Ensuring Precision and Integrity: A Deep Dive into Uber’s Accounting Data Testing Strategies
April 18, 2024 / Global
Introduction
Uber operates multiple lines of business across diverse global regions. Financial Accounting Services (FAS) Platform (detailed architecture) is responsible for financial accounting across these global regions and is designed to follow the tenets below:
- Compliance
- Auditability
- Accuracy
- Scalability
- Analytics
To maintain these tenets, FAS has built robust testing, monitoring, and alerting processes. This encompasses system configuration, business accounting, and external financial report generation.
Challenges
The financial accounting services platform at Uber operates at an internet scale– approximately 1.5 billion journal entries (JEs) per day and 120 million transactions per day via ETL and data processing at a throughput of 2,500 queries per second [on average]. Standard off-the-shelf accounting systems cannot support such scale and scope of transactions of our growing platform. Additionally, we manage data from over 25 different services for accounting purposes. To handle data at this scale, our engineering systems are designed to process data both at the event level and in a batch mode. As data flows through multiple components in the architecture, there is a need to ensure that all the components are designed to embrace the tenets defined above.
The platform processed roughly $120+ billion in annual gross bookings and settlements in 2023. It operates at a transaction scale (~80 billion financial microtransactions per year) that is 10 times the trip scale and currently offers 99.6% of transactions with automated revenue computation with 99.99% completeness, accuracy guarantee, and auditability. We onboarded 600+ business changes to support the scaling of the business in 2023. The platform processes big data and stores petabytes of data in Schemaless and Apache HiveTM.
The accounting process has multiple steps and validations are required at every step to adhere to the tenets. Here are the various steps where validations are performed:
- Business Requirement Validation
- Accounting Onboarding
- Accounting Execution
- Report Generation
To uphold our established principles, we implement checks and balances throughout the stages of financial accounting services:
- Requirements Signoff
- Regression Testing
- Integration Testing
- UAT Validations
- Ledger Validations
- Transaction-Level Validations
- Shadow Validations
- Deployments
- Canary
- Health Checks
- Auditor Checks
- Completeness Checks
- Alerting/Monitoring
- Report Generation
Validations Life Cycle of Accounting Processes
As the data flows through various components of the Fintech Systems, there are checks and balances at every stage so that the systems and processes adhere to the tenets.
Requirements Signoff
Based on the Business Models operating in various countries and the expectations of the local teams, the requirements are provided and tracked. Accounting requirements are provided in accordance with Generally Accepted Accounting Principles (GAAP). The requirements are then onboarded into our accounting systems. Fintech Systems at Uber have internal tools to validate the requirements, which perform 15+ automated checks to validate the expected output.
Regression Testing
Unit Testing
Unit tests in Uber’s Financial Services are critical for ensuring the accuracy, security, and reliability of our applications. These tests involve isolating small sections of code and verifying the functions as intended. At Uber, we strive to identify and rectify errors early by rigorously testing each unit for correct operation and ensuring overall services–from transaction processing to financial reporting–run smoothly and securely.
Regression – Kaptres
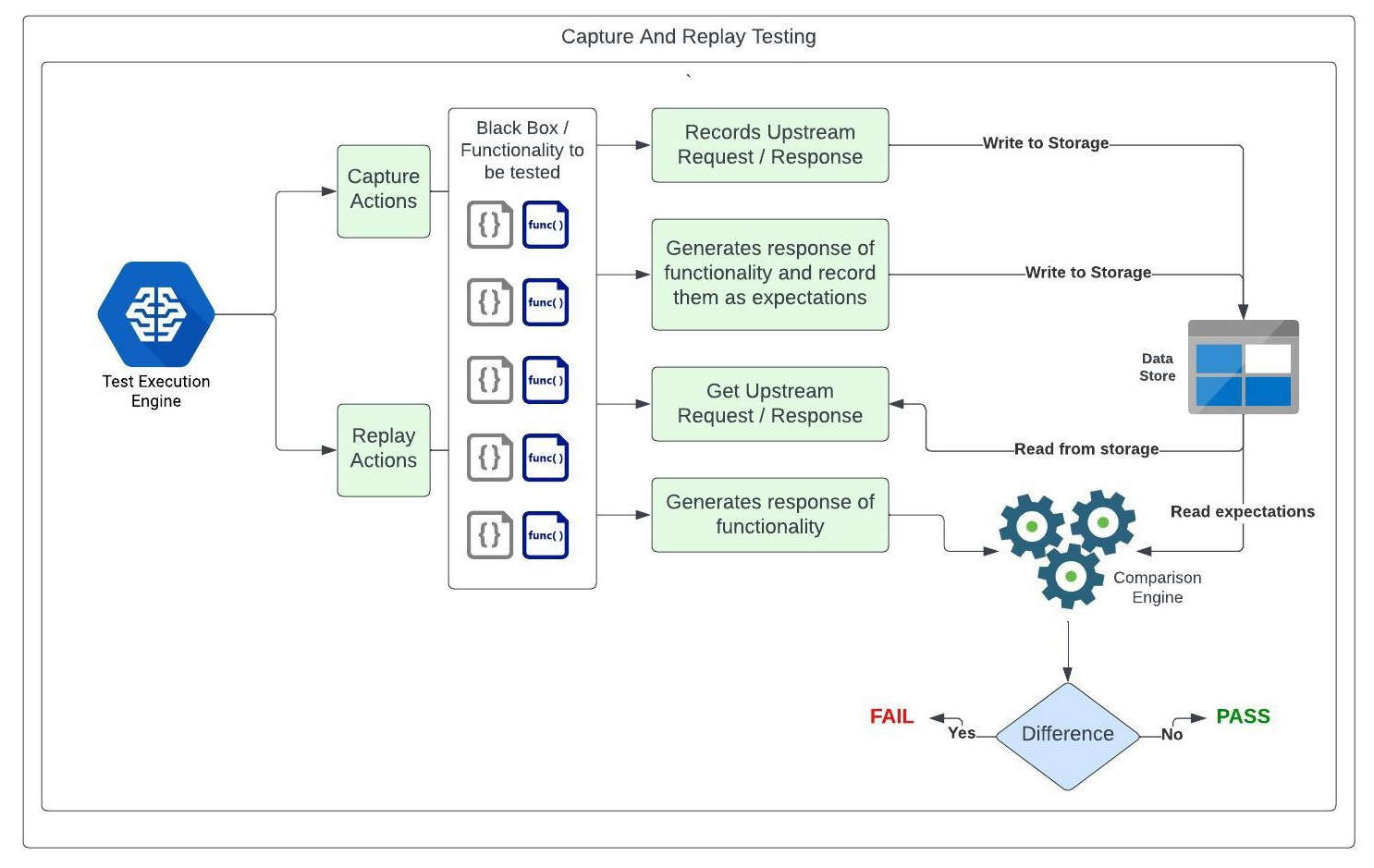
Kaptre (Capture — Replay) is a capture and replay testing tool primarily employed for functional and regression testing purposes. Here’s a breakdown of how our financial systems use its key components:
Test Case: For any accounting change, at least one new Kaptre test is added to the test suite so that all the use cases are tested in successive runs. Each test case includes input (same as used for UAT), expectations, and assertions.
Capture Mode: When adding a test, we operate in “capture mode.” This mode executes the accounting process for the newly added test and captures dependencies needed to re-execute in an offline mode, like API request/responses from upstreams and expected accounting journal entries (JElines).
Replay Mode: The subsequent test runs involve running the Kaptre regression test suite in the replay mode. This mode creates the new output using the latest code/config version and the assertions compare these with the captured expectations. A test failure is reported if the assertion fails.
Change Triggers for Captured Responses: Captured responses change with alterations in upstream systems, new field additions in financial transactions, or anticipated accounting changes. These tests can be updated using the above capture mode after validations.
This approach ensures that regression tests accurately reflect the system’s behavior during capture mode and subsequently verifies it against expected outcomes in successive test runs. The design allows for adaptability to changes in upstreams, fintech systems, and anticipated accounting modifications while maintaining the integrity of the testing process and reducing the risk of human error during the testing process.
SLATE (Short-Lived Application Testing Environment)
Testing in a short-lived application environment (a.k.a. SLATE) before deploying to production is a crucial step in Uber’s software development lifecycle. SLATE testing helps us identify and address issues early on and reduces the risk of introducing defects/problems into the production environment. Various types of testing are performed in SLATE, including integration, performance, and security testing. The primary purpose of this testing is to run the application in a production-like environment, identify and detect issues (like runtime errors) early in the development cycle, and prevent the propagation of defects to higher environments.
Find more details in the Slate Uber Eng Blog.
In summary, testing in short-lived application environments is a best practice that contributes to the overall quality, reliability, and security of our services before they are deployed to production.
Integration Testing
Financial Accounting Services at Uber engages with numerous upstream systems (30+) to enrich trip details essential for generating accounting transactions. Integration testing is crucial for seamless communication between financial systems and upstream components, identifying interface issues and enabling early risk mitigation.
However, a notable challenge with integration testing lies in determining completeness. Unlike unit tests that have a clear metric for code coverage, integration tests lack insights into the scenarios to cover, and there is no established metric for measuring integration test coverage. This gap results in dependent teams not automatically being informed about new scenarios being launched, and there is a lack of metrics to comprehend test coverage for all scenarios.
To address this, we have developed an internal tool that automates the detection, notification, and acknowledgment of the readiness of all dependent systems. This tool aims to ensure a defect-free launch and provides a mechanism to measure integration test coverage.
This becomes particularly critical within revenue systems, positioned at the conclusion of the data flow and interacting with multiple services. Unanticipated launches in this context pose the risk of disrupting accounting processes. For instance, a fare launch, lacking proper communication, might be routed to a dead letter queue (DLQ), leading to improper accounting due to insufficient onboarding in the revenue system.
UAT Validations
User Acceptance Testing (UAT) is a mandatory step in Uber’s financial systems development, where the accounting team rigorously validates financial reports for accuracy. We streamlined this process with comprehensive validation of aggregated and transaction level ledgers through automated testing covering positive and negative scenarios. This ensures integrity of balance sheets, income statements, and other key financial statements. This meticulous approach guarantees seamless integration of updates and patches without disrupting existing functionalities, with over 15 quality checks before signoff.
Once accounting configurations are set up as per requirements, then they undergo validation by the Accounting Team, culminating in official sign-off indicating approval and attesting to accuracy and compliance. Business Rule configuration changes adhere to a stringent protocol, requiring explicit authorization from key accounting stakeholders before merging into the main system. Uber utilizes automated Buildkite jobs to ensure integrity and efficiency, systematically checking for necessary approvals when differences in the codebase are identified. This automation reinforces the rigor of the approval process.
In instances where changes contradict the established protocols or bypass the mandatory approvals, an automated flag is immediately raised for a thorough review. This safeguard is essential in maintaining the system’s integrity and compliance.
Uber’s financial systems employ two primary types of validations to ensure the utmost accuracy and reliability:
- Sample Validations
- Ledger Validations
Sample Validations
Validations are performed on a selected set of sample orders, which are chosen to be representative of the scenarios of the orders in the production environment. These validations are typically adequate while making incremental changes to the financial systems.

Ledger Validations
For changes that impact a significant number of use cases either at the country or business level, we also perform ledger validations to get completeness assurances. These validations provide additional assurances at aggregate levels over a specific period of time before we implement these changes in production.

Both validation types are integral to Uber’s commitment to maintaining the highest standards of financial accuracy and regulatory compliance. They work in tandem to ensure that the financial system remains robust, reliable, and reflective of the true financial position of the company.
Shadow Validations
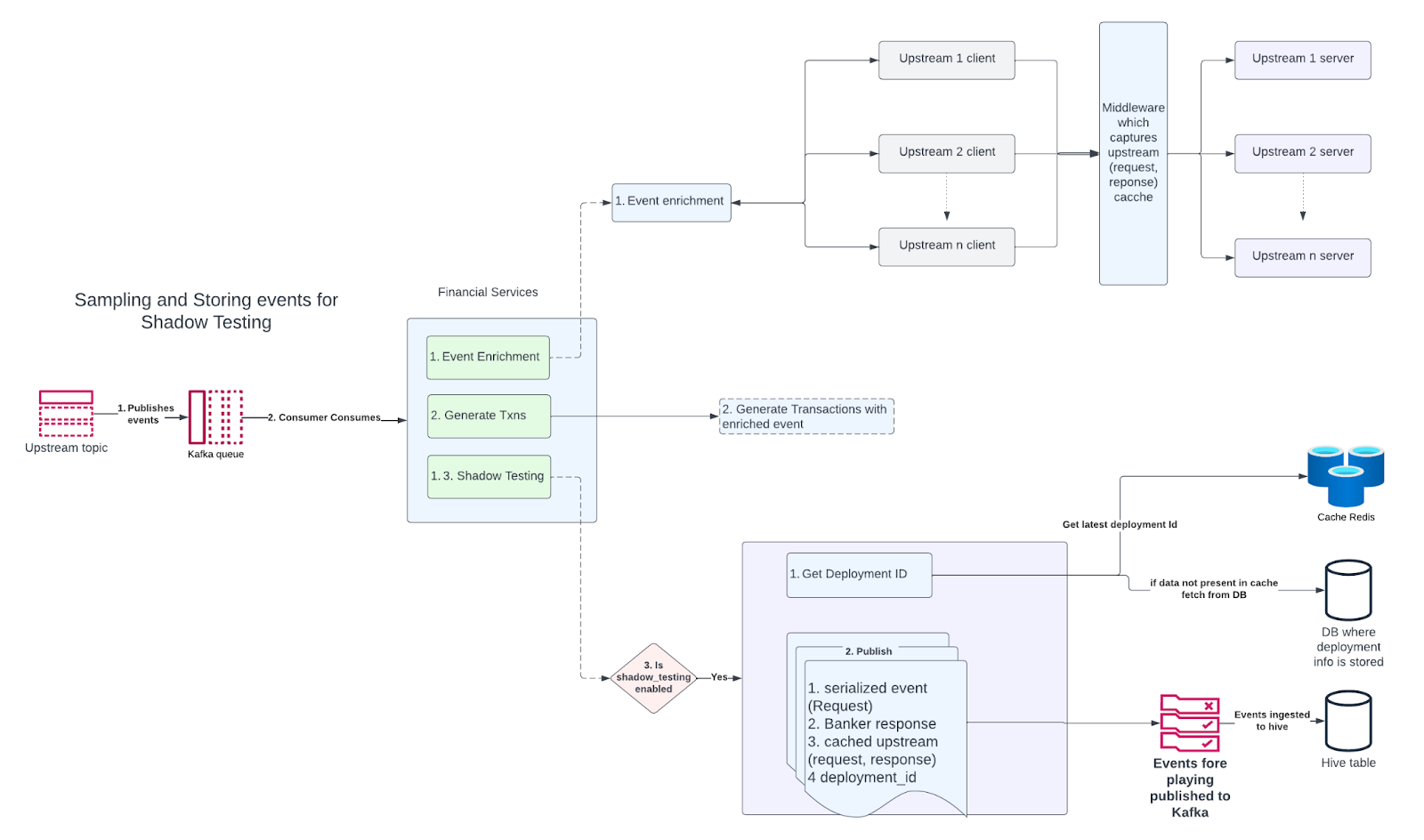
The purpose of shadow testing is to serve as a final checkpoint to catch any potential issues before the build can be rolled over to the production environment. It’s essentially a build certification strategy aiding in making informed decisions about deploying a release candidate (RC). The core process involves passing production traffic through an RC and comparing its outputs with those from the current production build to spot any anomalies.
Shadow testing consists of three parts:
- Capturing Production Requests: There are multiple strategies to achieve this. One of those entails recording the (request, response) pairs from production traffic intended for comparison against the RC.
- Replaying Production Traffic: These captured requests are replayed against the RC, and the responses are compared to those from the production environment. Any differences are logged for further analysis.
- Analyzing Differences: Involves a thorough examination of the logged differences to determine the confidence level of the RC. This step is crucial for certifying the build’s readiness for deployment.

Challenges and Solutions
- Volume of Traffic and Upstream Calls: With the fintech services processing over 10K+ events per second, replaying all this traffic against the shadow build is impractical and could result in rate-limiting issues due to numerous upstream calls.
- Traffic Sampling and Load Distribution: To mitigate this, we adopt a strategy of sampling a fraction of traffic (e.g., 10%) and distributing the replay over an extended period (e.g., 5 hours). This reduces the calls per second, but also limits the scope of testing.
To solve this problem we cache the upstream calls and responses, instead of making real-time network calls.
- Caching Upstream Calls: We implemented a caching mechanism for upstream (request, response) pairs to avoid redundant calls during replay, at the cost of increased storage expenses. We minimized the increased storage costs by keeping a retention period of x days post which old data is cleaned up. We always replay against the latest set of data.
- This approach lacks the ability to detect real-time issues stemming from upstream changes. To mitigate this, we are developing a mechanism for sampling traffic and load distribution.
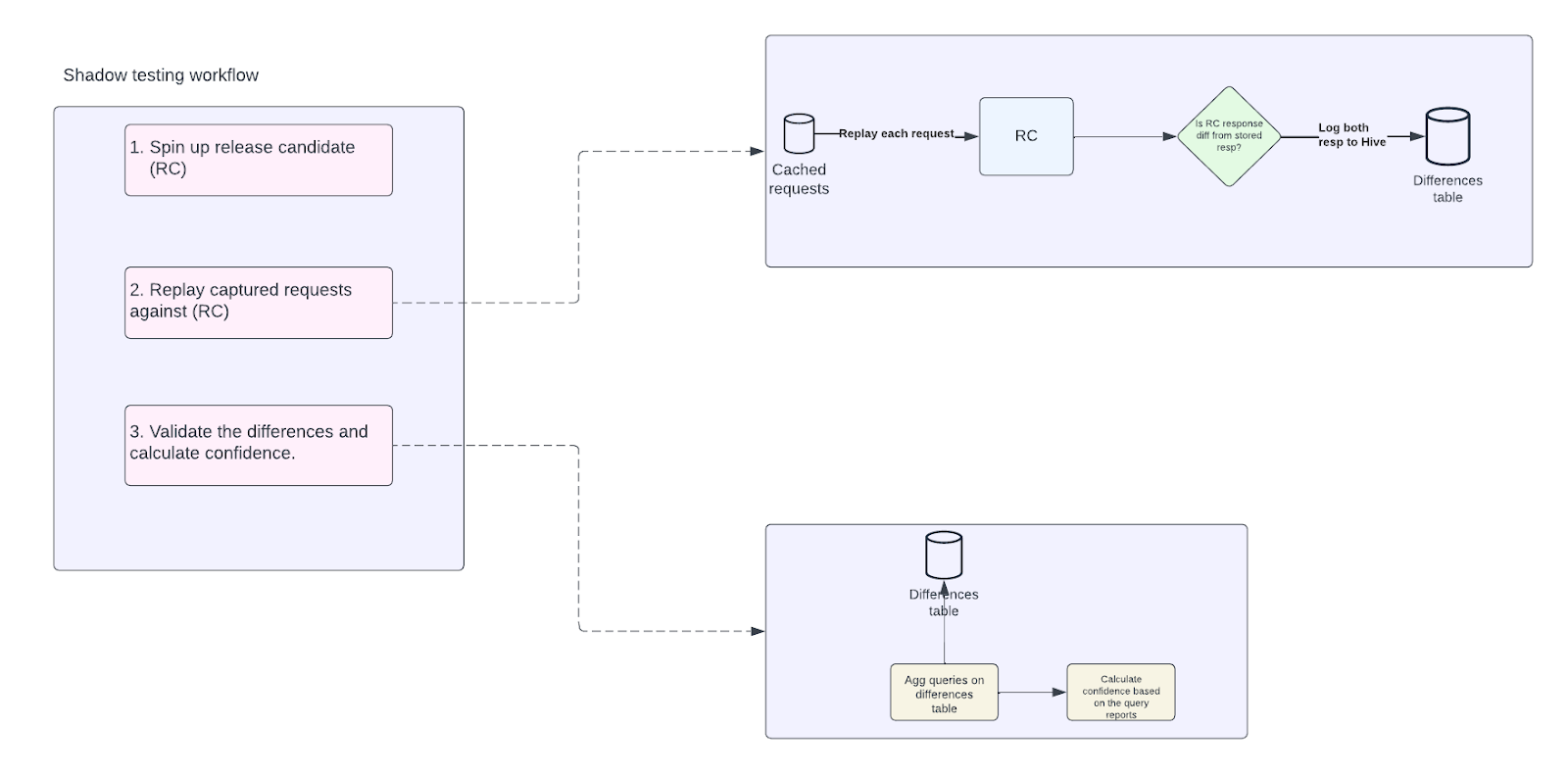
Replaying Captured Requests
- A specialized workflow has been developed for replaying stored requests within a given timestamp range against an RC. Discrepancies between the stored responses and the RC’s responses are logged for analysis.
Validating and Analyzing Differences
- This phase involves scrutinizing the identified discrepancies. The aim is to differentiate between expected variances and anomalies. This requires an in-depth understanding of the response structure of the Banker system.
- Banker’s Response Structure: The output from Banker is an array of complex data types called ‘transactions,’ each representing multiple journal entries with attributes like credit, debit, GL account, and line of business.

The confidence in the build is gauged by how far the monetary discrepancies stray from predefined thresholds.
Example Scenario and Analysis
- Transaction Comparison: Transactions from both the primary and shadow builds are compared. Differences are logged in a datastore.
- Datastore Attributes: The logged data includes the transactions, their source (primary/shadow), the RunID of the replay workflow, and a timestamp.
- Detailed Analysis: We conduct analyses focusing on anomalies in specific areas like LineOfBusiness and GlAccountNumber, using queries to identify monetary discrepancies. The build confidence is adjusted based on these findings.
As an example, consider E1 is the event that we processed against Production and release candidates. TxnP is the transaction we got from Production instance and TxnS is the transaction we got from Release Candidate:

TxnP and TxnS diff in LineOfBusiness. Hence, we would log them to a datastore for analysis. Our data store will contain four attributes:
- Transactions -> Array of transactions.
- Source -> Primary/Shadow. (i.e.) If the transactions are coming from Production or Shadow build.
- RunID -> RunID of the Replay workflow. Since we can run multiple shadow testing workflows with different builds, we should make sure that we are only analyzing the differences of a specific workflow.
- Timestamp.
Post replaying the E1, our datastore will contain the following two new records:
- (TxnP, Primary, runID, currentTimeStamp)
- (TxnS, Shadow, runID, currentTimeStamp)
There are multiple ways in which we can analyze these differences. For our use case, we are most interested in capturing any anomalies in LineOfBusiness and GlAccountNumer. Hence, we have written queries that identify the monetary differences between Production and Release candidates across these LOB and GlAccountNumber dimensions. If the monetary difference on credit or debit is beyond a certain threshold, we would reduce the confidence of the build. The farther it strays beyond the threshold, the lower the confidence of the build.
For the above example, the shadow testing report for LOB differences will look as follows:

Consider that we define a threshold of 1,000 USD per line of business. In that case, the difference of 100 is still well below the threshold and hence the confidence of our build would be unaffected.
By adopting this shadow testing strategy, you ensure a comprehensive and thorough evaluation of the release candidate. This methodical approach not only identifies potential issues but also provides insights necessary for improving future builds, ultimately contributing to the robustness and reliability of your deployment process.
Deployment
Canary Testing
In the financial accounting services at Uber, the builds are deployed daily. To ensure the successful deployment of each build and minimize the impact of issues such as performance degradation, increased error rates, and resource exhaustion, incorporating a canary deployment is crucial. This strategy facilitates a controlled release, preventing immediate impacts on the entire traffic. It enables the identification and resolution of potential issues before a complete deployment occurs.
The canary release approach is employed to test real traffic (<=2% traffic) with minimal impact. When a new build is ready for deployment, the canary zone serves as the initial deployment target. If any errors or issues arise during this deployment, the build is not propagated to other production regions, preventing widespread disruption and ensuring a more controlled release process.
Deployment monitoring and alerting
The financial accounting service platform consumes data from various upstream sources. To monitor the health of the services, we have configured multiple metrics and alerts. Metrics are tracked and alerts are configured to pause the deployment pipeline and roll it back if we get an alert after deployment for a prescribed period.
Dead Letter Queues
DLQ (Dead Letter Queue) stores unprocessed events due to errors. Elevated DLQ counts indicate issues like buggy code, corrupt events, upstream service problems, or rate limiting. Each message queue has a corresponding DLQ for handling unprocessable events. Ideally, the DLQ must have zero events. We use threshold-based alerts for detecting issues and investigating root causes when alerts are triggered. We log all errors, including event details, to a dedicated Apache KafkaⓇ topic and ingest them into an Apache HiveTM table. We have configured Data Studio dashboards for monitoring the Apache HiveTM table, providing insights on DLQ events’ impact, count, freshness, and trends. This data-driven approach aids in quickly identifying and prioritizing issues for root cause analysis and system improvement.
Alerts and Monitors
Alerts are primarily used for flagging urgent and critical issues that need to be looked at immediately. Monitors are dashboards on which alerts are configured. The alerts should always be actionable. It is also recommended to tag every alert with a corresponding runbook.
Our team alone has around 400+ alerts configured, spanning a wide range of dimensions, including but not limited to DLQ count, consumer lag of message queues, service availability, etc.
Completeness Checks
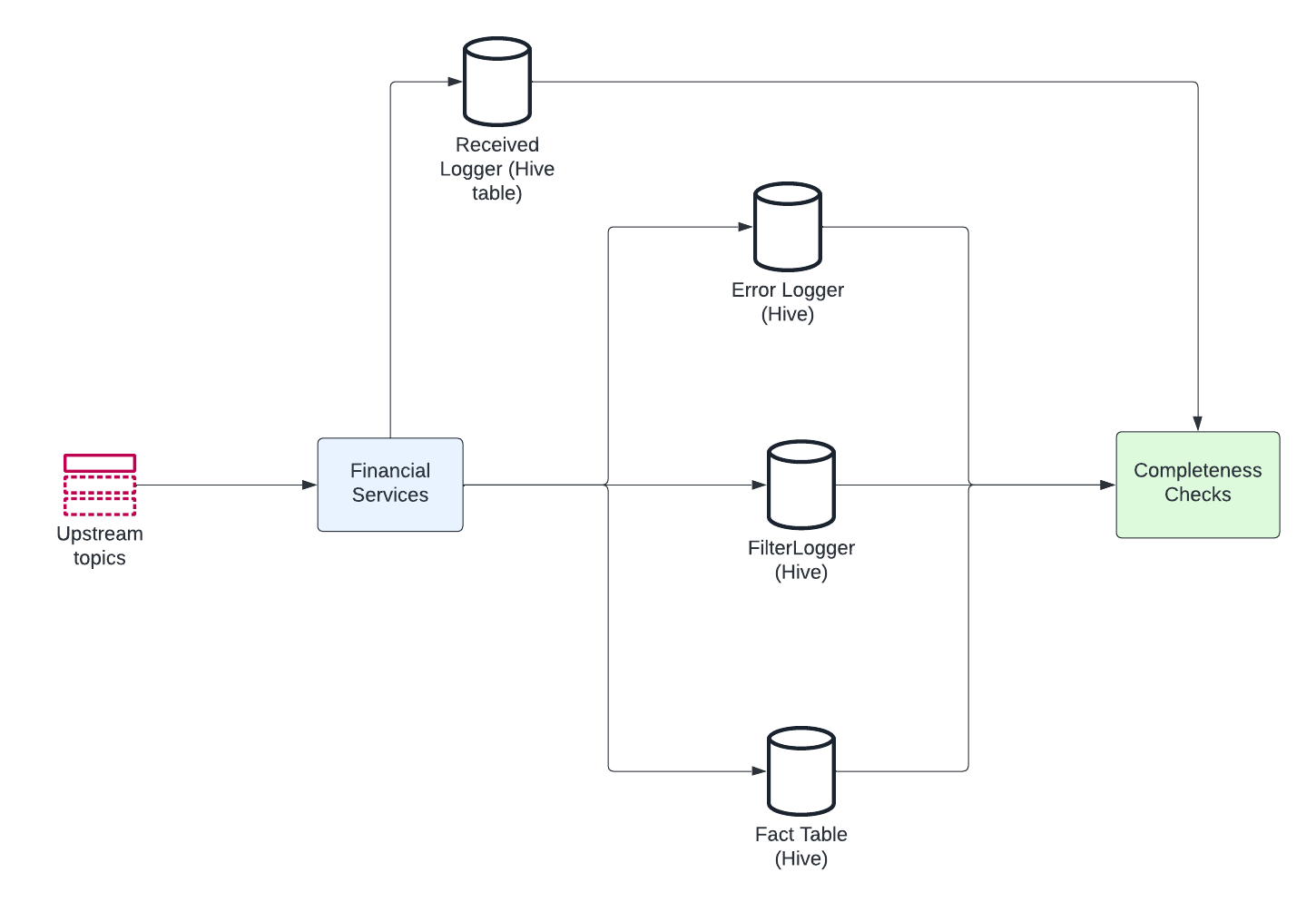
All the events received by Financial Services need to be accounted for. When an event is received by our services, it is recorded in the Received Logger. The natural outcomes of processing an event are either of the following
- Event Processed – Recorded in Fact Table
- Event Filtered or Ignored – Recorded in Filter Logger
- Event Processing Errored Out – Recorded in Error Logger
To ensure that all incoming events are accounted for, we perform completeness checks. These checks confirm that all events logged in the receive logger are also logged in either the Error logger, Filter logger, or the Fact Table (indicating successful processing).
Results
Leveraging the aforementioned testing and detection strategies, our team has achieved a remarkable milestone in 2023: reducing the number of accounting incidents to zero. This significant accomplishment reflects our dedication to accuracy and efficiency in financial management. Furthermore, there has been a notable decrease in manual journal entries, a direct result of diminished accounting errors. This improvement has not only enabled the timely closure of monthly accounting books but has also bolstered our confidence in managing multiple projects within the accounting domain as evidenced by the 17% improvement in throughput. These advancements demonstrate our commitment to excellence and reliability in our accounting practices.
Conclusion
In conclusion, the comprehensive and multifaceted Fintech Testing Strategies employed by Uber’s Financial Accounting Services (FAS) have proven to be a resounding success. Through rigorous validation processes at every step–from business requirement validation to report generation, and employing advanced techniques such as regression testing, SLATE, integration testing, and shadow validations–Uber has set a new standard in financial systems’ reliability and accuracy.
The challenges of handling immense volumes of transactions and data have been met with innovative solutions that not only address current needs but also scale for future growth. The meticulous approach to testing and validation, coupled with deployment strategies like Canary testing and vigilant monitoring and alerting systems, exemplifies Uber’s commitment to maintaining the highest standards in financial technology. In the next year, we are adding even more functionalities to our testing strategies to support the detection and auto-correction of bad inputs to support an error-free self-serve journey.
Uber’s journey in refining its Fintech Testing Strategies serves as a benchmark for others in the industry, underlining the importance of continuous innovation and rigorous testing in the ever-evolving landscape of financial technology.

Onkar Singh
Onkar Singh is a Sr. Software Engineer on the Fintech team at Uber. With over 7 years of experience, his expertise lies in Distributed System Design, Scalable Systems, and Backend Development. Currently, his contributions focus towards creating a consolidated ledger, integrating Revenue, Settlements, and Cash accounting into a unified accounting platform.

Harsha Aditya Ravuri
Harsha is a Sr. Software Engineer with specialized expertise in developing scalable, distributed systems. His work at Uber focuses on enhancing software deployment processes, implementing fault-tolerant systems, and reducing operational complexities in high-availability environments.

Viswanath Ramakkagari
Viswanath is a seasoned Staff Software Engineer with 16 years of experience in software development. His expertise lies in spearheading systems that manage Uber's Financial and Accounting needs, ensuring scalability, reliability, accuracy, and maintainability are at the forefront.

Aditya Gopisetti
Aditya is an Engineering Manager overseeing the services that automate the accounting of every Uber order, guaranteeing both accuracy and completeness. His technical and leadership acumen have been instrumental in enhancing the efficiency and effectiveness of Uber's financial operations.

Hari Srinivasan
Hari Srinivasan is the Director of Engineering—Fintech at Uber. Leading a technically skilled team of engineers, he oversees the development of the platform that facilitates seamless financial accounting of all transactions and money movement within Uber.
Posted by Onkar Singh, Harsha Aditya Ravuri, Viswanath Ramakkagari, Aditya Gopisetti, Hari Srinivasan
Related articles


Most popular

Uber’s Journey to Ray on Kubernetes: Ray Setup

Case study: how Wellington County enhances mobility options for rural townships

Uber’s Journey to Ray on Kubernetes: Resource Management
