No Code Workflow Orchestrator for Building Batch & Streaming Pipelines at Scale
11December,2020 / Global
Data-In-Motion @ Uber
At Uber, several petabytes of data move across and within various platforms every day. We power this data movement by a strong backbone of data pipelines. Whether it’s ingesting the data from millions of Uber trips or transforming the ingested data for analytical and machine learning models, it all runs through these pipelines. To put it in perspective, Uber’s data platform runs upwards of 15,000 data pipelines!
But over time, the existing Python framework-based methods started showing a productivity tax on pipeline creators. The growing population of data-analysts and city-operations users inside Uber depended on a handful of data engineers to create their pipelines. What could be a few hours work often turned into a few days or weeks. In addition to that, the demand for real-time data and insights also grew quickly within Uber. But with a completely different technology stack and the complexities of building a real-time pipeline, we could not adopt real-time insight as quickly as we wanted. And getting the code right was even trickier.
The need for a simpler, unified, and intuitive user experience for building data workflows was the main impetus behind uWorc, Unified Workflow Orchestrator.
Empowering the data movement
Uber’s existing data pipeline management platforms did a great job scaling and providing the desired flexibility to serve its end users. Using Apache Airflow, Uber engineers built one of the most comprehensive workflow management systems known as Piper.
Piper boasts a comprehensive list of features:
- Extensive task support, such as Hive, Spark, MySQL, Cassandra
- An SDK for developing pipelines
- A simplified version for ETL
- Flexible task dependencies
- Comprehensive backfill options
- Alerting systems, etc.
With these features, Piper reliably runs 1000s of pipelines every day for use cases across data ingestion, data modeling, feature engineering, and data dispersal.
To reduce the time to create very simple pipelines, we have a UI based interface. This especially helps pipelines that do not need any directed acyclic graphs(DAGs) or dependencies to express the data flow.
On the other hand, to support the real-time nature of Uber’s business, we also built a platform to author pipelines for streaming analytics called AthenaX. We could use these for real-time surge calculatuations, fraud detection and so on.
While the tools scaled well to Uber’s demand, the user experience started suffering due to a diverse user base operating on these tools across the globe.
Growing with Uber
As Uber grew across users, businesses, and regions, the ever-increasing demand for newer use cases, workflows, and personas exposed some critical pain points in our existing platforms.
Currently at Uber, almost 40% of workflows fall into two distinct categories:
- An data analysis or data science workflow where users want to create a new table and keep it updated through a sequence of working queries
- An operations workflow where users want to move data between different data serving platforms like Kafka, realtime databases, Hive, Google Sheets, or Amazon S3 for operational insights and analytics.
For both workflows, the majority of our users have the required SQL expertise. But most of these users are not familiar with coding languages and frameworks. Working with a Python framework, code repositories, or a specialized technology like Flink added a significant learning curve for these users. For example, with the use of a Python-based SDK, people have to use declarative SQL queries with imperative Python code. They have to manage that code in its own repository. It is a tedious process for many users.
Consider a scenario where a city operations manager wants to analyze the impact of a new promotional offer that they launched in their city. In terms of query and workflow, all they wanted is to join a couple of tables and export the data to a Google sheet. But this required additional hours or even days for them to figure out the Python code, test the code, get the code reviewed and in production, and then wait for the next deployment cycle. This slowed them down.
For a fast-moving company like Uber, such delays hurt our business. An internal study estimated millions of dollars of productivity loss due to this.
Our users demanded a much simpler, quicker, and intuitive user experience for building data workflows. In true Uber style, our users desired a magical experience.
Guiding principles
As Uber’s data team, we decided to build this experience with three key guiding principles.
- Simplify: Workflow authoring and monitoring is extremely commonplace. We decided to eliminate the learning requirement and tech-savviness needed to create data workflows. We wanted to build an experience that transforms logic into a workflow within minutes.
- Unify: We realized that the availability of real-time data is extremely valuable to the business and its demand would keep increasing. We can realize the power of these insights only if we make it easy to consume. When it came to workflow management, we had to make real-time data a first-class citizen and strive for a unified user experience across batch and real-time workflows.
- Consolidate: We had multiple tools to help customers manage data pipelines causing proliferation and confusion. We had to merge those into one.
Adhering to these principles would prove essential to the product’s success.
Introducing uWorc
We built uWorc, or Universal Workflow Orchestrator, on our guiding principles. It includes a simple drag and drop interface that can manage the entire life cycle of a batch or streaming pipeline, without having to write a single line of code.

As we mentioned, our users needed to move fast from their core SQL or transformation logic to their workflow. We found our inspiration in low-code platforms to bridge that gap. In uWorc, we require absolutely no code to convert a working query to a workflow. Nor do users have to code to move data, for example, from Kafka to a real-time database. Other familiar cloud products such AWS Data Pipeline, or Azure Data Factory also use similar GUI-based workflow for orchestration.
We still drive execution with Airflow and the Flink engines behind the scenes. But now those are background technologies our users do not need to worry about; this saves them from the cognitive burden they felt before.
Building a data workflow in uWorc
To build a workflow, uWorc supports a variety of prebuilt tasks that users can chain together.

Before uWorc, the workflow in Figure 2 took hours to complete and deploy. It now takes less than five minutes in uWorc to complete the same task!
uWorc supports a variety of tasks such as Hive, Spark, PySpark, and bash, with more to come. Beyond simple tasks, uWorc also supports running Jupyter notebooks created in Data Science Workbench. Data scientists can now deploy their notebooks with a single click, along with pre- and post-processing steps such as those in Figure 3.

To manage the lifecycle of workflows uWorc supports:
- Versioning of the workflows with diffs and rollbacks within the tool
- Monitoring the workflows to look for
- Status of old runs
- Resource usage, or CPU and memory consumption, with every run
- Supporting team collaboration with the ability to share workflows with other users
- Rapid development by cloning existing workflows
Under the hood
Simplifying the experience
A typical workflow involves reading from one or more sources, running transformations, and then loading that data into another data sink. One challenge in current open-source platforms such as Airflow or Spark is that they offer programming APIs, but they don’t provide metadata about user configuration. They lack information such as data sources, resource schedulers such as YARN queues, or table permissions.

 Figure 4: A Kafka task displays a list of Kafka topics for users to pick and choose from. A Hive task displays YARN queues.
Figure 4: A Kafka task displays a list of Kafka topics for users to pick and choose from. A Hive task displays YARN queues.
Building a better user experience for developing workflows is not just simplifying programming interfaces with drag and drop. It also brings all of this rich metadata about the resources they access into the editor. With uWorc, all of this information is readily available in the editor.
uWorc architecture
uWorc’s architecture caters to the guiding principles of Simplify, Unify, and Consolidate.
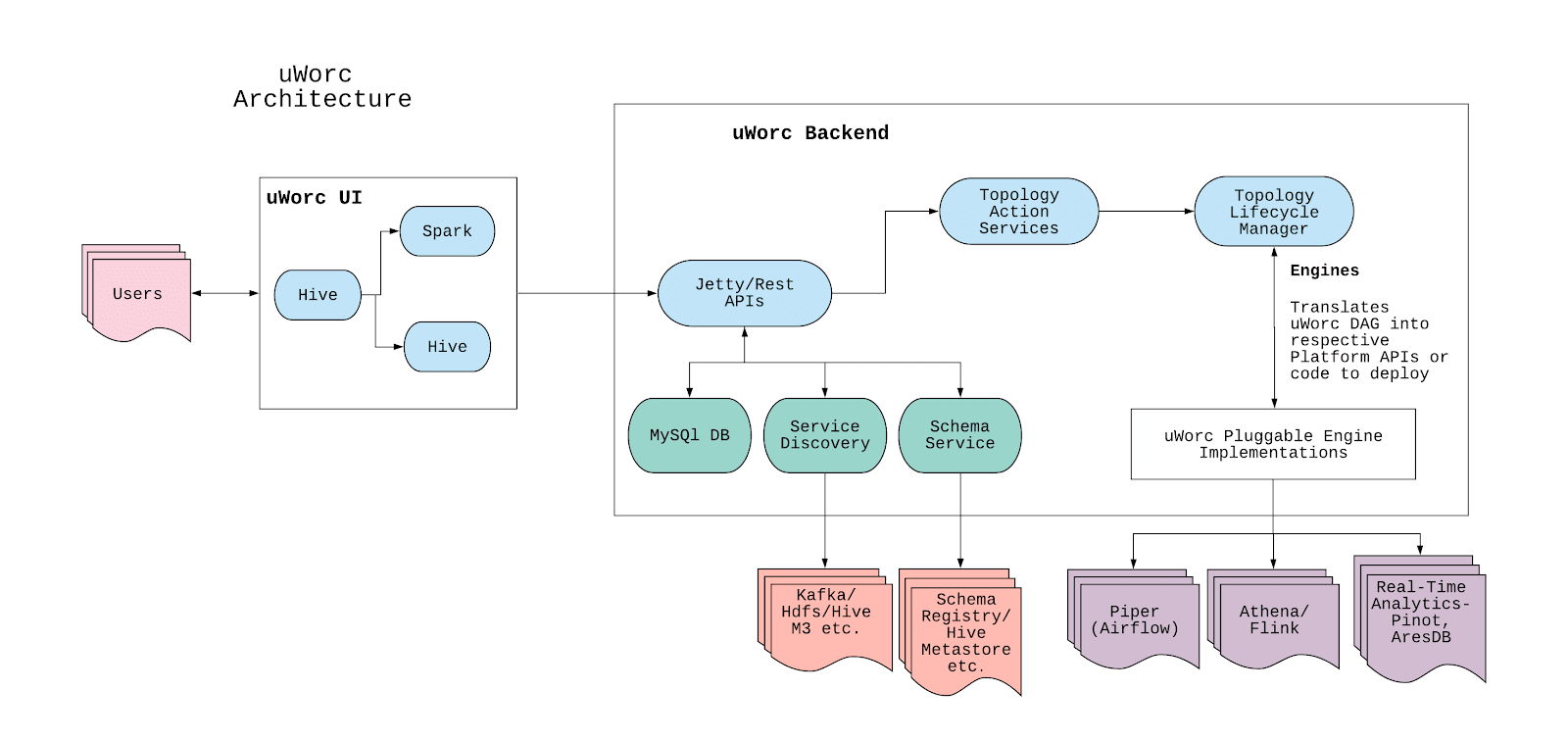
uWorc UI
The uWorc UI enables multiple platforms and engines with different capabilities.
With this in mind, we designed all input forms through configurable templates. If a user wants to add a new component or an entirely new platform or engine with its components, they can do so with JSON templates.

Engine
To enable the unification of various platforms such as batch or streaming, uWorc provides a set of API interfaces to build integrations into platforms. This includes platforms such as Piper, Airflow, and Athena or Flink. We call these platforms engines.
Through this interface, we can manage an entire workflow’s life cycle, from creation, test, to deployment. The engine’s interface provides necessary abstractions to manage platform-specific workflow life cycle management.
Components

A component is a single entity in an Engine that users can drag and drop into the editor and then configure. For example, a Hive task in the Piper or Airflow engine enables users to define their SQL and configure a YARN queue. Similarly a Kafka source in a streaming engine helps users to select a topic from a Kafka cluster. Each engine can have a set of components to build a workflow.
Each component definition has two parts:
- A UI definition so that uWorc UI can render a form to capture the user’s input
- A backend interface to validate the user’s input and generate code for the platform it’s going to deploy on
Once the user builds their workflow DAG and chooses to deploy it, Engine’s implementation goes through the DAG, and generates code from each component’s interface implementation. This helps us to deploy and run the workflow through uWorc in the platform’s native runtime environment.
Component APIs enable user-defined components as well. In the future, uWorc users will be able to develop custom components and make those available to other users as well.
Monitoring
We planned uWorc as a one-stop-shop for all things related to workflows, including monitoring and debugging of workflows.
uWorc provides a pluggable monitoring interface per engine. Through Time Series API queries that you can customize through a JSON template, it’s very easy to build a monitoring dashboard within uWorc.

We are also working on exposing trace logs from the underlying engine to uWorc. This enables users to resolve most of their common problems within uWorc itself.
uWorc success
Since we launched uWorc, we saw steady adoption with a variety of use cases.
Data analysts now commonly use it to create new tables and power their analytics. City operations users create new tables to analyze the impact of local promotions, and data scientists do offline inference and storing their results in Hive tables.
On the streaming side, our users built restaurant dashboards and real-time marketing campaigns to prevent sales funnel drops.
We currently have more than 10,000 workflows, but more importantly uWorc has brought three clear benefits to Uber:
- Simplification – It improved data analyst and data scientist productivity by eliminating the learning curve. Our data users now save hours every week.
- Unification – It provides a unified experience across real time and batch workflows, which makes real-time decision-making simpler.
- Consolidation – It creates a studio-like experience to create, deploy, monitor, and revise a workflow. This further reduces the effort on users.
Moving forward
Looking ahead we see opportunities to further enhance user experience, and to reduce the time it takes to design logic to deliver a robust workflow. Some of the upcoming additions include:
- Creating a workflow from a template for some typical workflows.
- Testing workflows easily before deploying.
- Visualizing workflows that someone created in the SDK. This is because sharing a DAG visualization is ten times easier than imagining it by reading code!
If you’d like to learn more and be a part of our team, check out our careers page
Acknowledgements
We would like to thank our team uWorc and our partner teams Piper, Marmary, Eva and Athena.

Sandeep Karmakar
Sandeep Karmakar is the former lead product manager with Uber’s data and machine learning platform.

Sriharsha Chintalapani
Sriharsha Chintalapani is a Senior Staff Software Engineer and the Tech Lead for Data Platforms at Uber. The Data Quality Platform provides quality checks and alerts to our Data Assets (tables, metrics) at Uber.
Posted by Sandeep Karmakar, Sriharsha Chintalapani
Related articles





Most popular

Top Restaurant Marketing Trends to Try in 2025

Exclusive offer for NSW Seniors Card members

Adopting Arm at Scale: Transitioning to a Multi-Architecture Environment
