
Introduction
Uber employs various technologies for data storage, including well-known open-source products such as Kafka, Cassandra, and MySQL, alongside internally developed solutions. In 2014, Uber underwent rapid expansion. Like many startups, the technology teams manually performed provisioning and maintenance operations using runbooks. This approach led to operational toil as storage demands rapidly increased. Uber created a technology-agnostic management platform called Odin to uplevel operational throughput through automation and allow the teams to manage thousands of databases effortlessly.
The Odin platform aims to provide a unified operational experience by encompassing all aspects of managing stateful workloads. These aspects include host lifecycle, workload scheduling, cluster management, monitoring, state propagation, operational user interfaces, alerting, auto-scaling, and automation. Uber deploys stateful systems at global, regional, and zonal levels, and Odin is designed to manage these systems consistently and in a technology-agnostic manner. Moreover, Odin supports co-location to increase hardware cost efficiency. All stateful workloads must be fully containerized, a relatively novel and controversial concept when the platform was created.
This blog post is the first of a series on Uber’s stateful platform. The series aims to be accessible and engaging for readers with no prior knowledge of building container platforms and those with extensive expertise. This post provides an overview of Odin’s origins, the fundamental principles, and the challenges encountered early on. The next post will explore how we have safely scaled operational throughput, significantly improving our handling of large-scale, fleet-wide operations and up-leveling runbooks through workflows. Stay tuned for more posts in the series.
The Scale of the Platform
Since 2014, Uber’s storage and data infrastructure has grown dramatically, from a few hundred hosts to over 100,000 today. These hosts support the operation of 300,000 workloads across various storage clusters. Each workload on the Odin platform is similar to a Kubernetes® pod, comprising a collection of containers. Currently, the platform manages 3.8 million individual containers. The fleet of hosts collectively boasts a storage capacity of multiple exbibytes and millions of compute cores.
The platform supports 23 technologies, ranging from traditional online databases such as MySQL® and Cassandra® to advanced data platform technologies, including HDFS™, Presto™, and Kafka®. It also integrates resource scheduling frameworks like Yarn™ and Buildkite™, primarily due to the platform’s robust capacity management and scaling solutions.
The platform is heavily colocated to leverage the resources available on the hosts best. Uber uses locally attached drives for all stateful workloads for performance. Our scheduler, therefore, has to optimize to keep allocation rates high across all three dimensions (i.e., CPU, memory, and disk) to be efficient. We boast a very high allocation rate of +95% on the bottlenecked resource, and we have hosts with +100 databases.
The Odin platform is both technology-agnostic and cloud-agnostic through Uber’s cloud abstraction and currently runs across OCI, GCP, and Uber’s on-prem fleet.
A Self-Healing Platform
Odin is built to be fully declarative and intent-based. This results in properties such as failure tolerance, scalability, and self-healing. The desired state is expressed as the goal state, which the platform uses to converge the actual state automatically. We accomplish this by using an extensive collection of small, autonomous remediation loops designed to ensure the system’s actual state converges with the declared goal state by continuously nudging the system in the “right direction.”
Today, Odin and Kubernetes® share many similarities. This mental model will be helpful as you read through the blog series.
The example below illustrates the anatomy of a remediation loop. A remediation loop starts by inspecting the goal state. It then collects the actual state, identifies discrepancies between the two, and uses Cadence™ workflows to adjust the system state to close the gap. This is similar to how Kubernetes controllers work–except they directly manipulate the state through the APIServer.
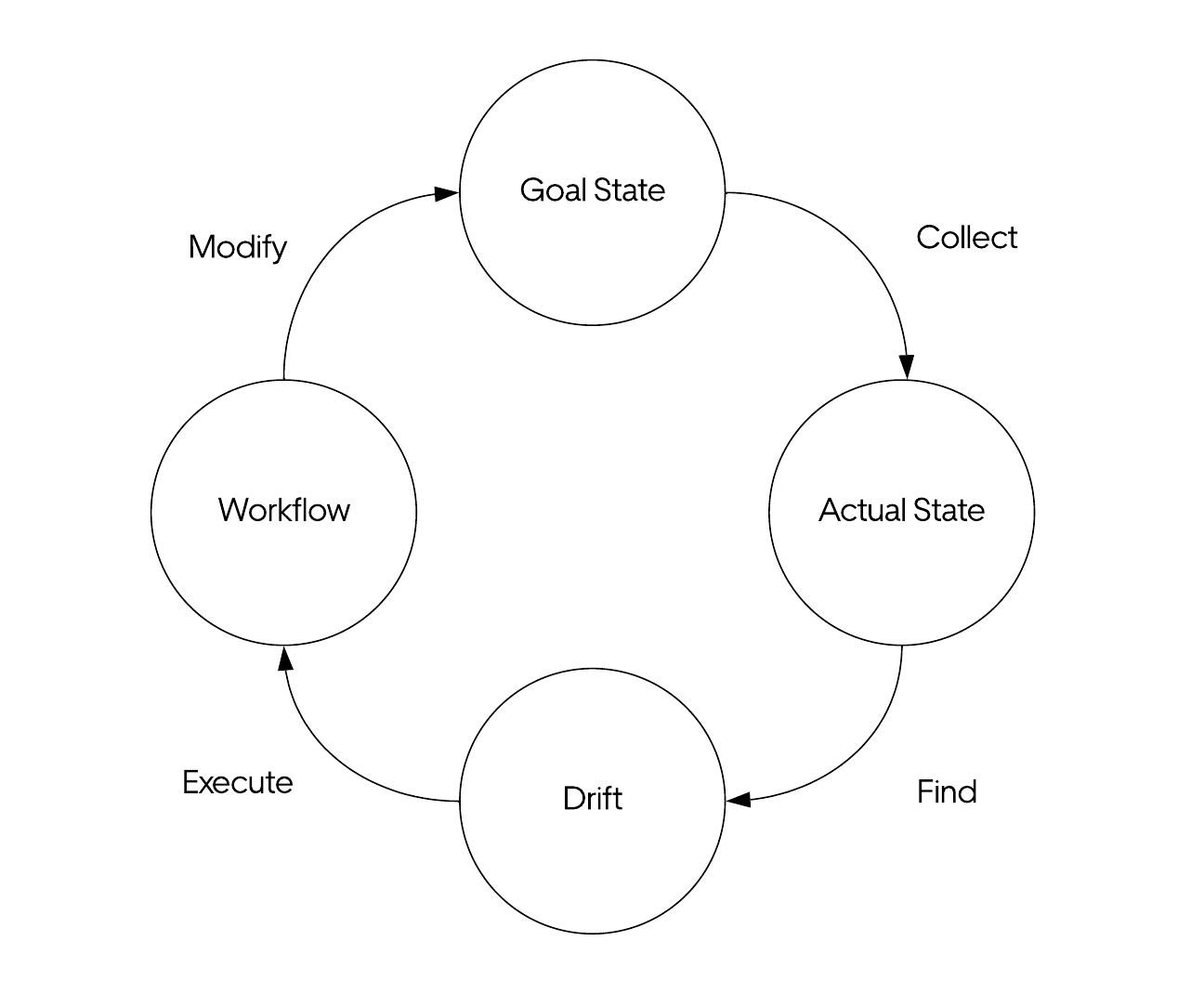
Our remediation loops prioritize modularity and loose coupling. This facilitates horizontal scaling and ease of development so that each loop can be developed as an independent microservice.
On the Odin platform, we have streamlined the development of these loops by providing an up-to-date view of the global system state through our data integration platform, Grail. Grail delivers a unified data model that spans all technologies and provides an up-to-date view of the platform’s goal and actual states, including hosts, containers, and even the technology-specific internal state. Our Grail setup also allows performing queries with a global scope, fetching data provided in all the data centers and regions around the globe where Uber operates. In essence, think of Grail as the resource model in the Kubernetes APIServer on steroids.
The platform’s control plane focuses solely on high-level decisions, such as scheduling workloads and managing cluster topology. The API for manipulating the goal state is the execution of a workflow. Both remediation loops and human operators start workflows. The platform provides a UI that allows operators to quickly overview the state of their databases and apply operations when needed.
Workflows are incredibly valuable because of the insights they provide. A workflow for updating goal state usually consists of two steps. First, the goal state is updated, and then the workflow will monitor the actual state until it converges on the specified goal state. So when it doesn’t, it is clear which operations didn’t converge, including the context of why that operation was performed in the first place. As the actual state is not expected to converge immediately, the system must prevent the remediation loops from continuously starting workflows that attempt to fix the same issues.
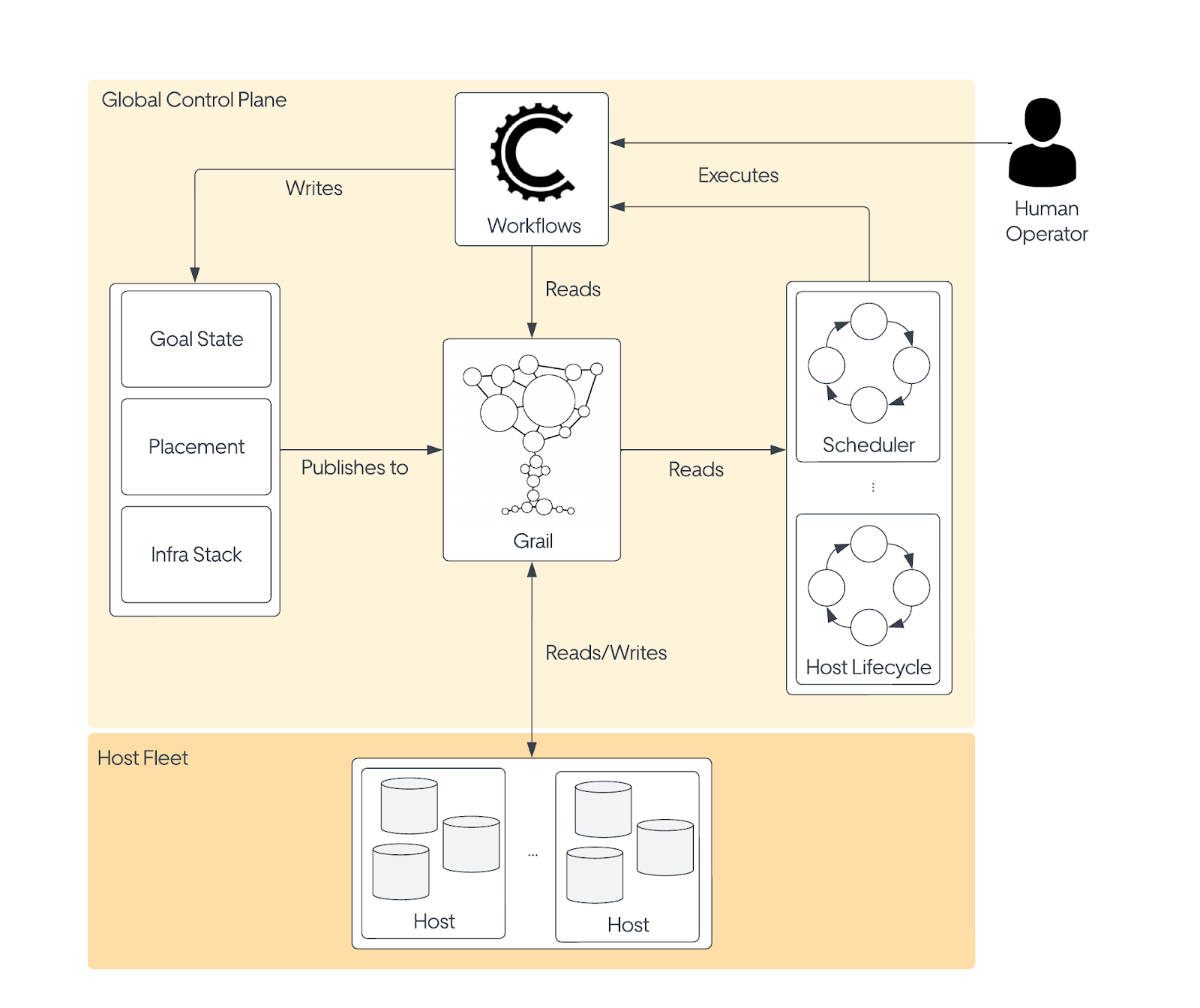
Managing Generic Storage Clusters
Odin is built on a technology-agnostic cluster model that provides generic operations for managing clusters of workloads of any kind. This model supports generic operations such as adding or removing workloads, upgrading container images, and handling other cluster-related tasks uniformly across technologies. As the model and operations are technology-agnostic, the technology is required to extend the platform through a collection of plugins to tailor various aspects of cluster management according to their specific needs.
Two Host Agents
The Odin control plane is divided into two parts. So far, we have only discussed the global part. At the host level, there are two agents. One is shared among all workloads on the host and is technology-agnostic. We simply refer to this as the odin-agent. The other agent is technology-specific and runs containerized as part of the workload. These two agents, when combined, serve the same functionality as the kubelet.
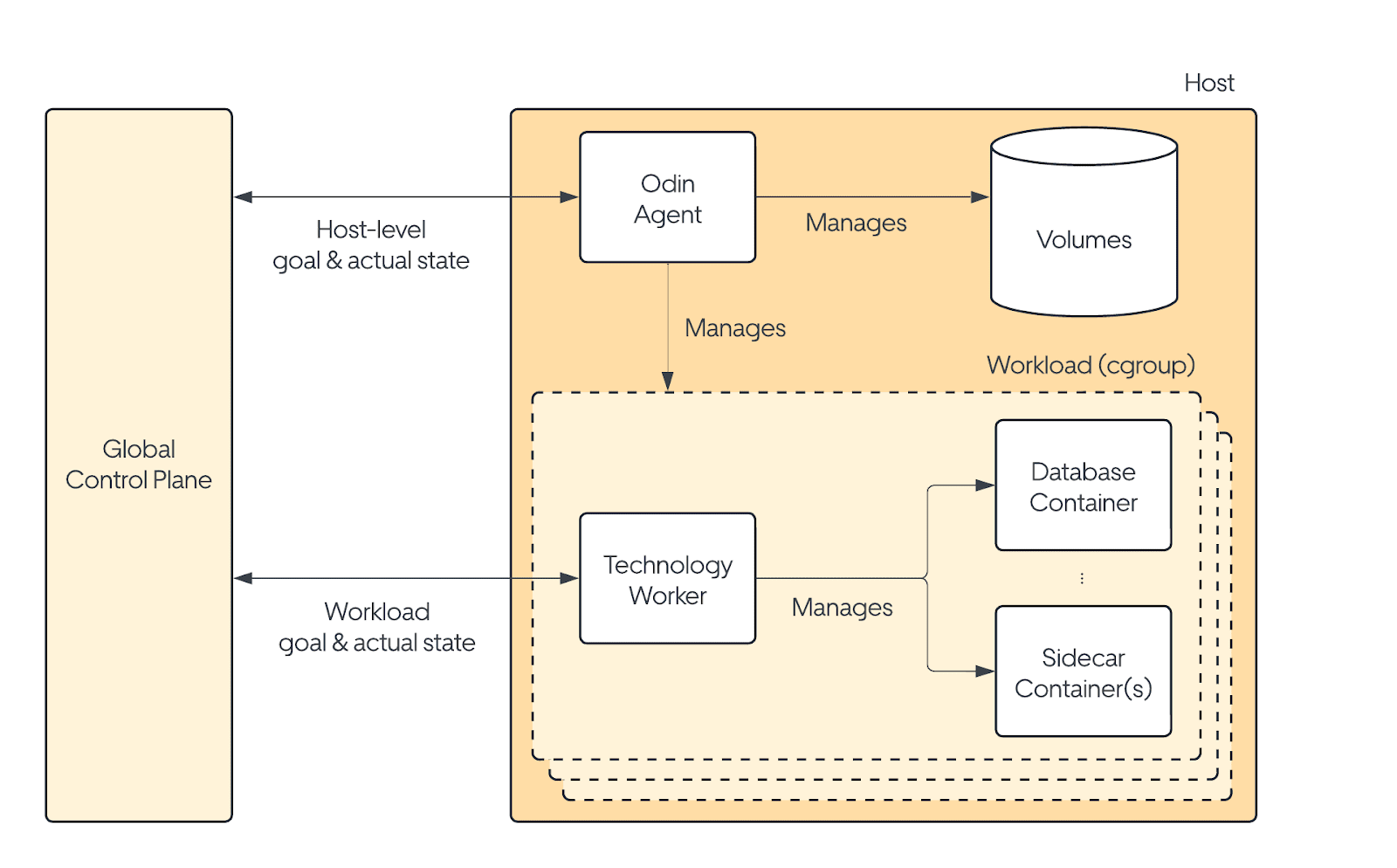
The host agent communicates the latest goal and actual states with the global control plane. Its primary responsibility is managing host-level resource allocation, such as scheduling cores for workloads, creating and managing disk volumes/cgroups, and bootstrapping the workloads when assigned to the host.
The technology-specific agent is known as the worker. The worker is a supervisor running alongside each workload in a side container. Its primary role is to ensure that the running containers align with the goal state and to collect health and other relevant data for reporting to the global part of the control plane. The worker’s generic functionality includes starting and stopping containers. You can think of the worker as the translator between the generic cluster state the platform understands and the running database containers in the workload.
The technology team can customize the worker to collect the technology-specific actual state and apply the goal state to the workload. For instance, the MySQL worker is tasked with ensuring that MySQL masters and replicas maintain their roles and report the current state for consumption to the global control plane. This allows the team to write new workflows for operating the cluster based on the actual state of the cluster. Many technologies have extended their workers to perform self-healing cluster operations in their workers. Examples could be coordinating leader elections or data replication when the cluster topology changes.
Optimizing for Robustness and Resilience
Separating the control plane into a host-local and a global component allows us to deploy worker changes per workload, limiting the potential blast radius of bad changes to the smallest possible unit. The same applies to each container in a workload, as the platform allows in-place upgrading containers individually.
For both agents, a rule is that the goal state must first be written to disk before any changes to the running workloads are made. This approach guarantees self-sufficient clusters that can be initialized without an active control plane, effectively addressing the bootstrap issue. Furthermore, it offers robust failure resilience, allowing workloads to function during control plane degradations and simplifying writing emergency tooling.
Transitioning Identities
As we continuously optimize for efficiency and modernize our host fleet, moving a workload from one host to another has become one of the most common operations on the platform. To date, we reschedule up to 60% of our stateful workloads per month. A crucial requirement of stateful workloads is maintaining the workload identity across rescheduling. This capability allows, for example, the replacement of one workload serving a shard with another serving the same shard. In Kubernetes, this is managed through StatefulSets by assigning a stable pod identity that persists across rescheduling. When a pod is deleted, a new one is provisioned with the same identity. Let us explore why this model does not suit Uber’s use case well.
As mentioned, Uber uses locally attached drives for all stateful workloads for performance. This setup requires that data on a host be replicated and made available elsewhere before the corresponding workload can be terminated. The cluster becomes temporarily under-provisioned if a workload is shut down before its replacement is fully ready. This delay, which is not negligible with a median time of 1 hour, exposes the cluster to an increased risk of data loss or availability issues. Moreover, this delay also diminishes the cluster’s overall capacity to handle requests.
“Replacing” Workloads
Consequently, the most essential operation on Odin is migrating a workload from one host to another–or, in Odin terms, “replacing” the workload. A replace operation is purposely designed to make-before-break. This means it creates a new workload that can carry the identity and data of the workload it replaces before the old workload is shut down, wherever possible. The technology integrations can choose which parts of the goal state to propagate between workloads. The goal state model makes the two workloads explicitly aware of each other’s existence. This is essential because it allows the respective workers to coordinate the process for data replication and other things. In rare cases, when make-before-break semantics are impossible (e.g., the old workload is on a failed host), the old workload is deleted simultaneously with the replacement workload being created.
Using make-before-break also has an efficiency benefit, as the alternative would require us to run the clusters overprovisioned continuously. In our model, we only temporarily overprovision when we have to.
Growing Pains
The first iteration of the Odin platform was a giant leap forward concerning the teams’ ability to operate their storage clusters. Storage teams could converge all their operations and insights on a single platform with a shared operational model. However, the platform was still very much human-centered. Humans were the principal actors initiating changes on the platform, and, crucially, they were the ones vouching for the safety and the fit of the operations performed. The role of the remediation loops was confined to operations with a relatively small scope, such as a single replace workflow.
Operational overhead started to grow as the business continued to scale to the point where fleet-wide operations spanning technologies were not practically possible for human operators to do. Examples of complex, fleet-wide, cross-technology operations that require us to move workloads are:
- Optimizing workload placement for resiliency against infrastructural failures like rack or zone failures
- Host bin-packing to improve cost-efficiency
- Fleet-wide host upgrades like new kernels, firmware, or functionality like LVM/cgroupv2
- Facilitating the bringing up of new data centers or decommissioning existing data centers
Furthermore, the large number of databases on a single host makes handling host failures daunting. These limitations indicated that we had to double down on automation by developing new remediation loops with much broader scopes than we used to.
Coordination Required
The increased operational load could quickly result in outages if not carefully coordinated. Imagine a situation where a workload in a 3-node consensus-based storage cluster is taken down to perform a container upgrade. Now imagine another remediation loop that has identified that one of the other workloads in the cluster would benefit from being moved for efficiency reasons. If allowed, this would result in the storage cluster losing quorum, impacting the write availability.
Initially, we started augmenting the remediation loops to perform concurrency control internally (Figure 3). This way, they could prevent operations of the same type from creating problems for the storage clusters. For instance, the container upgrade loop would block overlapping upgrades. However, this approach fell short as it didn’t solve the issue of conflicting operations started by different remediation loops. Figure 3 shows a case where two independent operations can operate two workloads in the same storage cluster, resulting in an availability loss.
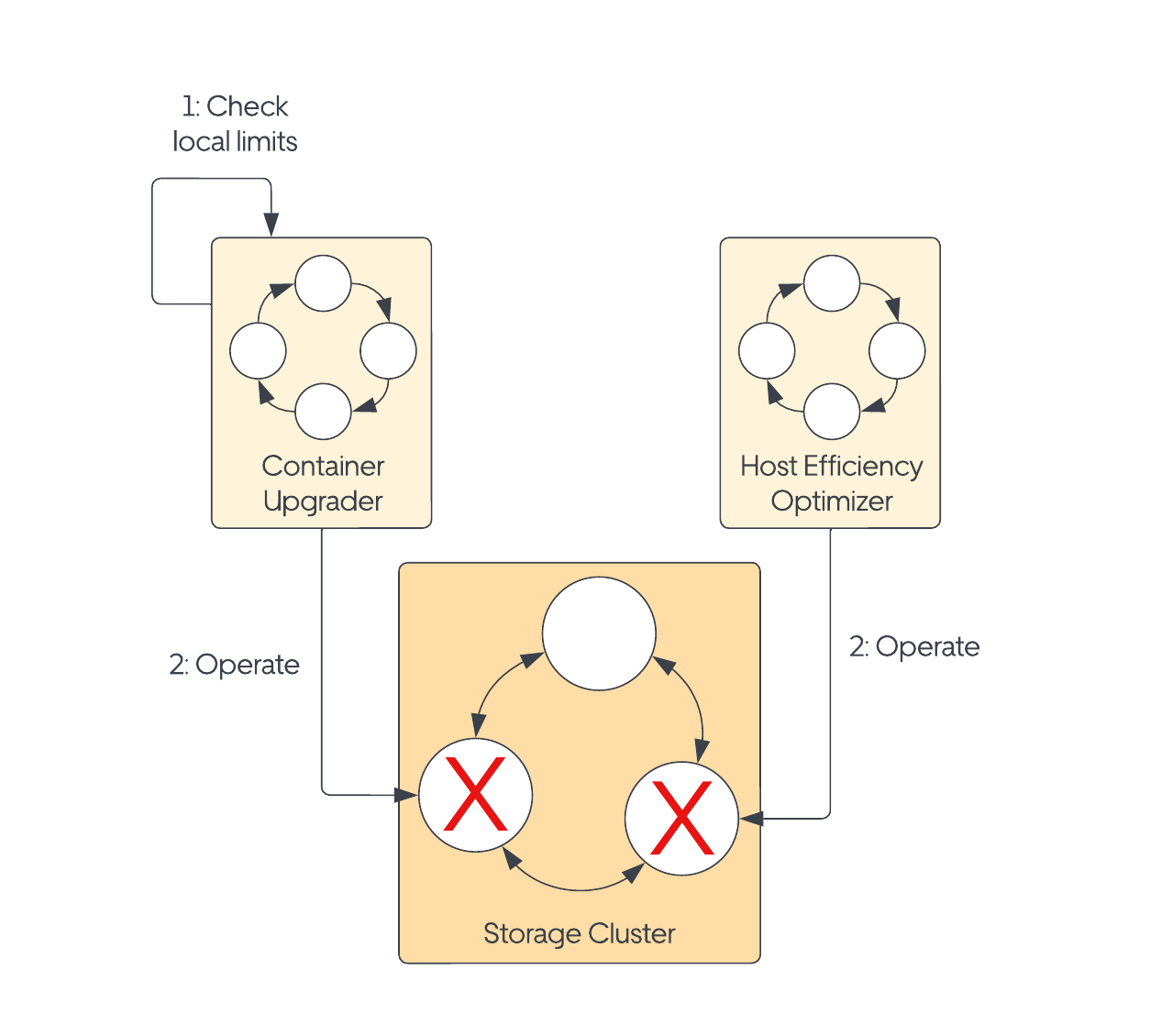
Different technologies exhibit widely varying tolerances for safe cluster operations. For some technologies, the specific workloads being operated are crucial, while all workloads are treated equally for others. Some technologies focus solely on ensuring that a certain number of workloads are always available within the cluster. This diversity in requirements made it such that we had to support customizing cluster management strategies to the specific needs of each technology.
We needed to ensure global, cross-type coordination of operations using a system that could guarantee to preserve the cluster availability by leveraging technology-specific limits based on the current workload health and disruption budget. Furthermore, it should protect against engineering mistakes and overload of the internal platform systems by enforcing platform-wide global concurrency and rate limits.
Summary
In this introductory post of our series, we explored the background and foundational principles of Uber’s stateful platform, Odin. Odin stands out as a generic, technology-agnostic platform capable of managing various technologies with special demands on how databases are operated.
We discussed how Uber’s databases use locally attached disks for enhanced performance and cost-efficiency and the challenges this presents, as the stored data must follow the workload identity.
We also examined how the platform is inherently intent-based, with disparate remediation loops continuously striving to align the actual state of the managed workloads with their intended goal states. These loops initiate Cadence workflows to update the goal state and wait for convergence—a process that, at scale, requires careful coordination to safely manage without compromising the availability of the managed databases.
In the next blog post, we will discuss how we centralized the coordination of all operations and leveraged it to significantly improve Uber’s ability to operate the fleet at scale.
Acknowledgments
The Odin platform was only possible with the effort of many contributors through the years. The authors would like to thank all the teams working on the platform or contributing integrations and to previous team members who helped make the platform great.
The cover photo was generated using OpenAI’s ChatCPT Enterprise and edited using Pixlr.
Kubernetes® is a registered trademark of the Linux Foundation in the United States and other countries.
MySQL® is a registered trademark of Oracle Corporation and/or its affiliates.
Apache Cassandra®, Apache HDFS™, Apache Kafka®, Apache Yarn™, and Apache Presto™ are registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. The use of these marks does not imply endorsement by the Apache Software Foundation.
Buildkite™ is a trademark of Buildkite Pty Ltd.

Jesper Borlum
Jesper Borlum, Sr. Staff Engineer at Uber, is a seasoned software engineer, architect, and team player. He leads the Stateful Platform team, responsible for building the infrastructure to manage all of Uber’s stateful systems. The team’s mission is to deliver a fully self-healing platform without compromising availability, reliability, or cost. He’s currently leading the effort to adopt Arm at Uber.

Gianluca Mezzetti
Gianluca Mezzetti, Sr. Staff Engineer at Uber, was among the pioneers of the Stateful Platform team. His extensive contributions across multiple platform domains, such as workflows, concurrency control, host remediation, goal state storage, and auditing, have been instrumental in expanding the platform’s capacity. Currently, he leads the initiative to integrate Kubernetes into Odin.
Posted by Jesper Borlum, Gianluca Mezzetti
Related articles



Most popular

A beginner’s guide to Uber vouchers for riders

Automating Efficiency of Go programs with Profile-Guided Optimizations

Enhancing Personalized CRM Communication with Contextual Bandit Strategies
