
A few years ago, Uber primarily relied on incremental rollout and production probing/alerts to catch regressions. While this approach is sound, it became very operationally expensive and we also experienced many leakages. Detecting issues late requires developers to bisect the exact bad change and then go back through the whole process again.
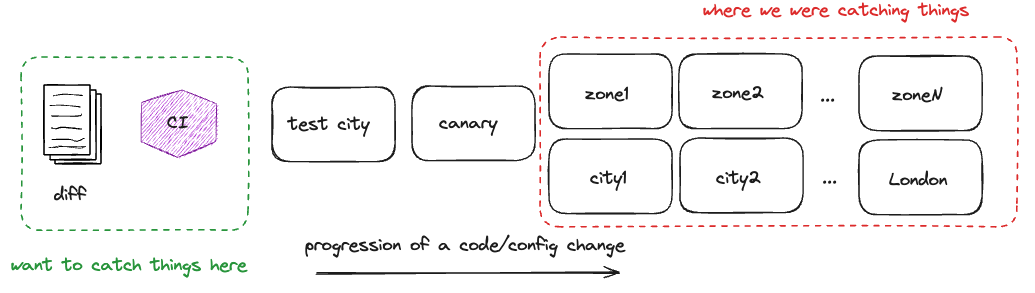
Many of our outage postmortems indicated little to no testing beyond a few basic unit tests, which were often so dependent on mocks that it was difficult to understand how much protection they actually offered.
Uber is well-known for having fully embraced microservice-based architecture. Our core business logic is encapsulated across large groups of microservices such that it is difficult to validate functionality within a single service without over-mocking. Because of our architecture, the only sane way to test has been to perform E2E testing. At the same time, our internal NPS surveys consistently highlighted that E2E testing was the hardest part of the job for developers – it’s no surprise it was often skipped.
A well-known testing blog from 2015, Just Say No To More End-To-End Tests, calls out E2E tests as difficult to maintain, expensive to write, flaky, slow, and difficult to debug. Uber’s journey into testing has run into all of the above problems and we’ve had to come up with creative ways to solve them.
In this blog, we describe how we built a system that gates every code and configuration change to our core backend systems (1,000+ services). We have several thousand E2E tests that have an average pass rate of 90%+ per attempt. Imagine each of these tests going through a real E2E user flow, like going through an Uber Eats group order. We do all this fast enough to run on every diff before it gets landed.
Prior Approaches
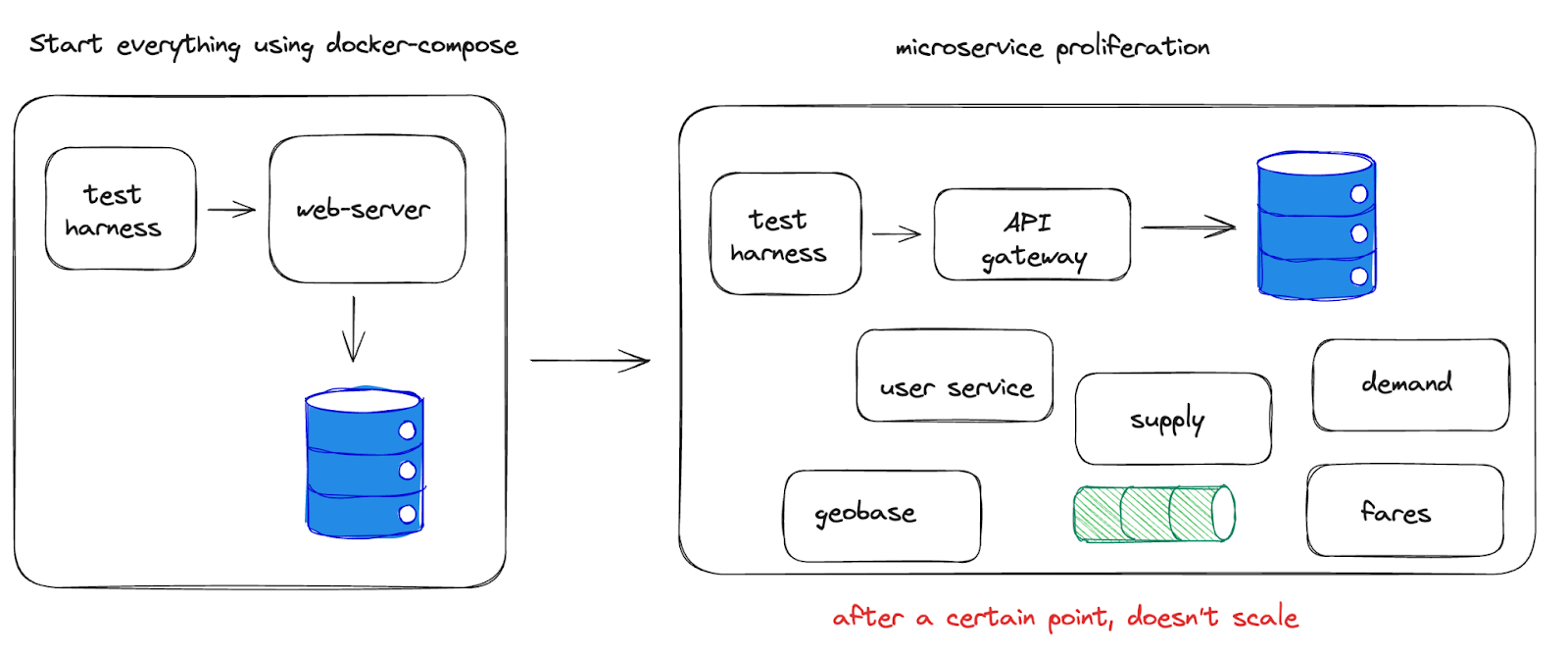
Docker Compose
In the past, some teams at Uber have tried to start up all relevant services and datastores locally to run a suite of integration tests against the stack. At a certain point of microservice complexity, this becomes prohibitively expensive with the number of containers that need to be started.
Deploy to staging
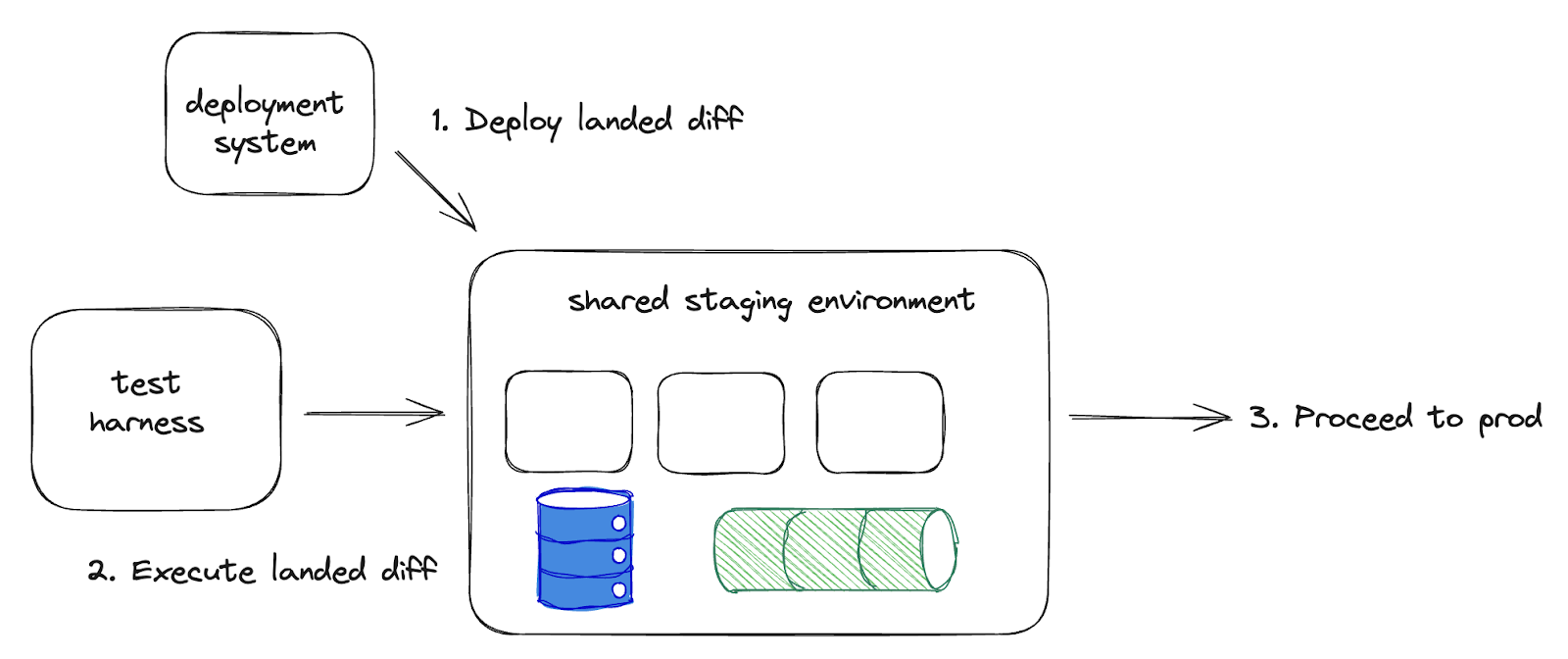
At Uber, shared staging became too difficult to keep reliably usable for testing, because a single developer deploying a bad change could break the whole thing for everyone else. This approach only ever worked in small domains where developers could manually coordinate rollouts between a few teams.
Could E2E tests really work well at Uber scale? This is the story of how we made it happen.
Shift Left with BITS – Uber’s Current Testing Strategy
We use BITS to slice production
In order to shift testing left, we need to enable the ability to test changes without first deploying to production. To solve this, we launched a company-wide initiative called BITS (Backend Integration Testing Strategy) that enables on-demand deployment and routing to test sandboxes. Practically, this means individual commits can be tested in parallel before landing, without interfering with anyone else!
Data Isolation
To shift testing left safely, we need to provide isolation between production and testing traffic. At Uber, production services are expected to receive both testing and production traffic.
User Context
Most APIs are entity-scoped, meaning that access is scoped to a particular entity (i.e. user account). Using test users automatically limits the scope of side effects to that account. A small handful of cross-entity interactions (think algorithmic matching or Eats shopping) use the below strategies for isolation.
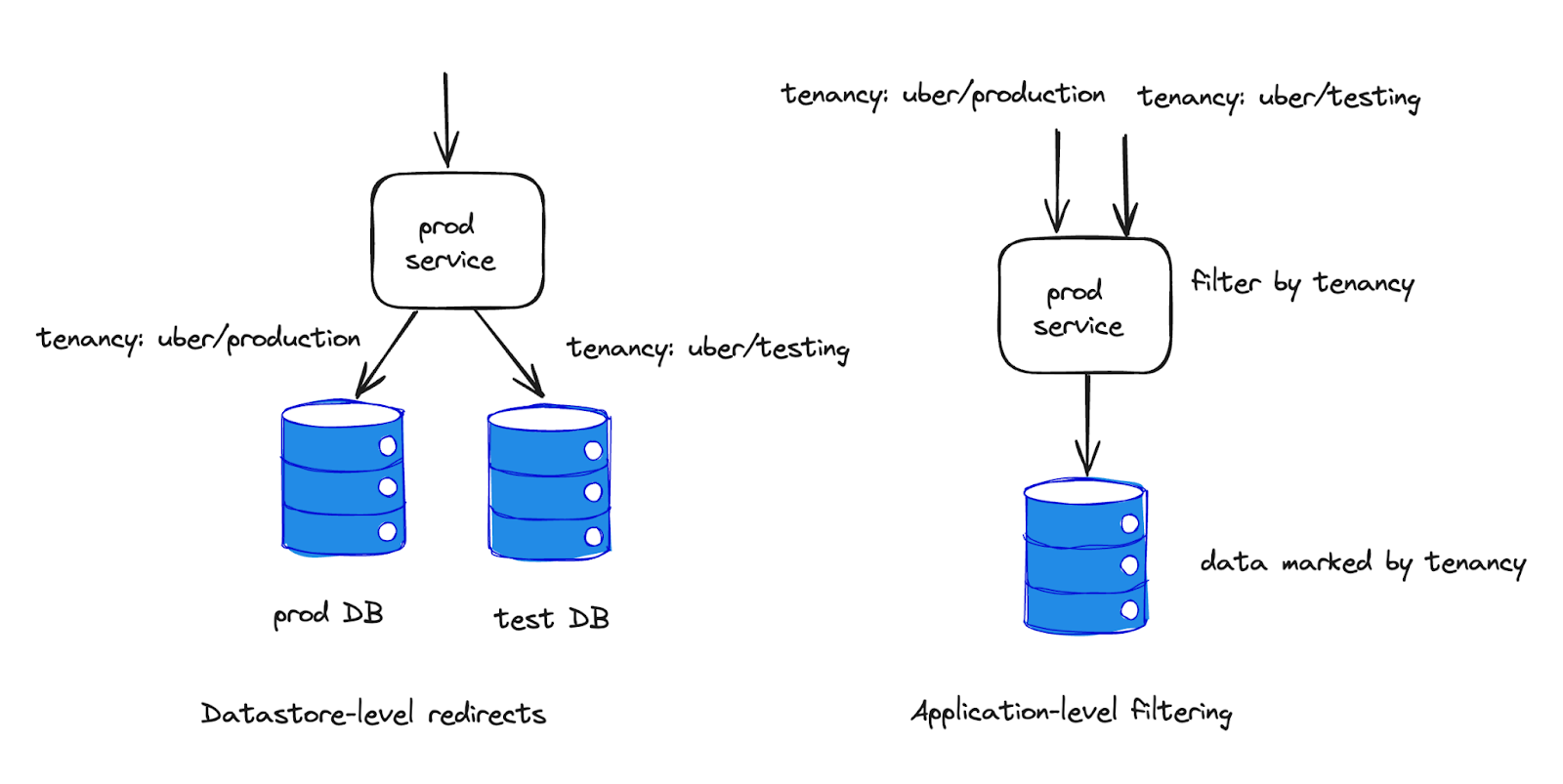
1. Storage clients route testing traffic to a logically separated datastore
2. Data is saved to the prod DB with a tenancy column; range-based queries also pass a tenancy identifier for filtering
Architecture
BITS’ architecture can be expressed as a series of workflows that orchestrate between different infrastructure components to define a meaningful experience for the developer. We use Cadence, an open-source workflow engine developed at Uber that gives us a programming model for expressing retries, workflow state, and timers for teardown of resources.
Our CI workflows run test/service selection algorithms, build and deploy test sandboxes, schedule tests, analyze results, and report results. Our provisioning workflows control container resource utilization and scheduling of workloads across different CI queues optimized for particular workload types (i.e., high network usage vs. CPU usage).

*We’ve previously discussed SLATE, a sister project built on top of BITS infrastructure primitives for performing manual sanity testing. Check out SLATE if you haven’t already seen it!
Infrastructure Isolation
We’ve done a lot of work to properly isolate BITS’ development containers against production side effects.
- BITS test sandboxes do not receive any production traffic.
- The native Apache Kafka™ protocol at Uber is abstracted by a consumer proxy that remaps messages into a push-based forwarding model over gRPC. This design allows for intelligent routing of messages to BITS test sandboxes and also prevents test sandboxes from inadvertently polling production topics.
- Cadence workflows created from testing are isolated to the test sandbox.
- Metrics and logs are tagged with tenancy, so that they can be filtered out.
- Test sandboxes do not participate in production leader election protocols.
- SPIFFE™ and SPIRE™ provide strongly attested identities to BITS sandboxes and test traffic.
- Uber’s forwarding proxy inspects requests and performs a conditional P2P redirect if routing overrides are detected.

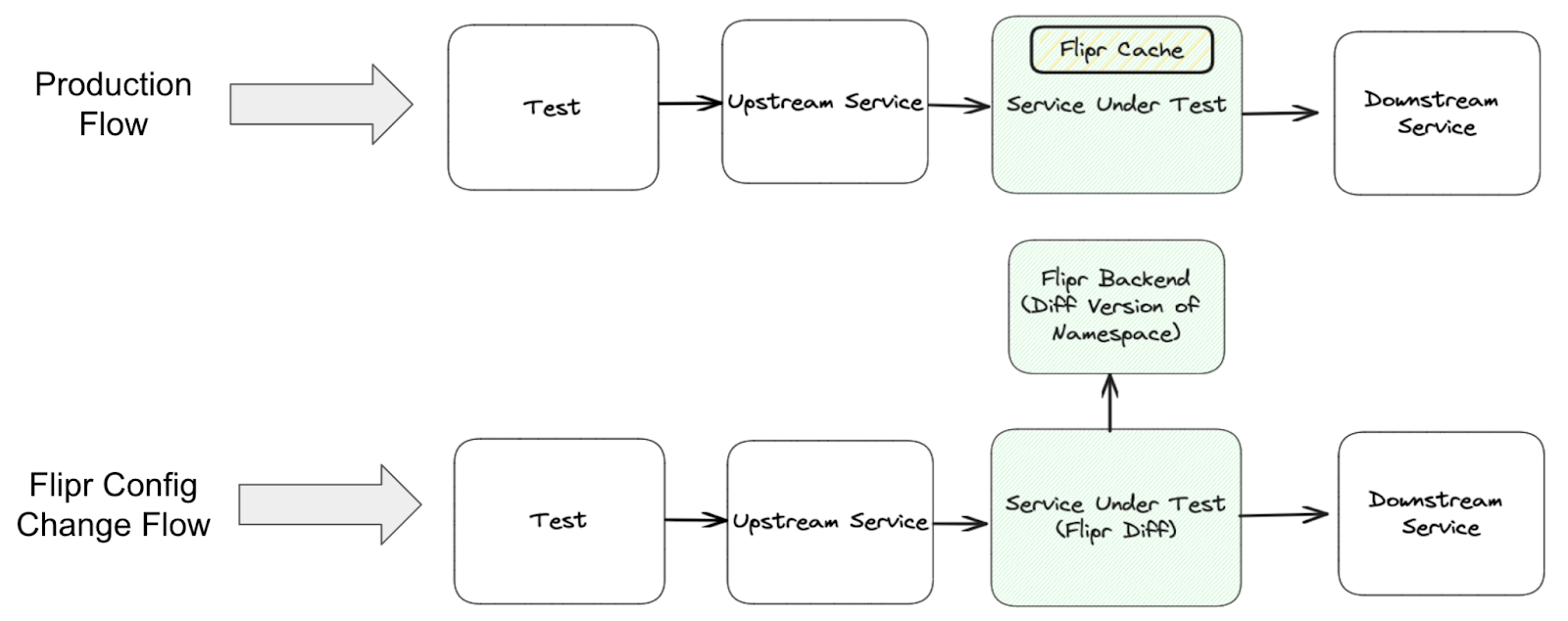
Testing Configuration Changes
At Uber, configuration changes cause up to 30% of incidents. BITS also provides test coverage for configuration rollouts made in our largest backend config management system, Flipr.
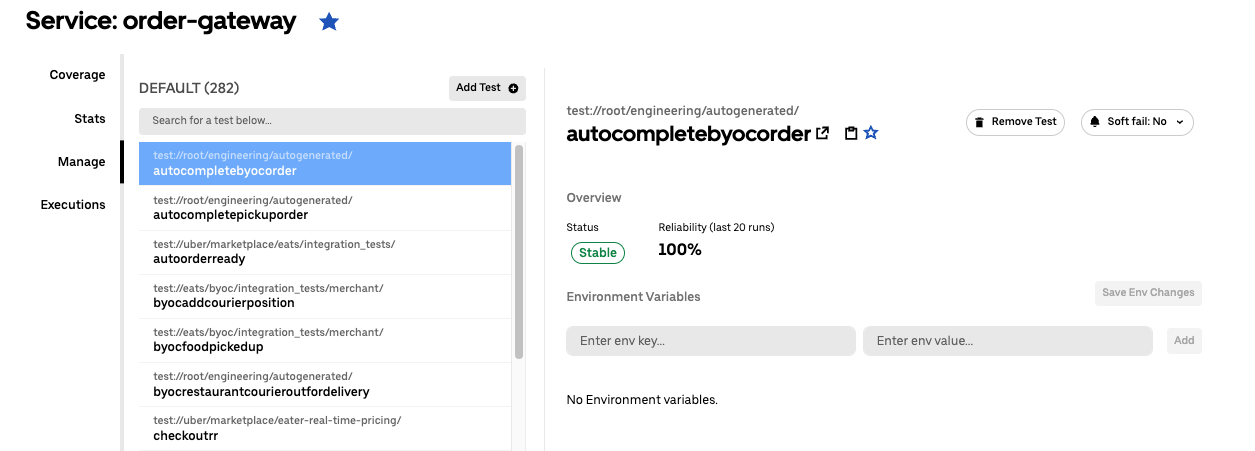
Test Management
Developers are able to manage their test suites in real time from our UI to perform actions like downtiming tests, tracking their health, and checking endpoint coverage of their services.
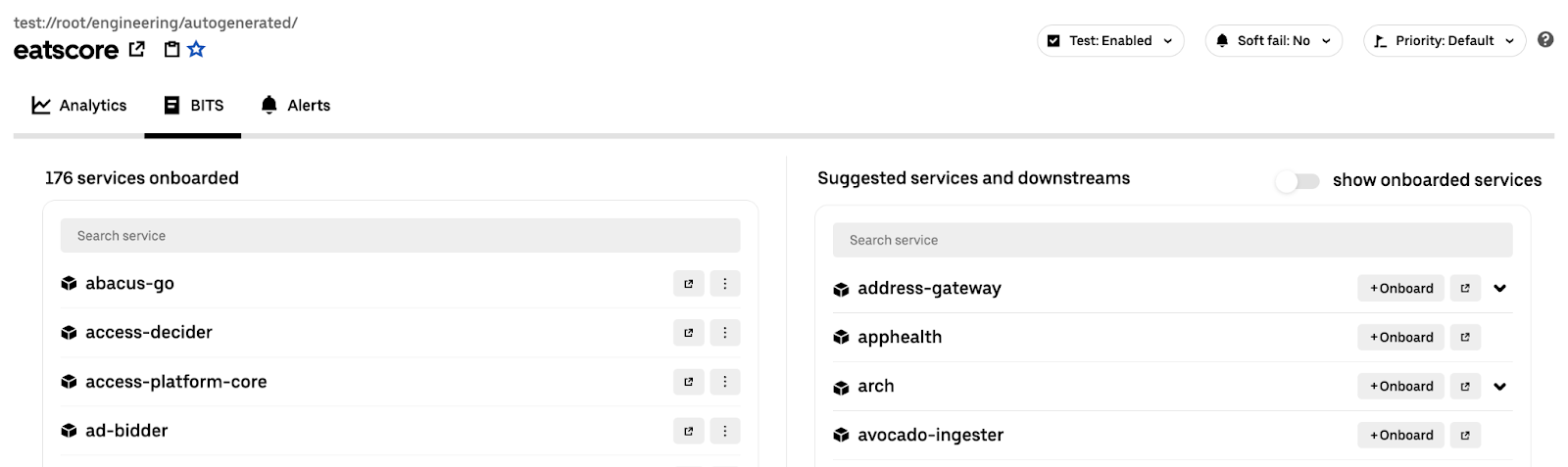
Trace Indexing
Every test execution is force-sampled with Jaeger™. After each test execution, we capture the “trace” and use it to build several indexes:
- What services and endpoints were covered by the test flow
- What tests cover each service and endpoint
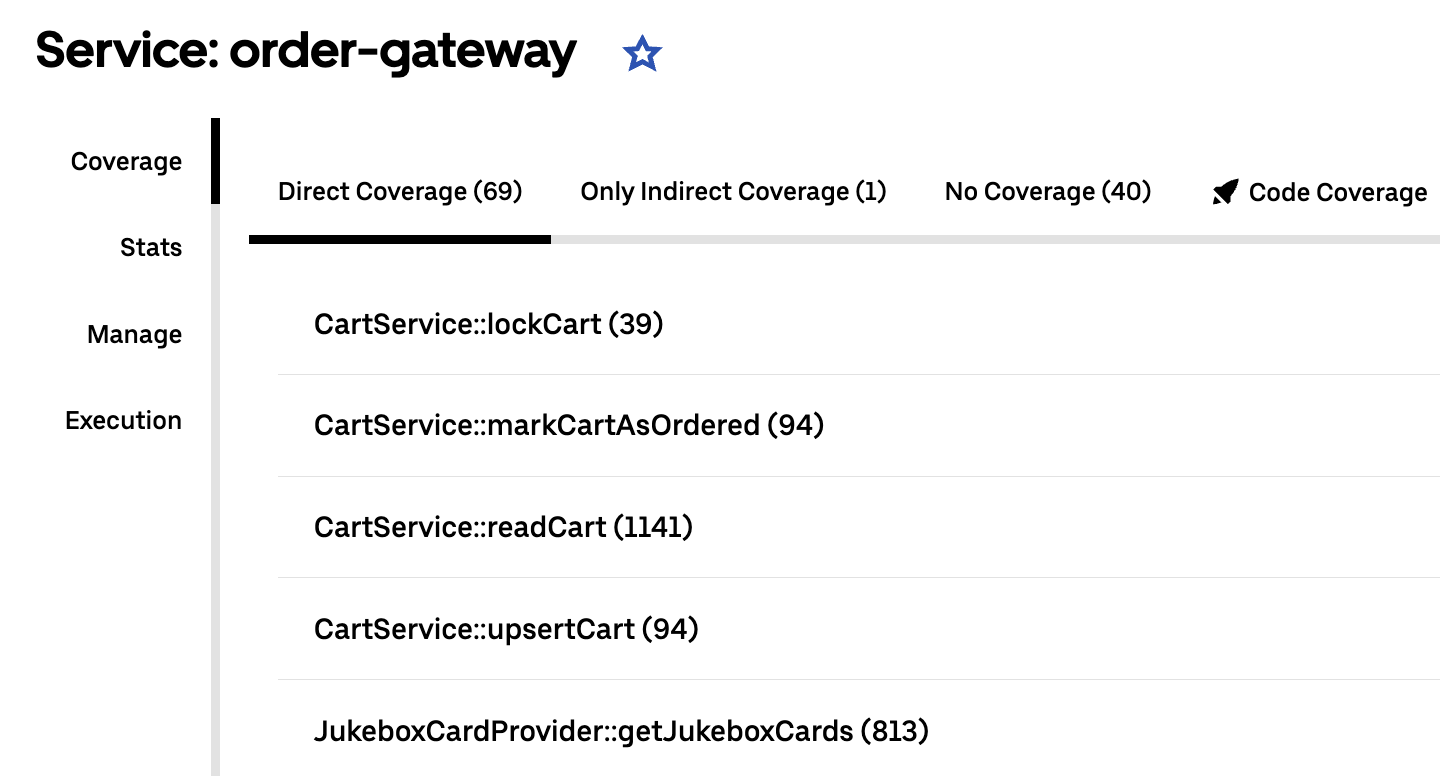
These indexes are used to surface endpoint coverage metrics for teams, but more importantly, they allow us to intelligently determine which tests need to run when a given service is changed.
Getting the infrastructure right has always been the easier part of the problem of testing. Machine problems can be solved, but developers at Uber are very sensitive to degradations in productivity and experience. The below captures some of our strategies around mitigating problems with test maintenance, reliability, and signal.
Challenges
Challenge #1: Maintenance, state, and fixture management
Let’s say that you want to test forward dispatch, where a driver gets a new pickup request before they complete their current dropoff. Or shared rides, where you may or may not pick up another rider on the way to your destination. How do you represent the state of the trip in each situation?
Composable Testing Framework (CTF)
A foundational building block we built is CTF, a code-level DSL that provides a programming model for composing individual actions and flows and modeling their side effects on centralized trip state. CTF was originally developed to validate Uber’s Fulfillment Re-architecture and has since been adopted across the company.
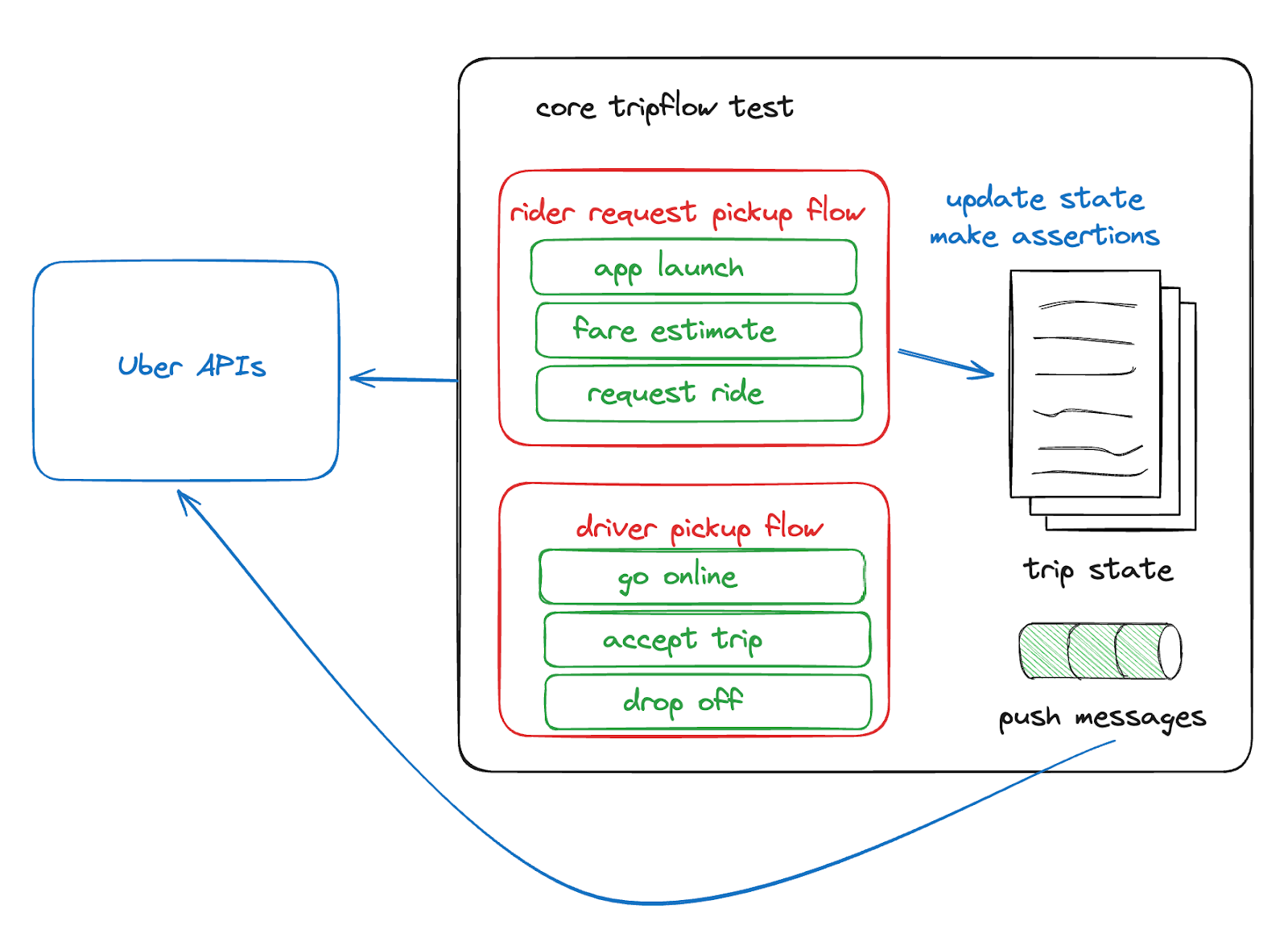
Test Cataloging
Every test case is automatically registered in our datastore on land. Analytics on historical pass rate, common failure reasons, and ownership information are all available to developers who can track the stability of their tests over time. Common failures are aggregated so that they can be investigated more easily.
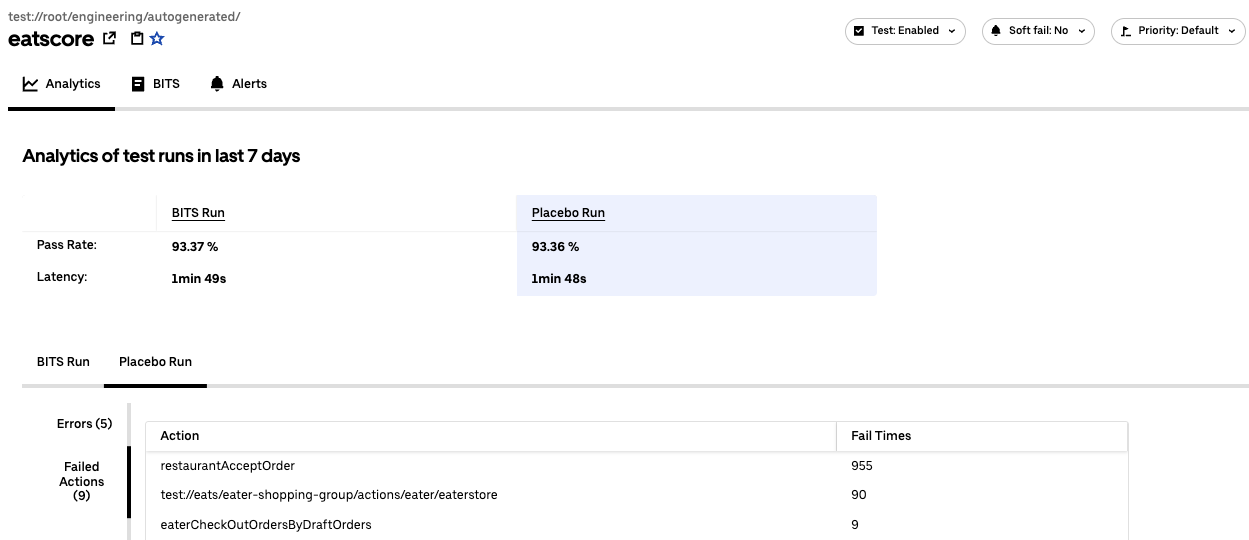
Challenge #2: Reliability and Speed
Test authors get their tests to pass at ≥90% per attempt (against main). Our platform then boosts this to 99.9% with retries.
Our largest service has 300 tests. If tests individually pass at 90% per attempt, there is a 26% chance of one test failing due to non-determinism. In this case, we got the 300 tests to pass at 95% and with retries boost the signal up to ≥99%.
The above is repeated thousands of times a day, debunking the myth that E2E tests can’t be stable.
Latency
Our tests directly hit Uber APIs, so the majority of them run in sub-minute time.
Challenge #3: Debuggability and Actionability
Placebo Executions
On every test run, we kick off a “placebo” parallel execution against a sandbox running the latest main branch version of code. The combination of these two executions allows us to move beyond a binary signal into a truth table:

With retries, non-determinism is rare. Either production or your test is broken, or you’ve introduced a real defect. No matter what, the developer has a clear action.
Automated quarantining of tests
The pass rate of our tests follows a bimodal distribution–the vast majority of tests are very reliable. A small subset of tests are broken (consistently fail). An even smaller subset of tests pass non-deterministically.
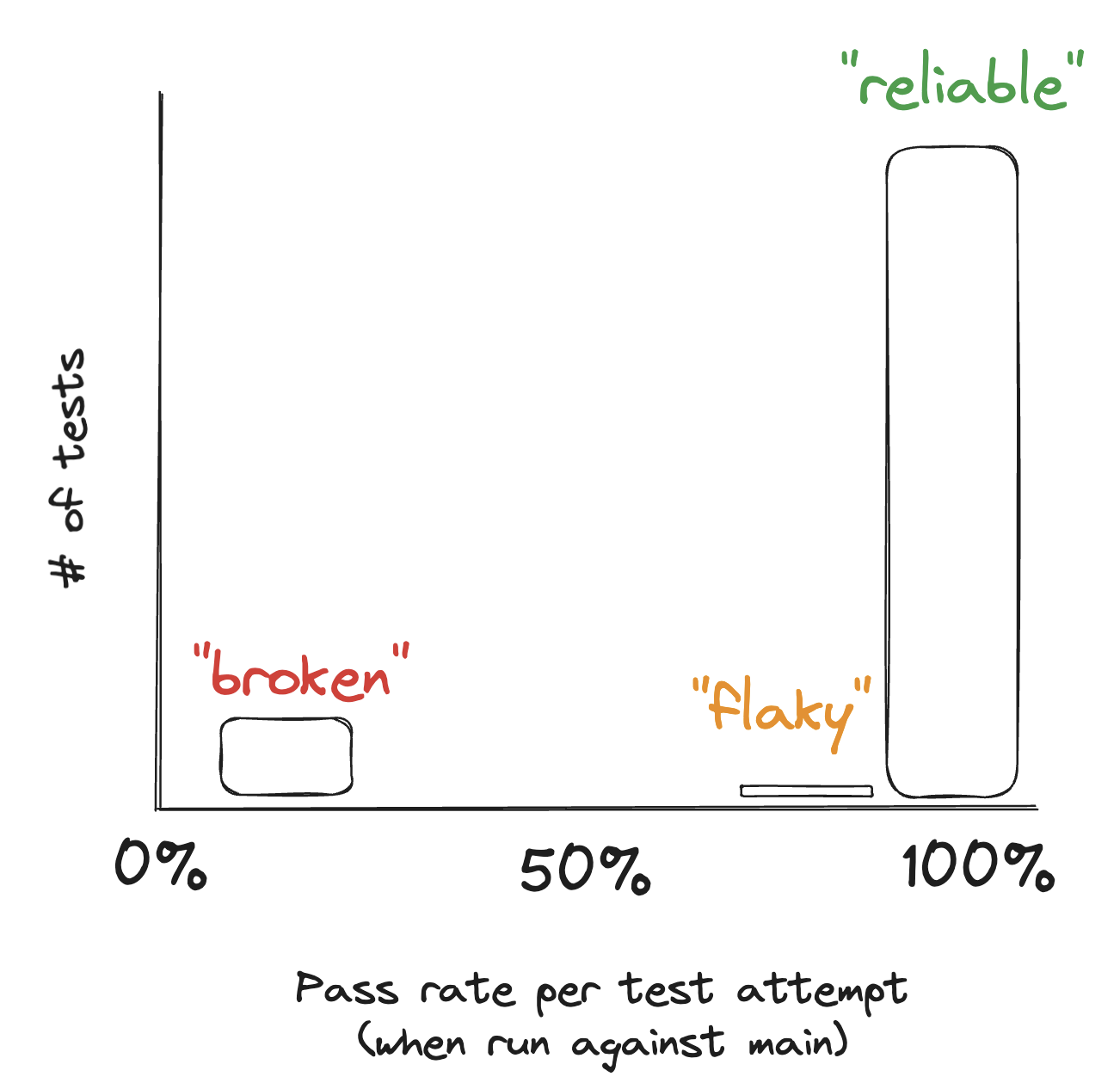
A single broken test can block CI/CD, so we take special care to guard against this. Once a test drops below 90% placebo pass rate, it is automatically marked non-blocking and a ticket and alert are automatically filed against the owning team. Our core flow and compliance tests are explicitly opted out of this behavior, given their importance to the business.
Conclusion
At the end of the day, testing requires a balance between quality and velocity. When tuned well, developers spend less time rolling back deployments and mitigating incidents. Both velocity and quality go up. As part of our testing efforts, we tracked incidents per 1,000 diffs and we reduced this by 71% in 2023.
Testing is a people problem as much as it is a technical problem
Microservice architecture was born out of a desire to empower independent teams in a growing engineering organization. In a perfect world, we would have clean API abstractions everywhere to reinforce this model. Teams would be able to build AND test without impacting other teams. In reality, shipping most features at Uber requires heavy collaboration–E2E testing is a contract that enforces communication across independent teams, which inevitably breaks down because we’re human!
Testing and Architecture are intrinsically linked
No one at Uber intentionally planned for heavy reliance on E2E testing, but our microservice-heavy architecture and historical architectural investments in multi-tenancy paved the way to make this the best possible solution.
Trying to fit our testing strategy to the classic “Testing Pyramid” didn’t work for us at Uber. Good testing requires you to think critically about what you’re actually trying to validate. You should try to test the smallest set of modules that serve some meaningful user functionality. At Uber, that just happens to often involve dozens of services.
Acknowledgments
We are thankful to a dozen+ teams who have collaborated with us to make testing a first-class citizen in Uber Infrastructure, as well as all the various leaders who believed in the BITS initiative.
Apache®, Apache Kafka, Kafka, and the star logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
SPIFFE, OpenTelemetry and its logo are registered trademarks of The Cloud Native Computing Foundation® in the United States and other countries. No endorsement by The Cloud Native Computing Foundation is implied by the use of these marks.
Jaeger and its logo are registered trademarks of The Linux Foundation® in the United States and other countries. No endorsement by The Linux Foundation is implied by the use of these marks.

Quess Liu
Quess Liu is a Senior Staff Engineer on the Developer Platform team. Over the past 3 years, he has led efforts to redefine microservice development and testing, with a particular focus on evolving Uber’s infrastructure and architecture to be more testable..

Daniel Tsui
Daniel Tsui is a Senior Engineering Manager on the Developer Platform team. Over the past 9 years, He has built Uber’s testing infrastructure from scratch and has led his teams to shift testing left at scale.
Posted by Quess Liu, Daniel Tsui
Related articles


Most popular

How Uber Uses Ray® to Optimize the Rides Business

MySQL At Uber

Adopting Arm at Scale: Bootstrapping Infrastructure
Uber Auto is now on SaaS – What does that mean for riders?
Products
Company