Differential Backups in MyRocks Based Distributed Databases at Uber
August 1 / Global
Introduction
Uber uses MySQL® as the underlying storage layer for Schemaless and Docstore, Uber’s in-house distributed databases. Storing tens of petabytes of operational data and serving tens of millions of requests/second, it is one of the largest database services at Uber, used by microservices from all business verticals and serves critical Uber use cases worldwide.
The Uber Storage Platform team migrated all Schemaless and Docstore instances to MyRocks, a RocksDB storage engine based MySQL® version. The primary motivation was that RocksDB engine is optimized for write and outstanding storage space efficiency.
In this post, we are going to talk about our journey of how we solved the subsequent issues with a lack of incremental backups for MyRocks, and the interesting technical challenges that we faced along the way.
Motivation and Background Behind Project
Uber’s operation, bridging the physical and digital realms, relies heavily on robust, distributed databases, which are essential for a range of critical functions from disaster recovery to business continuity and compliance. These databases also support vital auditing and data analysis efforts across the company.
Schemaless and Docstore have a layered architecture and a Docstore deployment is called an instance. In the architecture of a single Schemaless or Docstore instance, data is organized into shards. These shards are further distributed across multiple physical partitions to ensure scalability and manageability. Each partition houses redundant copies of the data, all located within a single region on individual MySQL® servers. Notably, each server is configured to store a single RocksDB column family, optimizing data handling and storage efficiency.
To bolster data availability and safeguard against regional outages, each partition is also replicated across various geographical regions. This replication strategy not only enhances the resilience of Uber’s data infrastructure but also supports the company’s global operations, ensuring data integrity and accessibility across different markets.
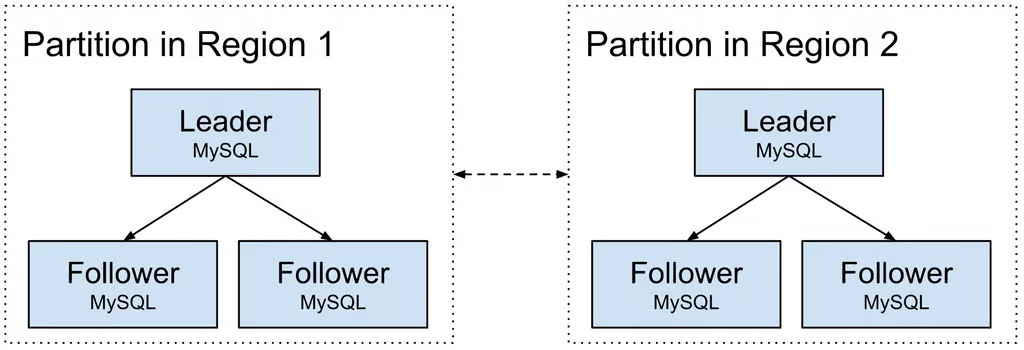
Backup process for a single Schemaless and Docstore instance traditionally involves using the Percona Xtrabackup™ tool to conduct periodic backups across all partitions and storing these in a blob store for a predetermined retention period. However, with the transition to the MyRocks engine, the lack of support for incremental backups has significantly increased the cost and complexity of maintaining these backups. At Uber’s extensive scale, this change has led to storing hundreds of petabytes of full backups, which incurs millions in blob store expenses. Our motivation was to tackle two important pain points for our ever growing instances: escalating cost and speed of backups.
- Cost: The storage of backups results in a substantial monthly cost in blob store usage; this problem is expected to grow alongside our business, further inflating expenses. The costs associated with our backup strategy are largely due to the lack of support for incremental backups or partial backups by Percona Xtrabackup for MyRocks engine, necessitating full backups for each partition every time a backup is taken.
- Speed: Another critical issue, as instance partition sizes increase—varied by the sharding of customer data—the time required to complete each full backup also increases. This variation puts additional pressure on our backup infrastructure to keep pace with growing data volumes, challenging our ability to scale efficiently.
Challenges
In the pursuit of a solution, we set ourselves guidelines principles that were challenging yet measurable. Our solution should be:
- Scalable to thousands of partitions across instances and also scale well with the growth of the partition size
- Have predictable Service Level Agreement (SLA) time for backup completion per terabyte of partition data
- Compatible with the current ecosystem built for backups and not boiling the ocean to have a drastically different approach, which would drag out the project timeline
We explored multiple options to address the pain points, such as:
- Improving efficiency of the backup scheduler, which intelligently deferred the backups to a later time, but did not address the root cause
- Solving a few latent bugs with the backup process, which helped reduce cost, but was a one-time medication
- Changing tiering options in our blob store, again being a one-off solution
- Evaluating logical backups (with compression), which did not yield much savings compared to the already-efficient physical backup (majorly due to MyRocks already being efficient in storing data)
- Logical backups paired with Binlog backup, which did not yield much in terms of savings and also increased the cost for separate binlogs
All these options were one-off solutions that helped reduce about 17-20% in blob store usage, but did really provide a viable long-term solution to keep the backup footprint low.
Differential Backups To Rescue
Context
During the evaluation to enhance our backup strategies, we explored various options including logical backups (with tools like Mydumper) and experimented with different compression methods for both physical and logical backups. We also considered designs involving physical backups with random partition sharing. Through these explorations, we identified that the Percona XtraBackup tool was the most effective for capturing a consistent snapshot of the database at a specific point in time (corresponding to a specific Log Sequence Number or LSN). It proved superior in terms of memory usage and speed compared to other methods.
Percona XtraBackup operates directly on live databases, copying both the data files and, when configured, the binary log files of the MyRocks server. It ensures data consistency and guards against corruption from ongoing transactions. Additionally, it can prepare backup files for restoration, apply incremental backups, and stream them to different storage devices. Given these robust capabilities, we decided to continue using XtraBackup for our backup and restoration processes.
However, a significant challenge remained: XtraBackup does not support incremental or partial backups for the MyRocks engine. As a result, each backup was a full backup, often containing up to 95% duplicate data from previous backups. To address this inefficiency, we delved into the backup file structure to identify deduplication opportunities. This deep dive revealed potential strategies to optimize storage and reduce redundancy in our backup process.
We found that XtraBackup backup and RocksDB file structures shared a lot of similarities:
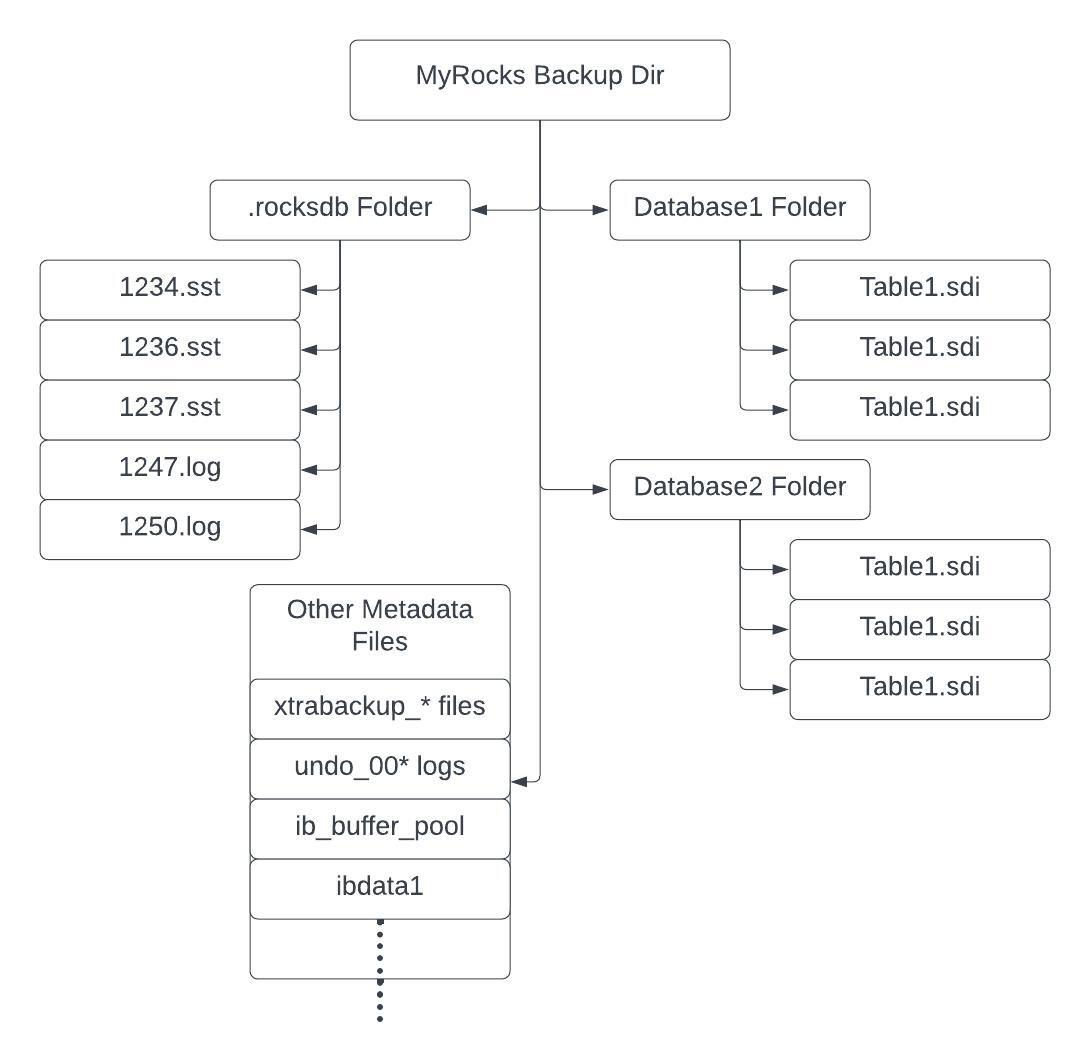
- All the data for a MyRocks database is stored in multiple files called SSTable files (*.sst). The data in each SSTable file is immutable, thus each time more data needs to be written to the database a new SSTable file is created and flushed to disk.
- XtraBackup takes physical backups, which involves backup of database directories and physical files. For MyRocks, a backup is a copy of all relevant SSTable files on disk, when the backup is initiated, and database metadata such as the database schema (*.sdi), ibdata1, .log, checkpoint files and a few small metadata files needed for recovery. The SSTable files contain the actual database data and account for more than 95% of the backup size.
- Every incremental backup on the MyRocks storage engine does not determine if an earlier full or incremental backup contains the same files. XtraBackup copies all the SSTable files each time it takes a backup.
Solution
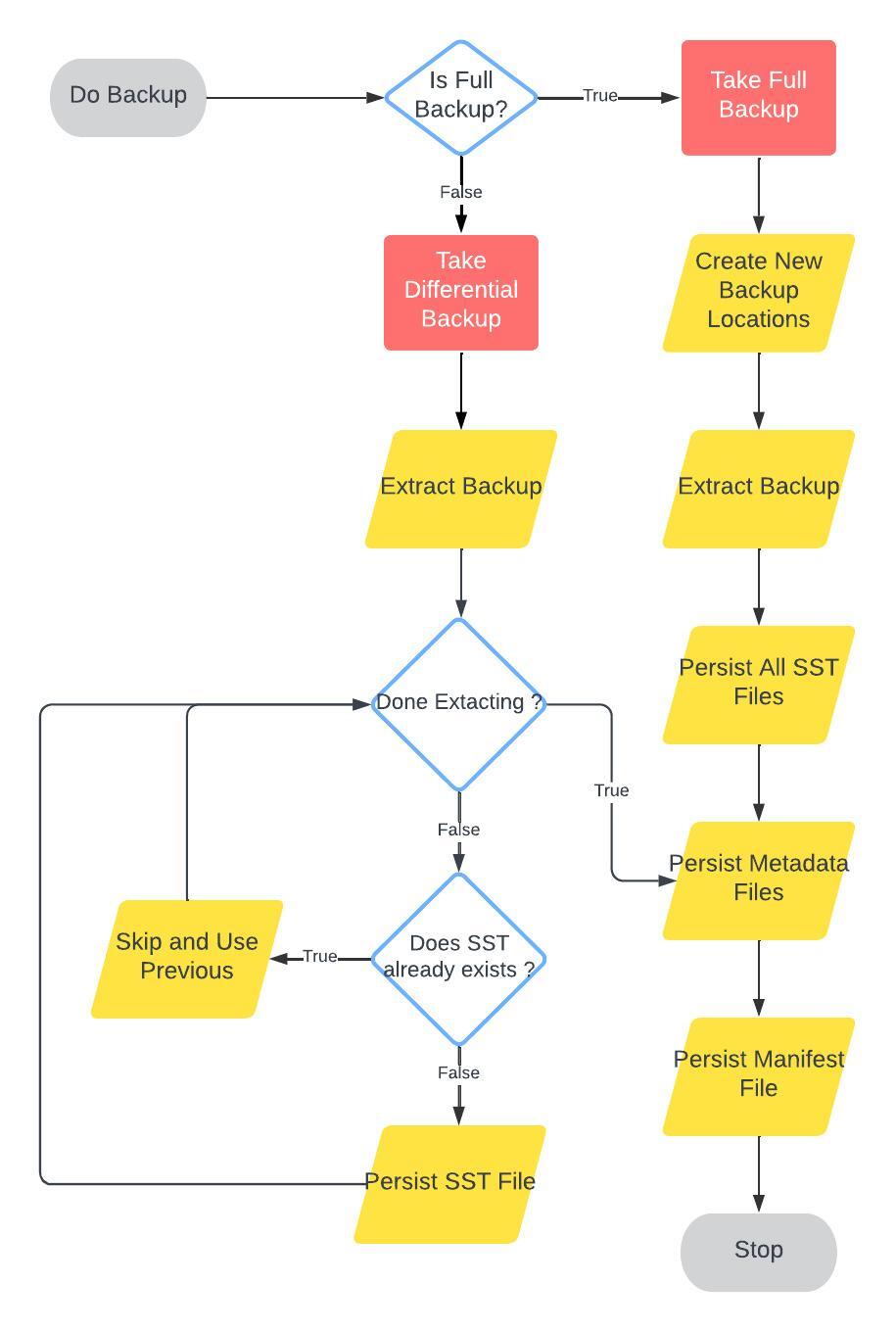
Our backup strategy capitalizes on the immutability of SSTable files, which often remain unchanged between consecutive backups. This insight allows us to adopt a more efficient differential backup approach, reducing unnecessary data duplication by sharing SSTable files across backups. Here’s how this streamlined process is implemented:
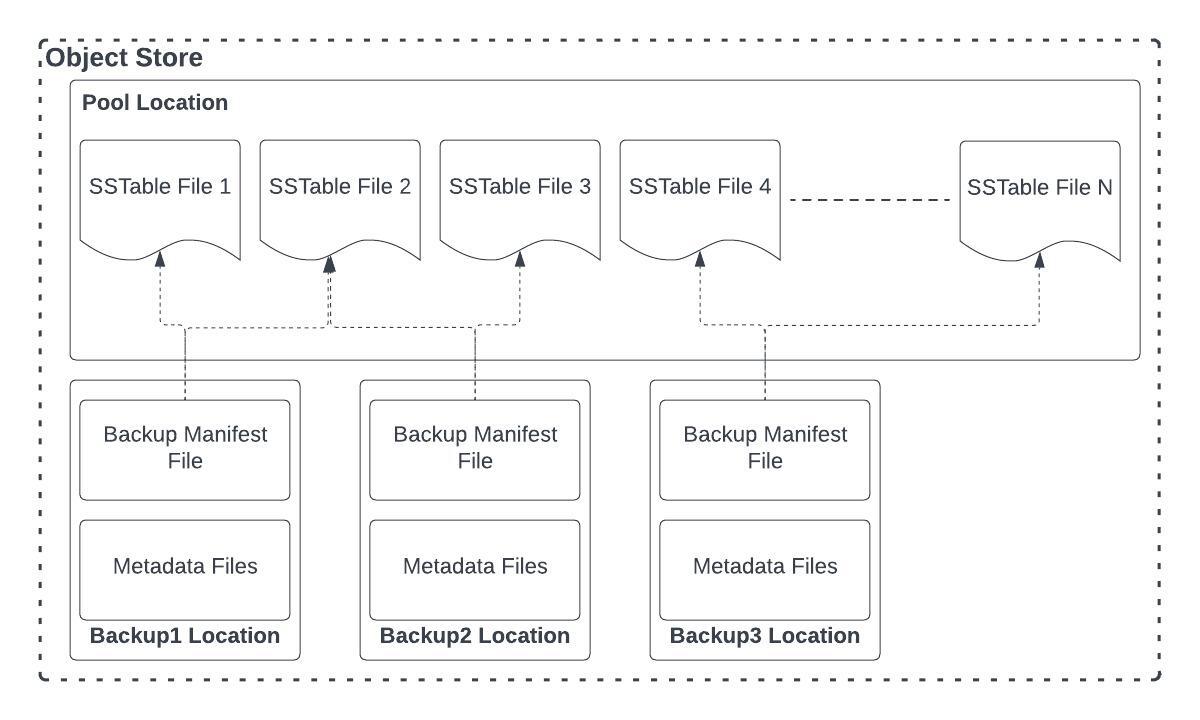
- Initial Full Backup: We start with a full backup, during which all metadata and SSTable files are stored in a shared “pool of SSTable files” within the blob store. This acts as a foundational data repository for all future backups.
- Differential Backups: Subsequent backups only add newly created SSTable files to the pool. Existing SSTable files from previous backups are reused, minimizing data redundancy. Each backup is defined by a simple backup manifest file, which records the specific files included in that backup.
- Restoration: When restoring data from a specific backup, the backup manifest file guides the process. It serves as the definitive reference, dictating which files to retrieve from the pool to accurately reconstruct the data.
- Cleanup: SSTable files that are no longer referenced by any backup manifest are eventually purged from the system through a dedicated TTL (Time To Live) process, ensuring efficient use of storage space.
This approach not only enhances backup efficiency by reducing the volume of data stored, but also speeds up both the backup and restore processes by eliminating redundant data handling.
Backup Manifest File
Next, let’s delve into the manifest file internals. The core concept of a differential backup is sharing the SSTable files with previous backups. Hence it’s important for each differential backup to have the backup manifest file, which keeps track of what files are ultimately required for restoring that specific backup during the recovery process.
The manifest is a simple json file. Each backup will have its own manifest file associated with it and is used to quickly index the individual files in the backup. The backup manifest file consists of different properties.
The manifest file firstly records the type of backup and its success status (success/failure). For each backup operation, it records the start and end time along with the actual backup size and full data set size. It also stores information of the instance name, the physical node the backup was taken from and the MySQL version. The core of the manifest file is the set of manifest records (one per SSTable file) which define for a given SSTable file—including file name, storage path, file size, and SHA256 checksum for integrity checks. Finally, it records the blob store path of the metadata tarball containing the database files(*.sdi), ibdata1, .log, checkpoint files, xtrabackup_info, etc. This information is the starting point for the next backup that gets triggered, building on the existing SSTable file pool.
Backup Architecture
Now that we have introduced the core components of the differential backup, let’s take a detailed look at how backups are orchestrated. Backups are taken at a partition level from one of the MyRocks containers on one of the 2 follower nodes of the partition and are triggered by a stateless service called Backup Scheduler. It takes care of the frequency and the timing of the backups depending on the partition’s backup state (stored separately in a state machine).
Once triggered, the actual backup is taken by the individual backup containers in the partition node. Backup container is an ephemeral container, which boots up when required to take a backup and runs the XtraBackup tool to extract the backup, persists the backup in the blob store, persists the state and goes back to sleep.
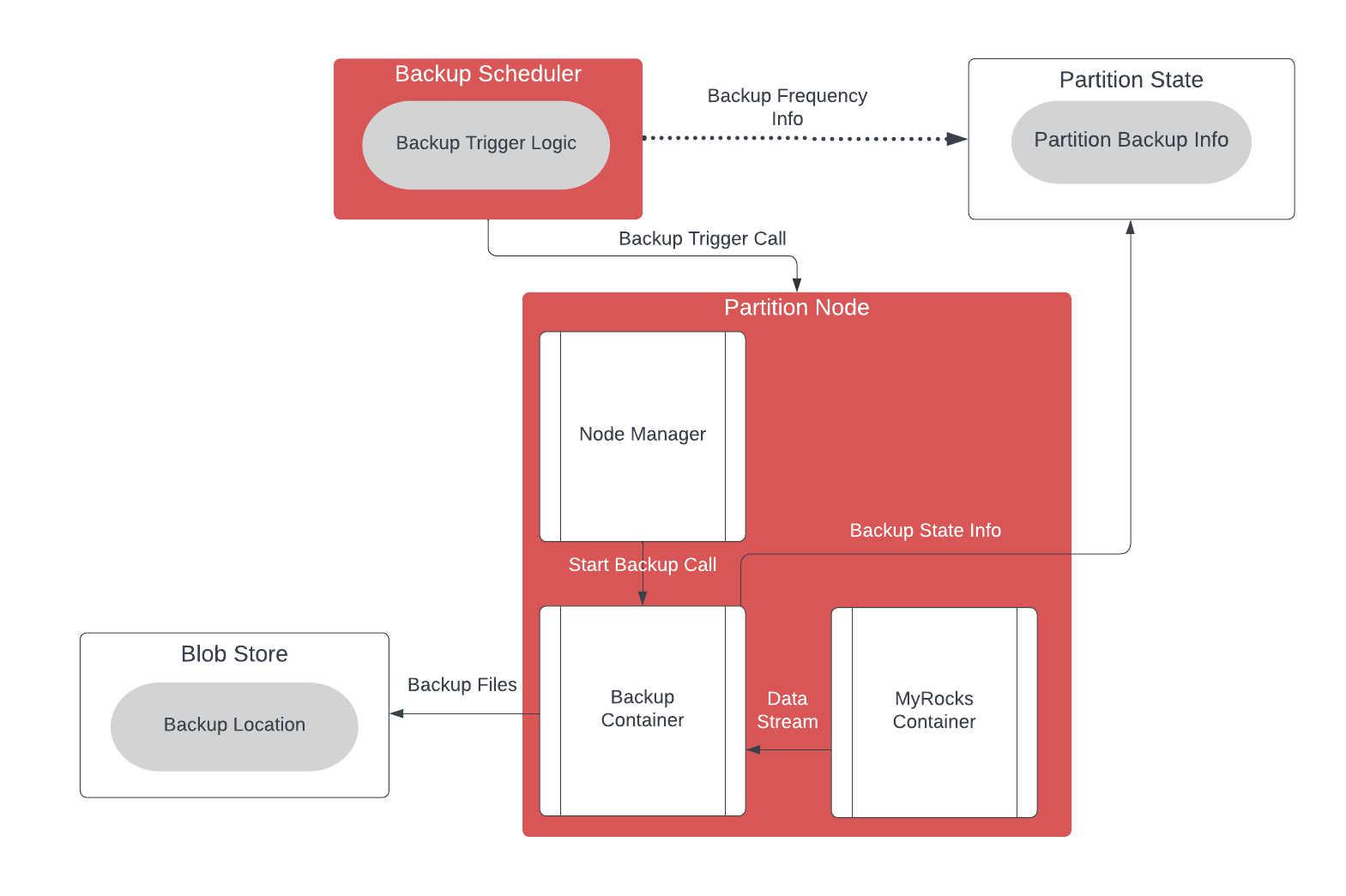
Before we get into the backup container process level, here are the terminology definitions:
SSTFile Pool Location: This is the location in the blob store where all the SSTable files are pooled together to be shared/referenced by the differential backups.
Individual Backup Location: This is the location in the blob store specific to a backup and will contain the tarballed metadata files and backup manifest file. This is not shared with any other backup and is unique to the specific backup and specific partition node as well.
The backup process begins with the scheduler determining if a new backup is needed based on the last backup time and frequency, typically selecting the same partition node as before. The scheduler then instructs the node manager to initiate a backup container equipped with specific information, such as the previous manifest file if performing a differential backup. XtraBackup is used to stream the backup data directly into the backup container’s disk buffer. Metadata files are compressed into a single tarball to minimize blob store interactions and simplify restoration, while SSTable files are checked against the backup manifest to determine if they exist in the SSTFile pool location in the blob store. New files are persisted, and existing ones are noted in the manifest without re-persistence. The routine regularly updates the manifest file in the blob store to maintain backup consistency and avoid data loss.
Once backup extraction completes, the backup manifest is marked as valid and saved, marking the end of the backup process. If issues arise, the manifest is saved with a status indicating the problem. Post-backup, manifest files are categorized by retention period, with obsolete SSTable files and expired metadata and manifest files being purged from the blob store to manage space and maintain efficiency.
Full vs. Differential Backups
Now let’s dive deep into how a full backup and differential backup differ. The Backup Scheduler plays the role of a decision-maker, determining whether to conduct a full or differential backup based on specific conditions. The default choice is a differential backup, offering efficiency by only saving changes since the last full backup.
Full backups are like starting a new chapter. They involve a complete copy of all SSTables from a partition node, similar to traditional backups done with XtraBackup. This process is initiated in several key scenarios:
- The first time this backup method is rolled out in production, setting the foundation for all future differential backups
- When the previous partition node is no longer suitable due to removal or changes that impact backup integrity, necessitating a new full backup from a different node
- Following a MyRocks version upgrade, even though SSTables from different versions might be compatible, a full backup ensures no version mismatches interfere
- When the existing pool from a full backup has reached its limit of differential backups, to prevent potential corruption that could jeopardize all backups
Differential backups then take the stage, stepping in after a full backup unless conditions dictate otherwise. These backups focus on storing only the new or altered SSTable files from the partition node, significantly reducing the volume of data stored. This strategy not only saves space but also cleverly shares SSTable files across multiple backups, with a structure that organizes manifest files and metadata efficiently.
Each backup type has its role, either laying a robust foundation with full backups or building efficiently on that base with differential backups, ensuring data integrity and optimization in the backup process.
Limitations
Every design approach comes with its set of tradeoffs and assumptions, and backup strategies are no exception. The chosen method primarily leverages the efficiency of sharing older files while only adding new data to the backups. However, this model isn’t without its challenges.
- In environments where partitions are highly active or undergo frequent compaction—referred to as “hot partitions”—the expected benefits of differential backups might be reduced. These scenarios, which vary from one partition to another, are inevitable and affect the overall savings of the backup process.
- Moreover, the strategy is designed with a preference for using the same partition node for all backups, assuming that the node remains in a suitable state for backups. Should a node be replaced or shifted into an unsuitable state, a full backup becomes necessary.
Restoring Differential Backups
Restoring a XtraBackup MyRocks backup is pretty straightforward as it uses the same Percona XtraBackup tool to restore. The high-level steps of the recovery process go something like this:
- Locate the valid backup that needs to be restored in the blob store.
- Download the backup manifest file from the blob store to a temporary restore location.
- Lookup the backup manifest file and download the SSTable and the metadata file (and extract from tarball) and move the SSTable files to the .rocksdb folder that will appear after extraction. At this point, we have assembled the backup exactly like what XtraBackup took the backup during backup time.
- Run XtraBackup prepare command, which will run the crash recovery process to make the backup consistent to the scanned LSN.
- Stop MySQL process and run the XtraBackup copy back command to replace the MySQL data folder (e.g., /var/lib/mysql/*) with the downloaded and prepared backup data.
- Restart MySQL process and start using the restored database.
Conclusion
The differential backup strategy has proven to be a game-changer in terms of efficiency and storage savings:
- By not persisting unchanged data to the blob store, we’ve managed to cut down blob store usage by petabytes, achieving a substantial 45% reduction in data storage across most instances. In some of our larger instances, the savings are even more dramatic, with reductions of 70% or more every time a differential backup is executed.
- Additionally, the redesigned backup process is also a lot faster. The full backup completion time averaged 2X faster than the speed of previous backup completion time and differential backups averaged 5X faster.
Acknowledgements
Thanks to Hao Xu, Vlad Dmitriev, Amit Garg, Mohammed Khatib, David Turner and Andrew Regner for the mentorship and guidance in shaping this project to what it is today. Thanks Osama Mazahir and Piyush Patel for their invaluable leadership.
Percona®, Percona Xtrabackup, Percona Server for MySql, and the star logo are either registered trademarks or trademarks of Percona in the United States and/or other countries. No endorsement by Percona is implied by the use of these marks.
Cover Photo Attribution: “Server room at CERN” by torkildr is licensed under CC BY-SA 2.0. No changes have been made.

Adithya Reddy
Adithya Reddy is a Software Engineer on the Storage Foundations team at Uber. Primarily focusing on distributed database operations and their business continuity. He has deep knowledge in developing and operating highly scalable distributed storage solutions for Relation and NoSQL database technologies.

Shriniket Kale
Shriniket Kale is an Engineering Manager II on the Storage Platform org at Uber. He leads Storage Foundations, which has teams focusing on three major charters (MySQL and MyRocks, Docstore Control Plane and Reliability, and Cassandra). These teams power the Storage Platform, on which all critical functions and lines of business at Uber rely worldwide. The platform serves tens of millions of QPS with an availability of 99.99% or more and stores tens of Petabytes of operational data.
Posted by Adithya Reddy, Shriniket Kale
Related articles




Most popular

Open Source and In-House: How Uber Optimizes LLM Training

Horacio’s story: gaining mobility independence through innovative transportation solutions

Streamlining Financial Precision: Uber’s Advanced Settlement Accounting System

Uber, Unplugged: insights from 6 transit leaders on the future of how we move
Products
Company