
In one sense, Uber’s challenge of efficiently matching riders and drivers in the real world comes down to the question of how to collect, store, and logically arrange data. Our efforts to ensure low wait times by predicting rider demand, while simultaneously enabling drivers to use the platform as effectively as possible by taking into account traffic and other factors, only magnifies the scope of data involved.
To better focus how we manage the massive amounts of real-time data over multiple systems that make up the Uber Marketplace, we developed the Rider Session State Machine, a methodology that models the flow of all the data events that make up a single trip.
We refer to the data underlying each trip as a session, which begins when a user opens the Uber app. That action triggers a string of data events, from when the rider actually requests a ride to the point where the trip has been completed. As each session occurs within a finite period of time, we can more easily organize the relevant data to be used for future analysis to further enhance our services. Among other functions, categorizing Uber’s trip data into sessions makes it easier to understand and uncover issues or introduce new features.
Read on to learn how we designed this new session state machine and lessons learned along the way.
The Rider Session State Machine
One of the critical pieces of information we want to capture and understand in real time is the complete lifecycle of a single Uber trip, from the moment a rider opens the app to when they arrive at their final destination. However, given the complexity and scale of our systems, this data is distributed over multiple disparate event streams.
For example, when someone opens the Uber app, it prompts them to choose a destination and fires off an event on the user log’s event stream. The app displays products (uberPOOL, uberX, UberBLACK, etc.) available in that geographic region along with prices for each, as generated by our dynamic pricing system, with each price appearing as a discrete event on the impression event stream. When that rider selects a product, the request goes to our dispatch system, which matches the rider with a driver-partner and assigns their vehicle to that trip. When the driver-partner picks up the rider, their app sends a ‘pickup completed’ event to the dispatch system, effectively starting the trip. When the driver reaches their destination and indicates that the passenger has been dropped off in their app, it sends a ‘trip completed’ event.
A typical trip lifecycle like this might span across six distinct event streams, with events generated by the rider app, driver app, and Uber’s back-end dispatch server. These distinct event streams thread into a single Uber trip.
How do we contextualize these event streams so they can be logically grouped together and quickly surface useful information to downstream data applications? The answer lies in defining a time-bounded state machine modeling the flow of different user and server-generated events towards completion of a single task. We refer to this type of state machine, consisting of raw actions, as a “session.”
In the context of an Uber trip lifecycle, a session consists of a series of events beginning when a rider opens their app and ending at the successful completion of their trip. We also have to consider that not all sessions go through this complete series of events, as a rider might cancel the trip after making the request or just open the app to check fares. Because of those factors, it was important for us to enforce a time window on a session.
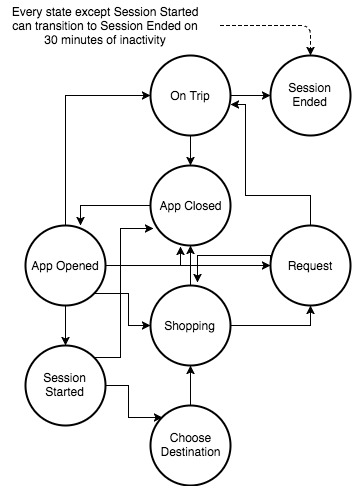
The trip session starts when a user opens the app, generating a discrete event on the app’s log. When a user browses the Uber products available at their location, our trip pricing back-end system delivers multiple impressions to the app, showing the price of each, initiating the Shopping state in the session. We can glean the Request Ride state from both the app’s mobile event stream for requesting events as well as the event stream generated by the Dispatch system, which logs all the requests it receives. When a driver presses the “Pickup Completed” button on their app, the session enters its On Trip state. And, of course, the session ends when the driver presses the “Trip Completed” button on their app.
As each session models events happening in the physical world, our Rider Session state machine needs to be resilient, designed to cope with events outside of the expected. For example, a rider might cancel their trip after making a request, or a driver’s car might break down or get stuck in emergency-related traffic, forcing the driver to cancel the trip. We model these scenarios by allowing a transition from the Request Ride state back to the Shopping state.
Putting all the relevant events for our session lifecycle in one place unlocks a wide variety of use cases, such as:
- Our Demand Modeling team can compare app impressions, how many people opened the app, with real-time session data, helping to understand the probability of a rider ordering a specific product after viewing it in the app.
- Our Forecasting team can see how many sessions are in the Shopping state within a given area during a particular time window, using that information to forecast demand for that region, thereby helping drivers understand where they are most likely to pick up riders in the future.
Sessionization in production
We used Spark Streaming to implement the Rider Session State Machine in production because:
- Many of our extract, transform, and load (ETL) pipelines were built on Spark, as Samza, Uber’s previous streaming platform of choice, did not have sufficient support for state-based streaming applications such as sessionization.
- Spark Streaming’s mapWithState function for stateful streaming applications proved to be very versatile, for example offering automatic state expiration handling.
The ETL pipeline operates a micro-batching window of one minute and processes a few billion events per day. The pipeline runs on our YARN cluster and uses 64 single core containers with 8 GB of memory. The output comes in the form of state transitions which contain the relevant compressed raw event data. The output is published to Gairos, our in-house geospatial time series data system.
Lessons learned
While our Rider Session State Machine may have seemed simple in theory, applying it to Uber’s use case proved an entirely different beast. Here are some of the key lessons we learned while implementing this new methodology to our existing data flow:
- Clock synchronization: Given the wide array of handsets and variations of mobile operating systems, not to mention user settings, you can never really trust the timestamps sent from mobile clients. We have seen clock drifts from a few seconds to a few years in our production data. To get around this problem, we decided to use the Kafka timestamp, i.e., the time at which Kafka received the log message. However, our mobile clients buffer multiple log messages and send them in a single payload, so that many messages displaying the same Kafka timestamp. We ended up conducting a secondary sort using both the Kafka timestamp and each message’s event timestamp.
- Checkpointing robustness: State-based streaming jobs require periodic checkpointing of the state to a replicated file system, such as HDFS. The latency of that filesystem may directly affect the performance of the job, especially if it checkpoints frequently. A single checkpointing failure can cause catastrophic failures, such as the entire pipeline going down.
- Checkpoint recovery and backfilling: Any distributed system, especially one designed to run 24/7 in production, is bound to fail at some point; for instance, nodes will disappear, containers may get preempted by YARN, or upstream system failures might impact downstream jobs. So planning for checkpoint recovery and backfilling is essential. Spark Streaming’s default behavior for checkpoint recovery is to consume all the backlogged events in a single batch while attempting to recover from a checkpoint. We found that this put an enormous strain on our systems in cases where the time between job failure and recovery was very long. We ended up modifying the DirectKafkaInputDStream to be able to split the the backlogged events into proper batches on checkpoint recovery.
- Back-pressure and rate limit: The input rate to Kafka topics is never constant. On the Uber platform for instance, there is often heightened activity during commute times and weekend evenings. Backpressure is essential to ease the load on an overwhelmed job. Spark Streaming’s backpressure kicks in when the total time taken by the batch exceeds the micro-batching window duration. It uses a PID rate estimator to control the input rate of subsequent batches. We noticed that the built-in default parameters for the estimator produced wild oscillations and artificially low input rates during times of backpressure, affecting data freshness. Introducing a sensible floor to the rate estimator proved consequential to more quickly recover from backpressure.
- Fidelity of mobile logs: Events sent by the mobile clients can vary wildly in their fidelity. In places of low bandwidth or weak signal, messages are often lost or retried and sent multiple times. Clients can go offline due to low power mid-session, so the state machine should account for that. We realised that listening to other event streams generated by our associated back-end systems helped determine if we had lossy data from mobile clients. That experience shows that it is necessary for server-side systems to maintain their own event streams.
Moving forward
Event order processing is a difficult challenge. Although the structured streaming primitives in Spark 2.2 look promising for handling out-of-order events, we’re looking at moving to Flink due to its deeper support for out-of-box event time processing and wider support at Uber. Additionally, some of our use cases could use granularity for sessionized data, making Spark’s micro-batches infeasible, another point in favor of Flink.
If you are interested in building systems designed to handle data at scale, visit Uber’s careers page.

Amey Chaugule
Amey Chaugule is a senior software engineer on the Marketplace Experimentation team at Uber.
Posted by Amey Chaugule
Related articles



Most popular

Introducing the Prompt Engineering Toolkit

Serving Millions of Apache Pinot™ Queries with Neutrino

Your guide to NJ TRANSIT’s Access Link Riders’ Choice Pilot 2.0

Moving STRIPES: innovating student transportation at Mizzou
Products
Company