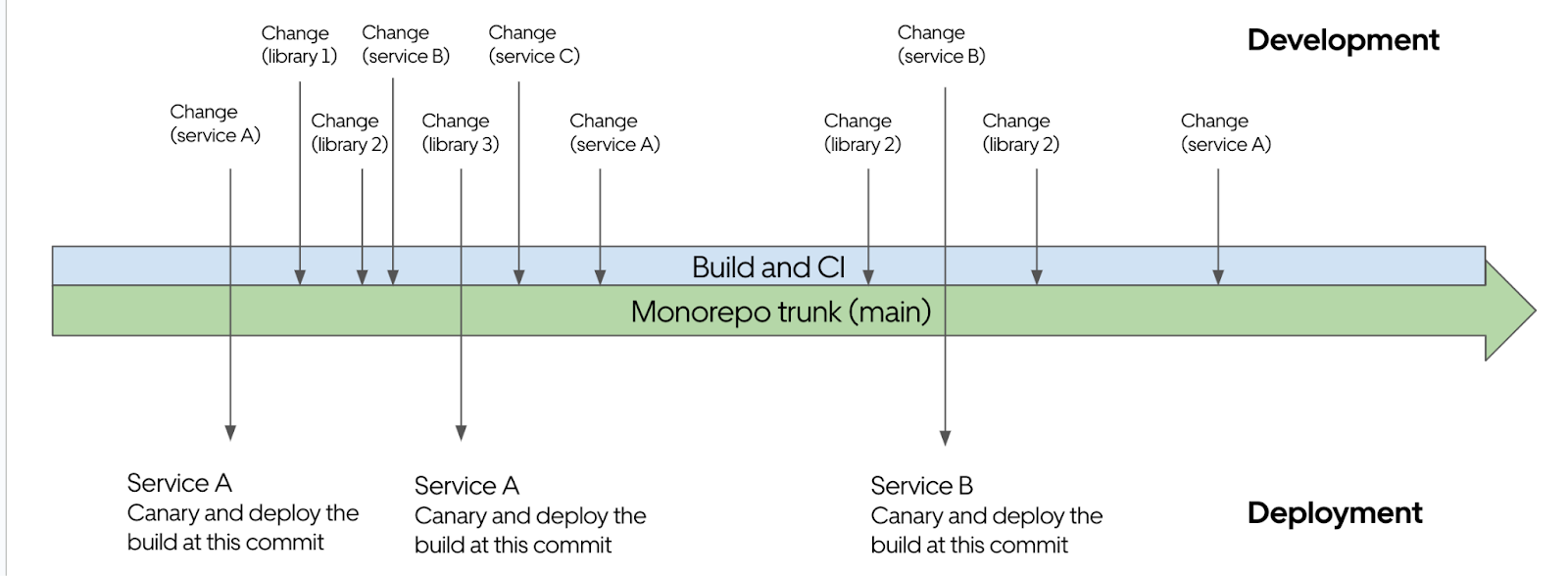
We built an automation around the branch maintenance pipeline, which handled both regular rebasing of the lucene 9 branch with the main branch and the feature branch sanity validation. Figure 6 shows the automated pipeline overview. It consists of two crons:
- Rebase Cron: This rebases Lucene 9 branch with the main branch and notifies developers through slack and email in case of any conflict encountered during rebasing.
- Deploy Cron : This cron periodically deploys the binary from the Lucene 9 branch (rebased with main) to Search nodes. It consists of the following sub-steps:
- Creates binary from the rebased branch
- Identifies the instances that opted for continuous automated rollouts. (configured in our system)
- Deploys the binary to the search service nodes that were subjected to production-shadowed traffic to validate branch sanity (functional correctness and performance regressions). More on it in the validation section.
Doing this significantly reduced developer time and effort. Prior to this, it was a lot of grunt work with multiple manual and monotonous rebases and builds, which was becoming operation-heavy. From the time we started validating and rolling out the feature branch gradually to the use cases until we merged this branch with the main in production, this automation pipeline ran about 700 times, automatically pulling in new changes. Only ~10% of the time, a developer had to manually fix conflicts. Every time a conflict arose we promptly fixed it. By implementing this straightforward yet highly effective approach, we ensured the maintenance of critical branches throughout the Lucene migration process.
Validation
In order to gain confidence with extensive changes done within the monorepo and to uncover any unknowns, we built a robust validation framework. Figure 7 illustrates the search validation framework. This framework is currently being utilized for many production releases, and is designed to be generic and extensible.
Each client utilizing our search service has separate infra modules each for real-time updates, Lucene query processing, and request processing. Each of these modules run independently with different versions of code. As our changes touched all of these modules, hence the need for validating each module arose.
We created a parallel setup for these infra modules each running Lucene 9 changes.
Read Flow Validation: Routing service is the entry point of any search requests. It aggregates responses from all shards and returns to the client. This service sampled some of the read requests along with their responses, compressed them and pushed them to the queue, which were then consumed by the validator framework.
Validation framework consumed the sampled requests and utilized parallel setup with Lucene 9 changes running across modules and hit the same request to the Lucene 9 setup. Responses from both production and Lucene 9 setup were matched. Any mismatch found was published via metrics and was alerted to the team when threshold was breached.
Robust metrics and alerts visibility to detect any discrepancies between the production environment and the Lucene 9 parallel setup significantly helped in a smooth Lucene migration process.
Write Flow Validation: Similar to read validation, sampled real-time updates events for selected documents were validated against both the index versions for sanity.
In certain scenarios, real-time updates reflected in production documents while the same was being processed by the parallel Lucene 9 setup and vice versa, which led to discrepant results during the read validation.
To addreess such scenarios, we implemented a retry mechanism, taking in account the QPS for production. Response matching percentage of 95+% was enough to give us the confidence to move ahead with the rollout.
Rollout via Blue Green Setup
We got extra capacity temporarily to follow the standard blue-green setup and rollout. This ensured quick mitigation in case of any issue being encountered. Figure 8 demonstrated how a gradual percentage rollout was done. We have our custom routing logic implemented at the routing service, which distributes the request across various instances.
Performance Wins
Enhanced Efficiency With CPU Utilization Reduction
Our search requests are primarily CPU-intensive, so achieving a reduction in CPU utilization marks a significant victory for us. This decrease not only signifies reduced infrastructure costs but also allowed us to scale down our clusters by decreasing the number of machines required for several customers.
Improved Latency
Search platform serves many critical, real-time business flows of Uber. Any reduction in search latency translates to faster response time for our users. Customers have experienced notable improvements in latency, with a maximum reduction of 30% at the 95th percentile.
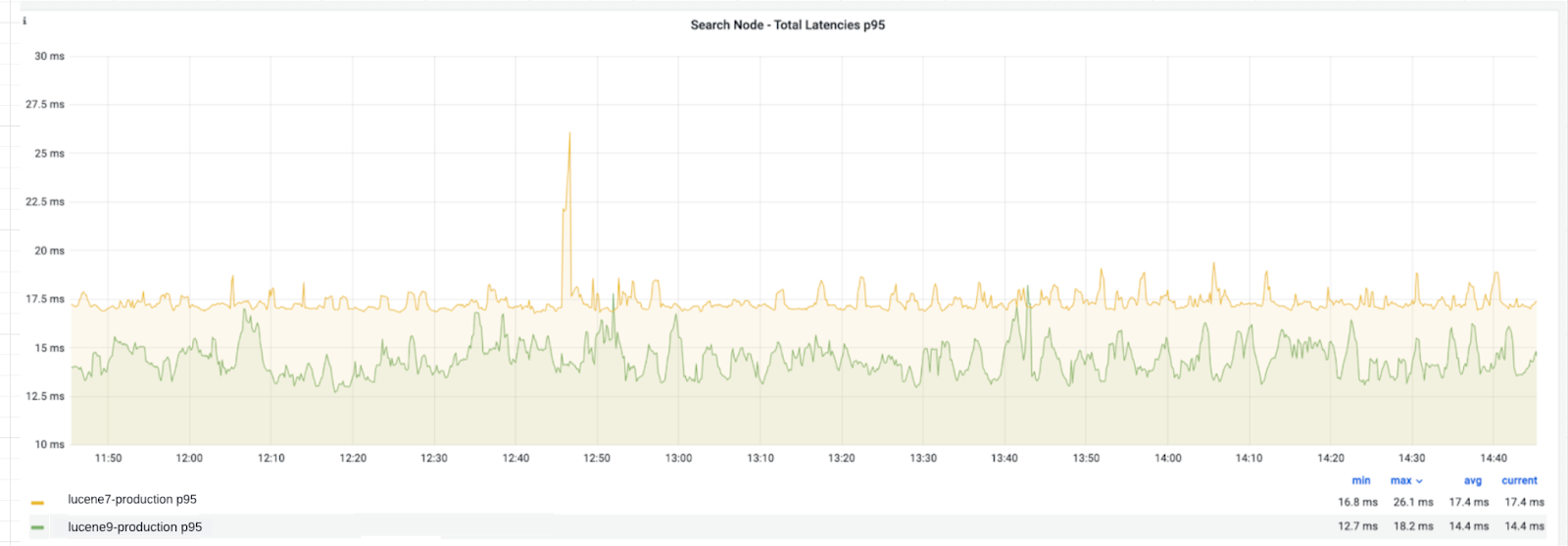
Indexing Improvements
Additionally, about 10% reduction was observed in index sizes, alongside faster index build times.
Key Learnings
Automation and Validation Tooling
This is an important investment for sustainable technology upgrade. Our search architecture is a complex distributed system using both batch and real-time data. Investing in tools and validation services that validate across different layers proved to be very useful when migrating >30 customers. This also helps in easier future migrations.
Regular Version Upgrades
A significant hurdle during the upgrade was the incompatibility of indexes and binaries, stemming from the leap across two major versions. Regularly staying updated with the latest releases minimizes the operational effort required for deployment and validation. Additionally, this practice simplifies troubleshooting, as it reduces the volume of changes that need to be reviewed when an issue arises.
Active/Passive Setup
Search architecture is complex and business-critical. There are several subcomponents, so active/passive setup is critical to allow fast rollout and immediate mitigation. For each customer upgrade, we kept a passive setup, running on the older versions in sync with production data. This allowed quick fallback to mitigate any issue that came in production queries.
Tiered Rollout and Coordination
Executing a tiered rollout strategy is crucial for validating the Lucene version upgrade while minimizing potential disruptions to critical business flows. We updated the customers in a staggered manner with higher tier (i.e., less business-critical) use cases upgraded first and then gradually rolling out to higher-tier use cases.
Upgrading Uber’s search platform to Lucene 9.4.2 was a challenging but rewarding journey. The upgrade not only unlocked powerful new features like semantic search but also led to significant performance gains, including reduced CPU utilization and improved query latency.
Anand Kotriwal
Anand Kotriwal is a Senior Software Engineer on the Search Platform team at Uber. His work is focused on developing features that improve user experience, and enhancing search engine efficiency and performance.
Charu Jain
Charu Jain is an Engineering Manager for Uber’s Search Platform for over two years. She has been working at Uber Bangalore for almost seven years and has worked across multiple teams.
Yupeng Fu
Yupeng Fu is a Principal Software Engineer on Uber’s SSD (Storage, Search, and Data) team, building scalable, reliable, and performant online data platforms. Yupeng is a maintainer of the OpenSearch project and a member of the OpenSearch Software Foundation TSC (Technical Steering Committee).
Aparajita Pandey
Aparajita Pandey is a Software Developer in Uber’s Search Platform Team . Her work at Uber focuses on enhancing search experience for users