
Introduction
A well-crafted prompt is essential for obtaining accurate and relevant outputs from LLMs (Large Language Models). Prompt design enables users new to machine learning to control model output with minimal overhead.
To facilitate rapid iteration and experimentation of LLMs at Uber, there was a need for centralization to seamlessly construct prompt templates, manage them, and execute them against various underlying LLMs to take advantage of LLM support tasks.
To meet these needs, we built a prompt engineering toolkit that offers standard strategies that encourage prompt engineers to develop well-crafted prompt templates. It also provides functionality to enrich these templates with context obtained from RAG (Retrieval-Augmented Generation) and runtime feature datasets.
The centralized prompt engineering toolkit enables the creation of effective prompts with system instructions, dynamic contextualization, massive batch offline generation (LLM inference), and evaluation of prompt responses. Furthermore, there’s a need for version control, collaboration, and robust safety measures (hallucination checks, standardized evaluation framework, and a safety policy) to ensure responsible AI usage.
This blog post gives an overview of the prompt template lifecycle, the architecture used to build the prompt toolkit, and the production usage of the toolkit at Uber.
Goals
When we built the prompt toolkit, our goals were that users at Uber could:
- Explore all the available LLM models
- Search and discover all the prompt templates
- Create and update prompt templates and tune parameters with access control
- Iterate on prompt template through code review and revision control
- Generate batch offline generation by applying RAG and testing datasets with different LLM models for LLM inference
- Evaluate prompt templates via offline evaluation through testing dataset and online evaluation
- Monitor prompt template performance with LLMs in production to detect regressions and continuously monitor LLM quality through systematic tracking
Prompt Engineering Lifecycle
The prompt engineering lifecycle consists of two stages: the development stage and the productionization stage. Users interact with the prompt toolkit during each of these stages.
Development Stage
The development stage has three phases: LLM exploration, prompt template iteration, and evaluation.
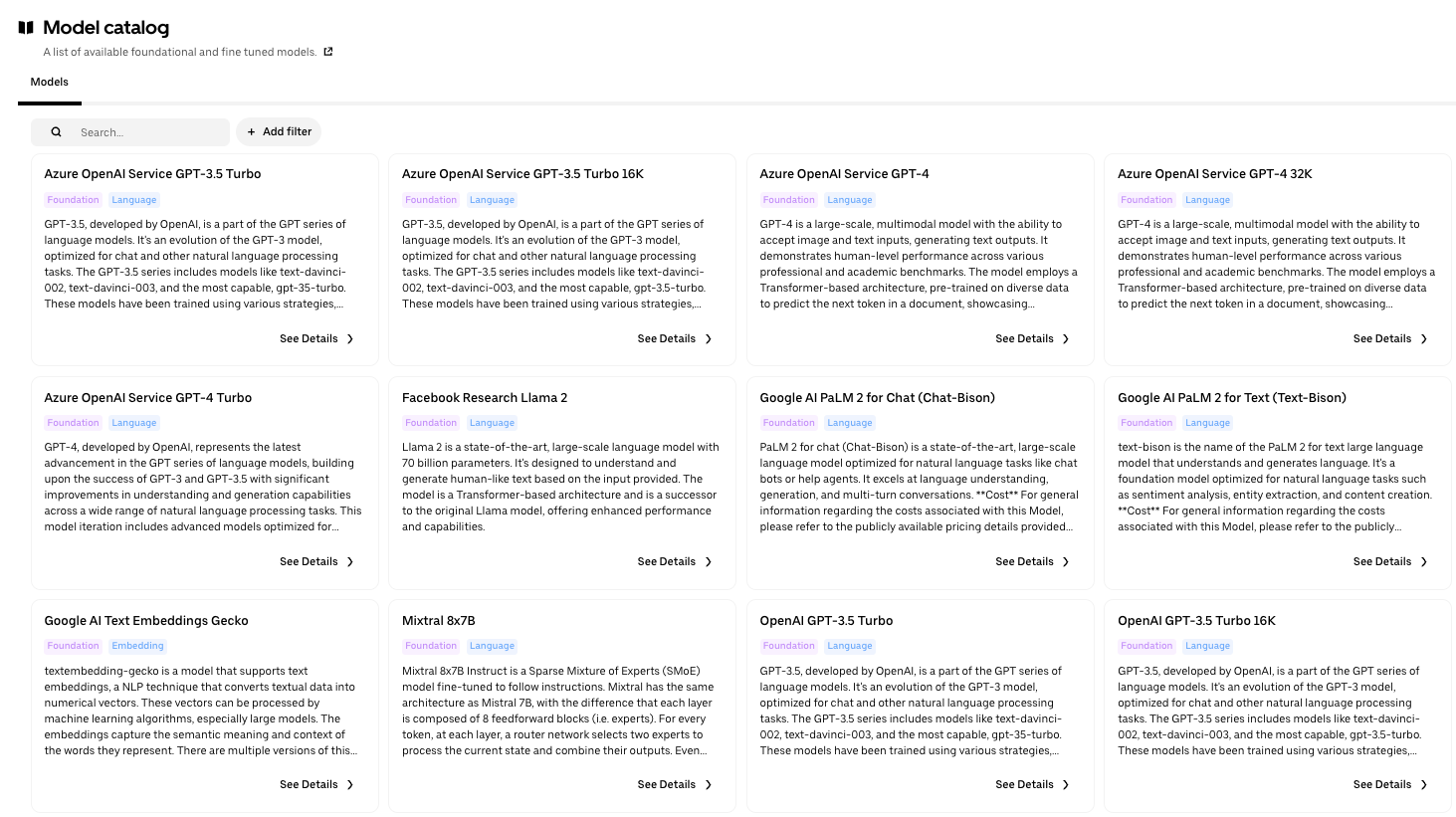
In the LLM exploration phase, users interact with a model catalog and Uber’s GenAI Playground. A model catalog is a model repository that contains all the available LLM models and its corresponding description, metrics, and usage guide. The GenAI Playground helps users explore the capabilities of different LLMs available at Uber and test their use case applicability. Users explore available LLM models from a model catalog and test LLM responses with prompts in the GenAI playground.
In the prompt template iteration phase, users pinpoint their specific business needs, gather sample data, create/analyze/test prompts with LLM models and datasets, assess the responses, and make revisions as needed. Auto-prompting suggests prompt creation so users don’t need to create the prompt template from scratch. With a prompt template catalog, users can explore and reuse the existing prompt templates. In this phase, users perform continual experimentation and iteration.
In the evaluation phase, users evaluate the effectiveness of the prompt template by testing it with a more extensive dataset to measure its performance. It could leverage LLM as a judge or leverage a customized code-based LLM evaluator to evaluate the performance of the prompt template.
Productionization Stage
In the productionization stage, users only productionize the prompt template that passed the evaluation threshold on an evaluation dataset.
Users track and monitor usage in a production environment, collecting data on system usage. This data can inform further enhancements to the process.
Architecture
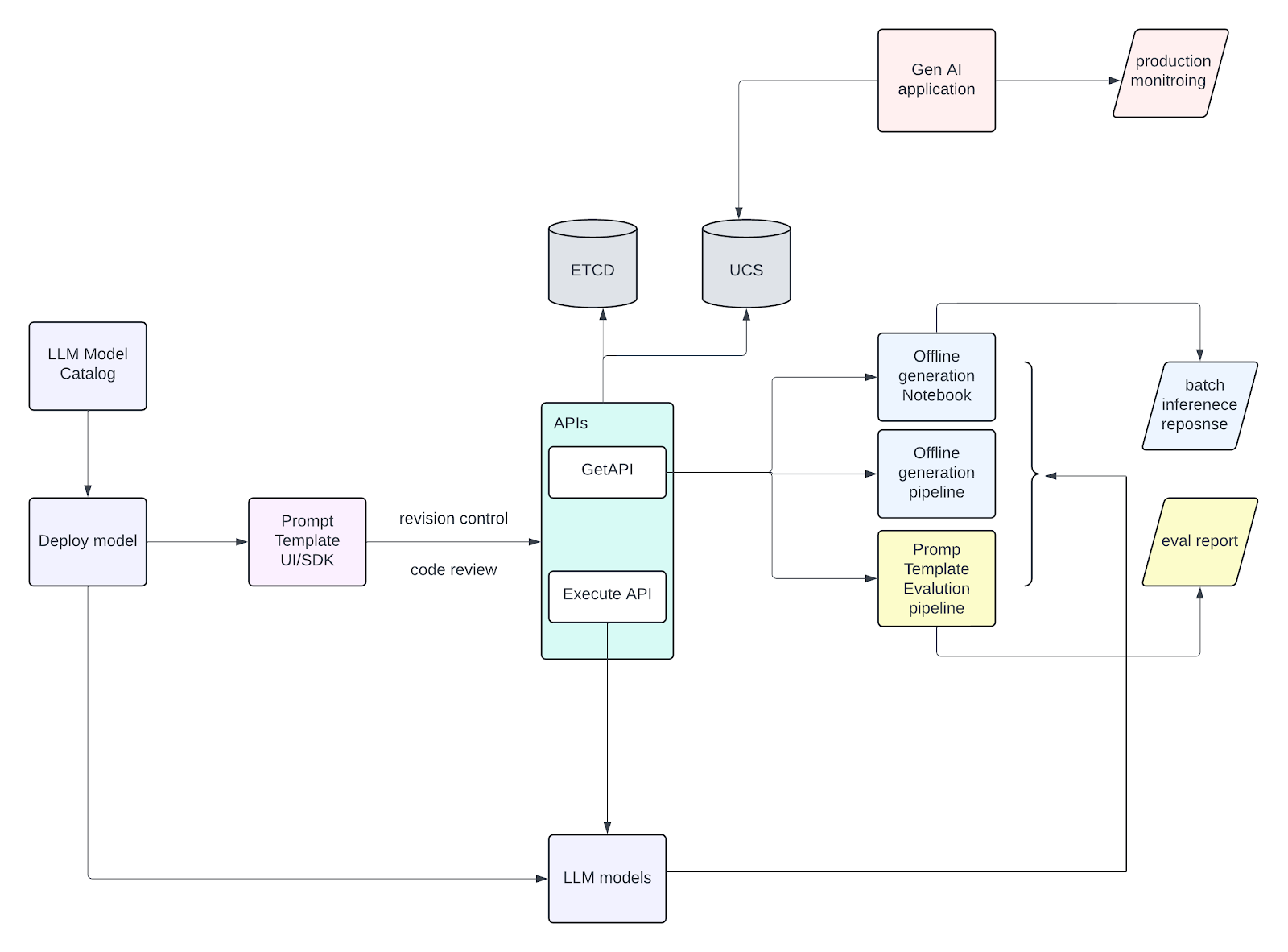
With the prompt engineering toolkit, various components interact to facilitate LLM model deployment, prompt evaluation, and batch inference responses.
The toolkit is composed of a Prompt Template UI/SDK that manages prompt templates and their revisions. The Prompt Template UI/SDK integrates with APIs like GetAPI and Execute API. These APIs interface with the LLM models deployed from the LLM Model Catalog. Models and prompts are stored in ETCD and UCS (object configuration storage), which are then used in an Offline Generation Pipeline and a Prompt Template Evaluation Pipeline.
UI/Design
Users first interact with the prompt toolkit in Gen AI Playground. Gen AI Playground is designed to interface seamlessly with the Model Catalog, a comprehensive repository of large language models available at Uber. This platform allows users to explore detailed specifications, expected use cases, cost estimations, and performance metrics for each model. Within the Gen AI Playground, users can select any model from the catalog, craft custom prompts, and adjust parameters, such as temperature, to evaluate the model’s responses during the ideation stage.
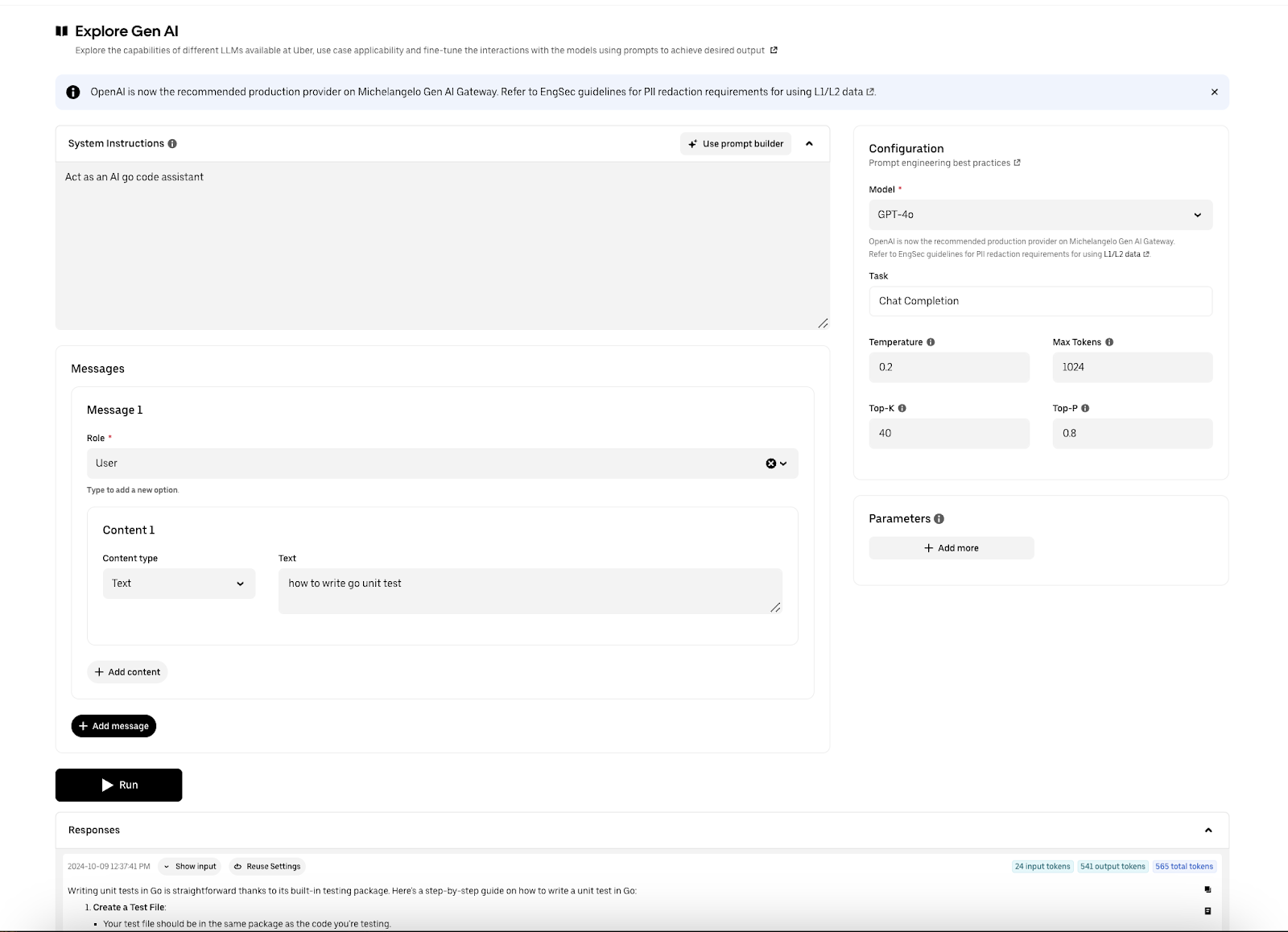
Prompt Template Creation
The prompt toolkit prompt builder automatically creates prompts for users and helps them discover advanced prompting techniques tailored to their specific AI use case. The auto-prompt builder, built on top of the Langfx framework (an Uber internal Langfx service built on top of LangChain™), follows these steps:
1. Prompt engineering best practices: Incorporates the best practices for context RAG retrievers.
2. Prompt builder instructions and examples: Provides a template listing detailed instructions and few-shot examples to help LLMs craft user prompts.
3. Leverage LLM models: Utilizes LLM models to auto-generate suggested prompts, acting as a creator to assist users in prompt generation.
Advanced Prompt Guidance
The prompt builder leverages these principles to create prompts.
| Technique | Prompt Principle for Instructions |
| CoT (Chain of thought), introduced by Wei et al. (2022) | CoT (Chain-of-thought) prompting enables complex reasoning capabilities through intermediate reasoning steps. You can combine it with few-shot prompting to get better results on more complex tasks that require reasoning before responding. |
| Auto-CoT (Automatic Chain of Thought), introduced in Zhang et al. (2022) | Use leading words like “think step by step.” Specify the steps required to complete a task. This is an approach to eliminate manual efforts by leveraging LLMs with the “Let’s think step by step” prompt to generate reasoning chains for demonstrations one by one. |
| Prompt chaining | Prompt chaining can be used in different scenarios involving several operations or transformations. |
| ToT (Tree of thought) | Yao et el. (2023) and Long (2023) proposed Tree of Thoughts (ToT). This framework generalizes chain-of-thought prompting and encourages the exploration of thoughts that serve as intermediate steps for general problem-solving with language models. |
| Automatic prompt engineer | Zhou et al. (2022) proposed APE (automatic prompt engineering), a framework for automatic instruction generation and selection. The instruction generation problem is framed as natural language synthesis addressed as a black-box optimization problem using LLMs to generate and search over candidate solutions. |
| Multimodal CoT prompting | Zhang et al. (2023) proposed a multimodal chain-of-thought-prompting approach. Traditional CoT focuses on the language modality. In contrast, Multimodal CoT incorporates text and vision into a two-stage framework. The first step involves rationale generation based on multimodal information. This is followed by the second-phase, answer inference, which leverages the informative generated rationales. |
Revision Control
Prompt template iteration follows code-based iteration best practices. Users could modify the instruction and model parameters for testing responses, testing it out with a test dataset. A code review is needed for every iteration of the prompt template. Once approved and landed, a new prompt template revision gets created.
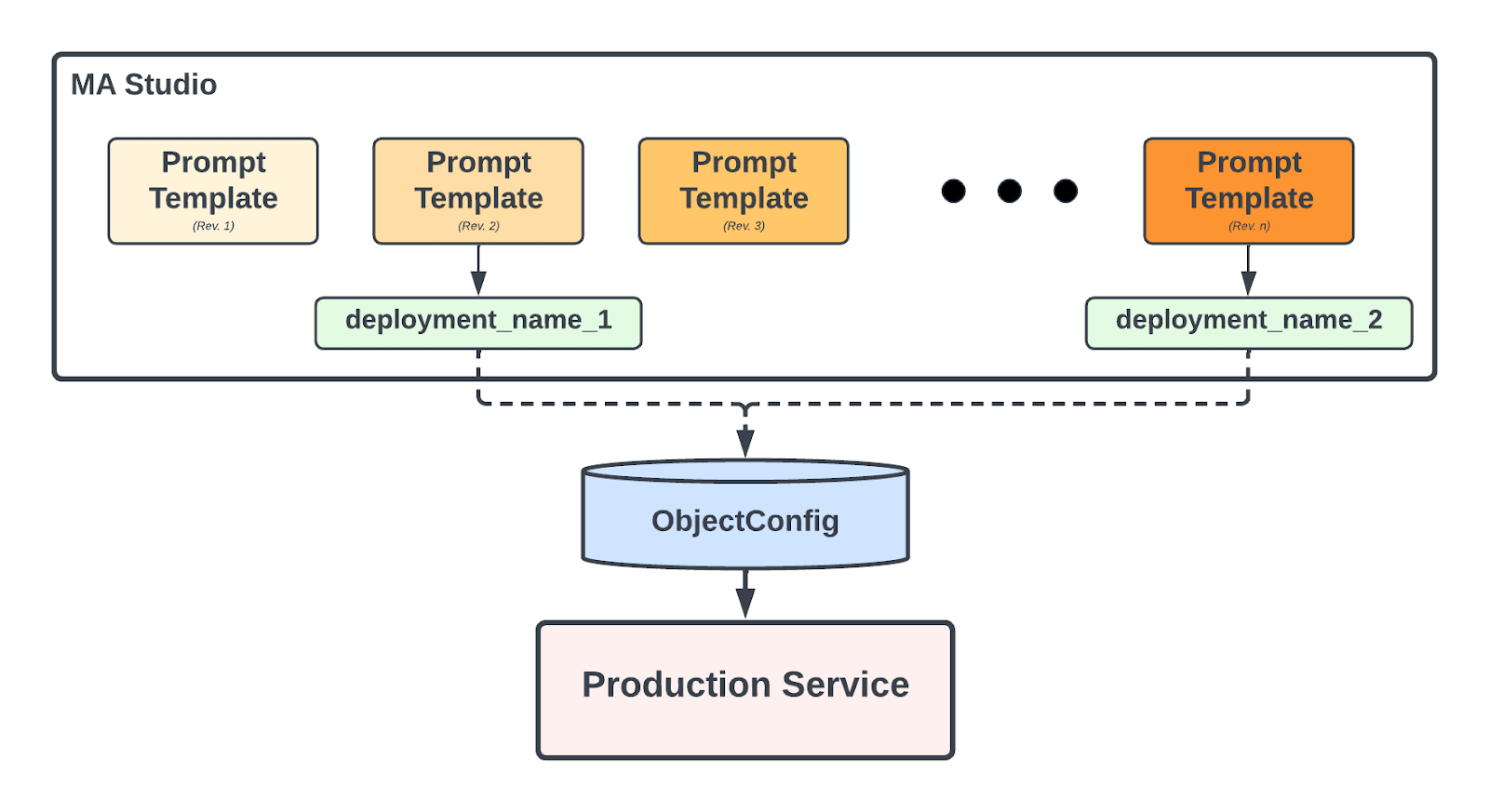
Furthermore, for the production serving flow, users may prefer not to have their prompt template in the production altered with each update. A user could inadvertently introduce errors in their revisions; therefore, deploying the prompt template should follow a structured process.
We support a system where the prompt template can be deployed under an arbitrary deployment name, allowing users to “tag” their preferred prompt template for the production model. This prevents an accidental change of prompt template in their production service. This deployed prompt template is disseminated through ObjectConfig, which is an internal configuration deployment system at Uber. With this safe deployment with explicit deployment revision tagging and universal configuration synchronization (with the ObjectConfig system), the user application in the production service fetches the prompt template upon its deployment.
Prompt Template Evaluation
Several components are involved in the process to evaluate the performance of one or more prompt templates along with their LLM models, model parameters, and context.
For evaluation mechanisms, two methods can be employed:
- Using an LLM as the evaluator (LLM as Judge). This type of evaluation is particularly useful for tasks where subjective quality or linguistic nuances are important, such as generating text that should be engaging, persuasive, or stylistically specific.
- Using custom, user-defined code to assess performance. Specific metrics and criteria are coded and used to automatically evaluate the performance of an LLM. This method is beneficial because it can be highly tailored to the specific aspects of performance one wishes to measure.
The toolkit also offers prompt templates. The evaluation prompt template is a straightforward, user-friendly prompt template detailing the instructions for evaluation. It includes brief examples, metrics, and the format for responses. The production prompt template offers the same, but for production use. This template gets hydrated during production runtime and is the one for performance evaluation.
When evaluating prompt templates, input dataset options include a golden dataset with labeled data specifically for evaluation and a dataset derived from production traffic, also used for evaluation purposes. Each template gets evaluated considering its specific instructions, context, involved models, and model parameters.
To provide a high-level comparison of different prompt templates’ effectiveness, aggregated metrics get generated by applying the prompt templates across a large dataset.
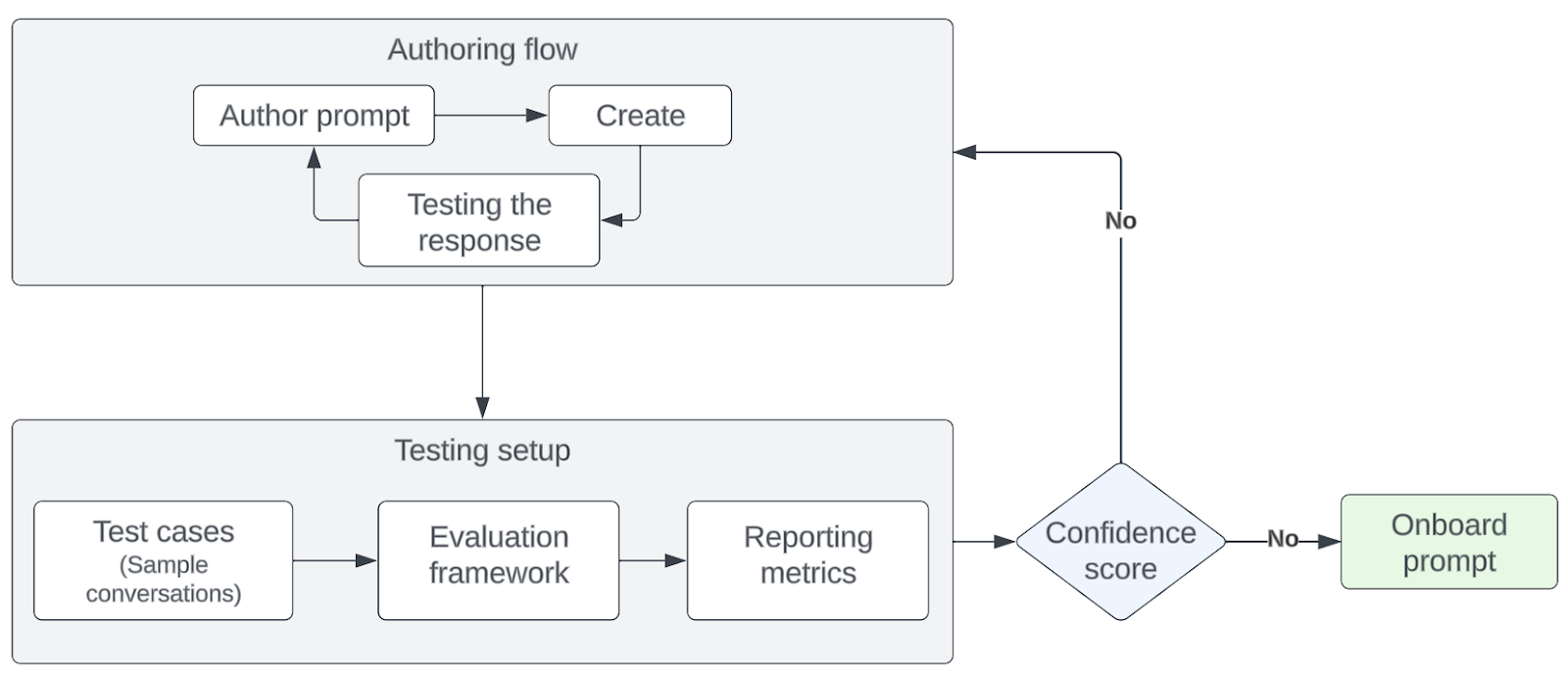
Use Cases at Uber
Let’s see how the prompt toolkit works for some production use cases Uber.
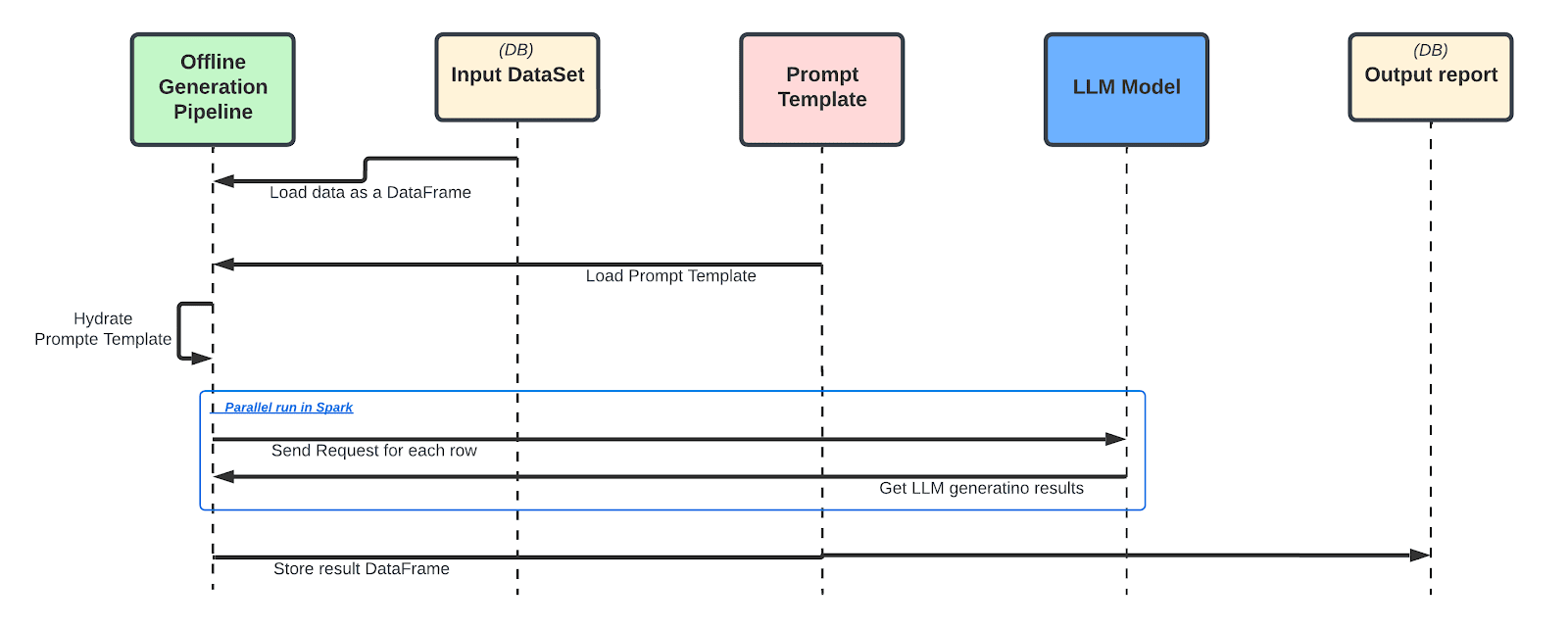
Offline LLM Service
The LLM Batch Offline Generation pipeline facilitates batch inference for large-scale LLM response generation. For example, this pipeline can be integral to the rider name validation use case, which verifies the legitimacy of consumer usernames. It assesses all existing usernames in Uber’s consumer database as well as those of newly registered users, employing an asynchronous method to process and generate responses for usernames in batches.
In MA Studio, setting up this Offline Generation pipeline is straightforward: users select the relevant dataset and input it as data. The prompt template is dynamically hydrated with this dataset. For instance, if the user’s prompt template includes the sentence “Is this {{user_name}} a valid human name?” the pipeline extracts the user_name column from each data row, using it to generate a custom prompt for each entry.
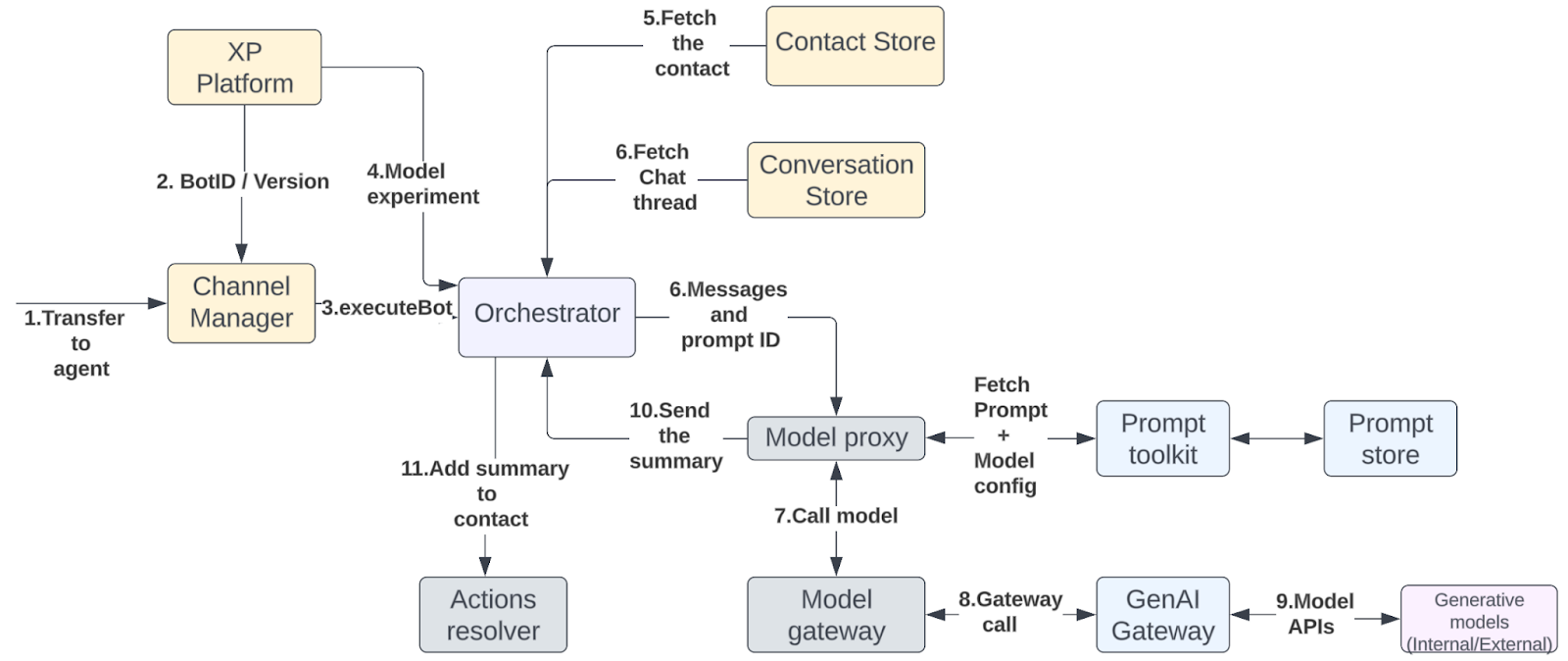
Online LLM Service
The prompt template contains dynamic placeholders that need to get replaced with specific runtime values provided by the caller. The caller is responsible for hydrating and passing the values that must get substituted on the placeholders. The model’s hyperspace service currently supports substitution using Jinja-based template syntax. At the moment, we only handle the substitution of string types.
This service also supports fan-out capabilities across prompts, templates, and models. The fan-out capabilities can be divided into:
- Templates: The API templates include formatting the payload into a vendor-specific API structure from the generic data model we exposed from the service. Multiple templates, such as chat completion and text completion templates, are supported.
- Prompts and Models: The prompts are pinned to a specific model and template. The service fetches the prompt and call the genAI APIs with the required model and template parameters for execution.
Let’s explore the above functionalities through a summarization use case. A contact is a support ticket used to contact a customer support agent. There are scenarios where multiple agents can handle a contact. In this case, the new agent receiving the handoff must either go through the ticket to understand the context or ask the customer to reiterate the problem. Usually, it’s the former. To solve this, we provide a summary to the agents when there’s a handoff from one agent to another.
Monitoring
Monitoring measures the performance of the production prompt template used in production. The purpose is to track the regression and performance of the currently prompt template in production. A daily performance monitoring pipeline runs towards production traffic to evaluate the performance. Metrics include latency, accuracy, correctness, and more to monitor each prompt template production iteration.
An MES dashboard gets refreshed daily with performance monitoring metrics. Refer to the MES blog post for more information about the MES dashboard.
Conclusion
The prompt engineering toolkit outlined in this blog represents a comprehensive framework designed to enhance the interaction with and utilization of LLMs across various stages of development and production at Uber. From the initial exploration of LLM capabilities in the Gen AI Playground to the detailed iteration and creation of prompt templates, the toolkit facilitates a dynamic environment for both novice and expert users to harness the power of LLMs effectively.
The architecture of the toolkit allows for a systematic approach to prompt design, incorporating advanced guidance techniques and robust evaluation methods to ensure the production of high-quality, effective prompts. The structured lifecycle of prompt templates—from development through to production usage and monitoring—ensures that each template is rigorously tested and optimized for performance.
As a next step, we hope to evolve the prompt toolkit to integrate with online evaluation and with RAG for evaluation and offline generation.
LangChain™ is a trademark of LangChain Inc., registered with the United States Patent and Trademark Office. All other product and company names mentioned herein may be trademarks of their respective owners. The use of these marks does not imply any affiliation with or endorsement by their respective owners.
Cover Photo attribution: “Artificial Intelligence & AI & Machine Learning” by mikemacmarketing. This image was marked with a CC BY 2.0 license:No modifications.

Sishi Long
Sishi Long is a Staff Engineer at Uber working on the AI/ML platform, Michelangelo.

Hwamin Kim
Hwamin Kim is a Software Engineer working on the AI/ML platform, Michelangelo.

Manoj Sureddi
Manoj Sureddi is a Staff Software Engineer on the Customer Obsession team.
Posted by Sishi Long, Hwamin Kim, Manoj Sureddi
Related articles




Most popular

Adopting Arm at Scale: Transitioning to a Multi-Architecture Environment

A beginner’s guide to Uber vouchers for riders

Automating Efficiency of Go programs with Profile-Guided Optimizations
