How Uber ensures Apache Cassandra®’s tolerance for single-zone failure
June 20, 2024 / Global
Introduction
Uber has been running an open-source Apache Cassandra® database as a service that powers a variety of mission-critical online transaction processing (OLTP) workloads for more than six years now at Uber scale, with millions of queries per second and petabytes of data. As Uber operates data centers in multiple zones across multiple regions, a Cassandra cluster at Uber typically has its nodes spread across multiple zones and regions. With high availability being essential for Uber’s business, we’d like to have Cassandra’s availability unaffected in the scenario of a single zone going down. This blog shows how we ensured the single-zone failure tolerance for Cassandra, and particularly how we converted the large Cassandra fleet in real-time with zero downtime from non-zone-failure-tolerant to single-zone-failure tolerant.
Terminology
SZFT: Single Zone Failure Tolerant
Background
Cassandra naturally supports multiple copies of data. One of the biggest benefits of having multiple copies of data is high availability: if a minority of copies becomes unavailable, the majority of copies can still be accessed. When a Cassandra cluster is deployed across multiple availability zones, we would like to ideally have all the copies distributed evenly among the zones so that an impact to a zone does not impact user requests.
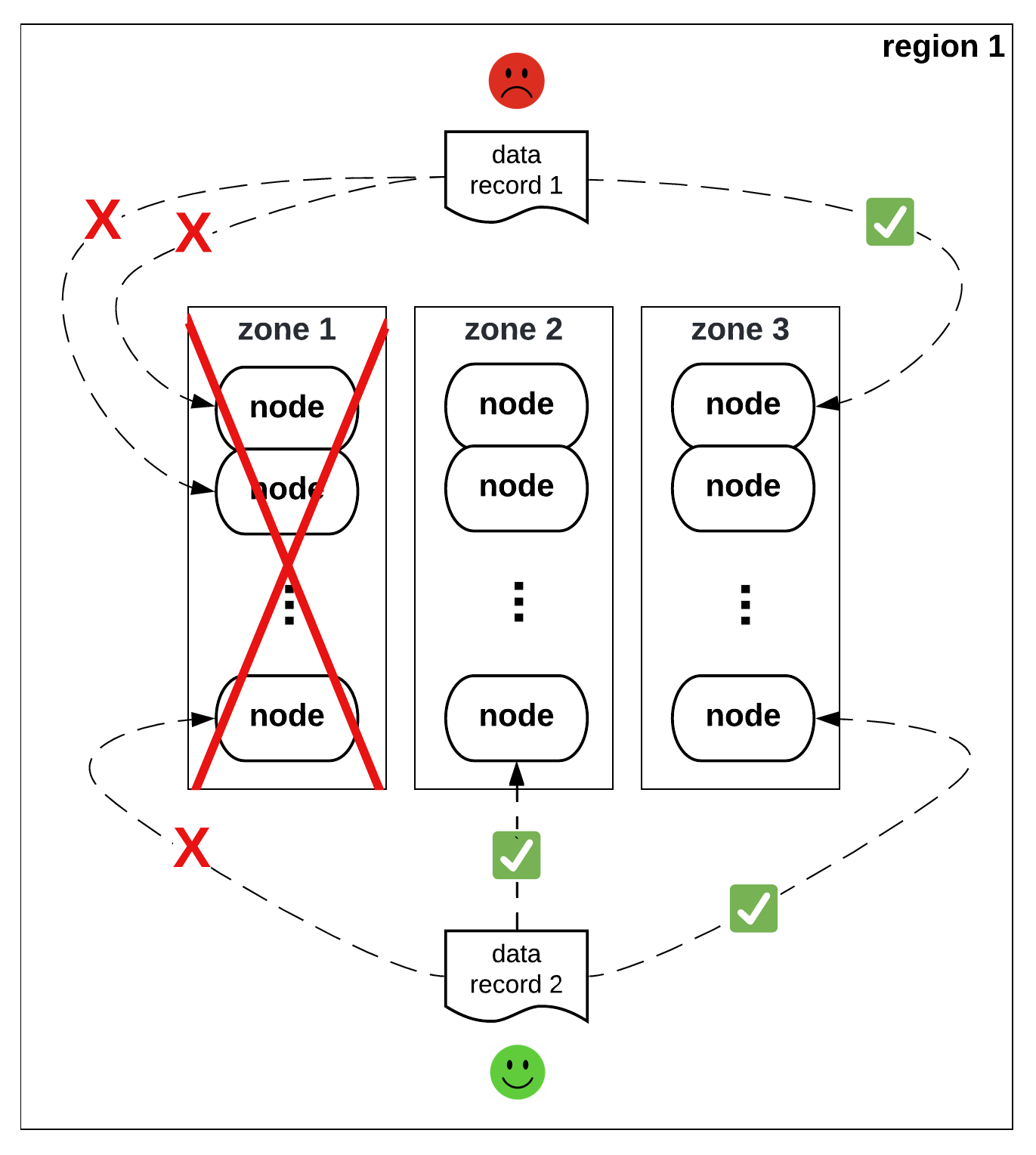
Figure 1 illustrates the problem. In this example, the replication factor is 3. A data record is considered available when the majority of its copies are available. When zone 1 is down, data record 1 becomes unavailable because it loses the majority (two) of its copies. Meanwhile however, data record 2 is still available because it happens to have a minority (only one) of its replicas placed in the failed zone. If all data records had their replicas placed in the same way as data record 2 where the replicas are evenly distributed across the zones such that each zone contains only a minority of the copies, then the failure of any single zone would have no impact on the overall availability.
Cassandra inherently supports separating the replicas with a feature that logically groups the nodes. Replicas are then separated by the groups. The grouping is done via a file called cassandra-rackdc.properties.
In this feature, each Cassandra node is assigned with two properties: dc and rack. For example, a Cassandra node in region 1 would be configured as the following:

When the replication strategy is NetworkTopologyStrategy, within a dc, for any data record, Cassandra’s replica placement algorithm places replicas onto as many racks as possible. This is illustrated in the below figure:
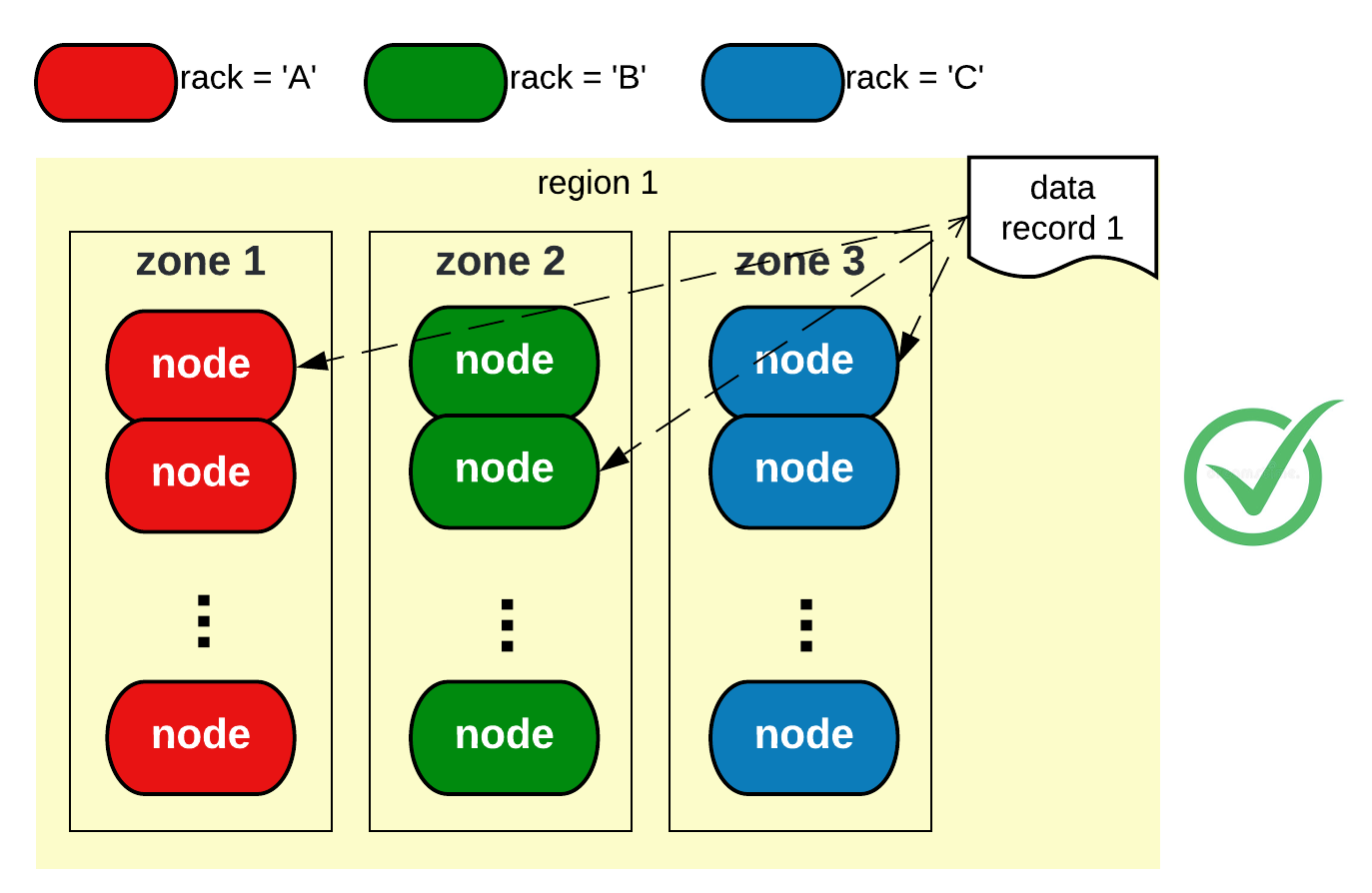
The setup in Figure 2, assuming replication factor is 3, is a desired setup that is SZFT (single zone failure tolerant). No matter which single zone goes down, there will still be two healthy replicas in the other zones serving reads and writes, for any data records.
Why was Cassandra at Uber not SZFT
Uber was not using the setup in Figure 3–we simply didn’t take advantage of the “rack” property. All the Cassandra nodes were assigned the same “default” value for the rack property, resulting in only one unique rack value in the region. Replicas failed to be properly separated because to separate replicas multiple values for the rack property are needed. As a result, a majority or potentially all replicas can be placed in the same zone, as illustrated in the below figure:
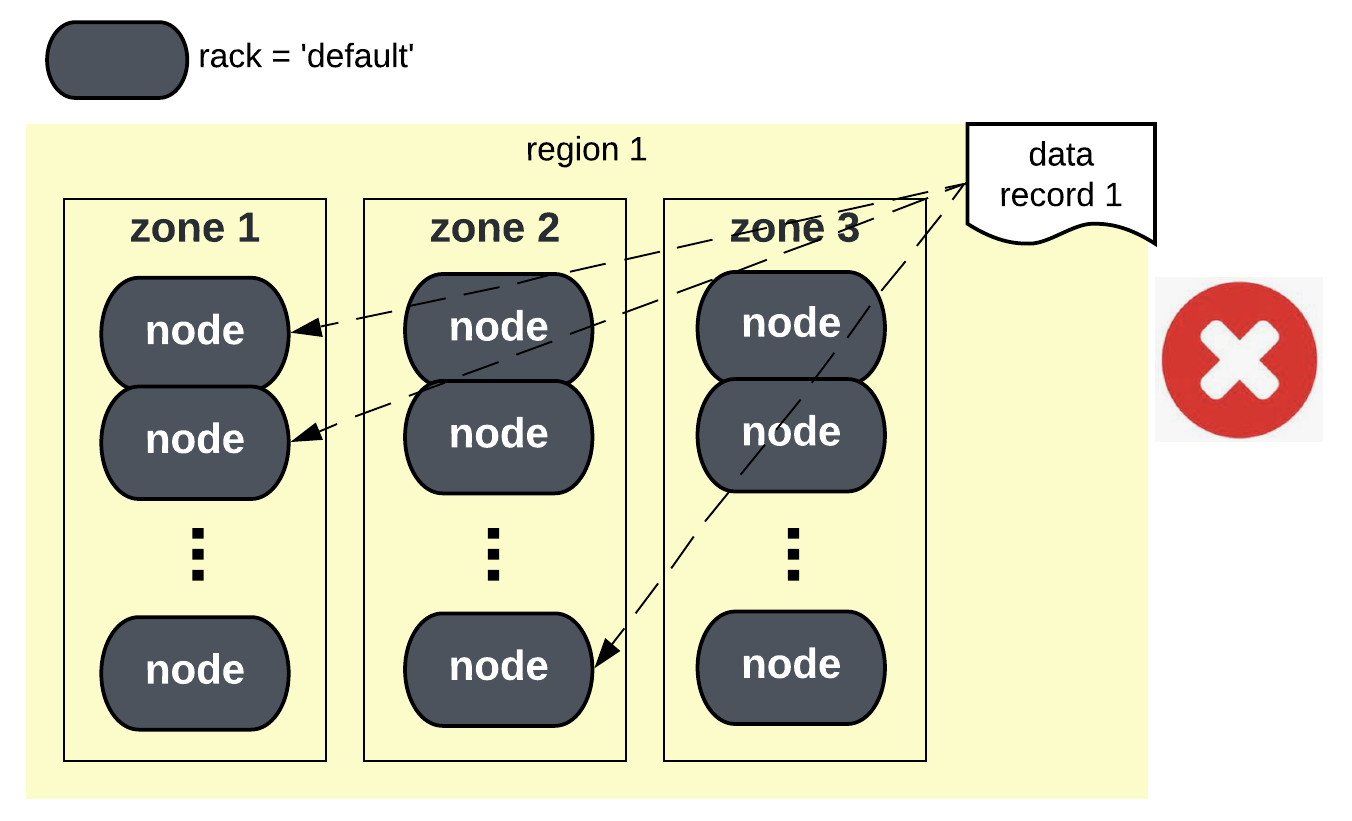
At a high level, solving the problem for Uber essentially meant the transition from the single-rack setup (in Figure 3) to the multi-rack setup with a zone-based rack assignment strategy (in Figure 2). The transition posed multiple challenges. Let’s see what they are and how we overcame them at Uber.
Challenge 1: In-Place Transition Not an Option
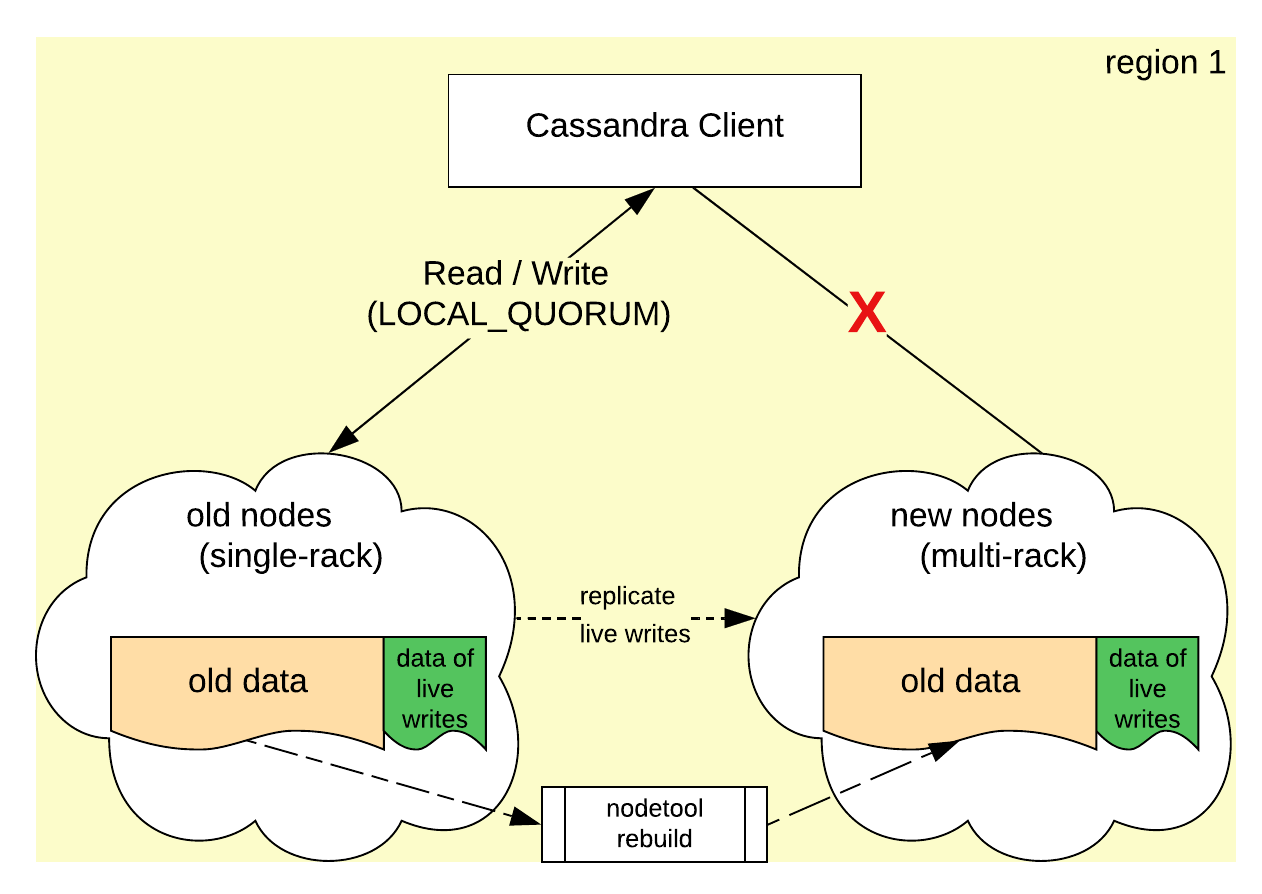
It proved impractical to transition in-place the existing nodes in a region from the single-rack setup to the multi-rack setup. This is because if a node associated with a new rack is introduced to an existing single-rack node setup, it will immediately make the new member a hotspot. As already stated, Cassandra’s replica placement algorithm places replicas onto as many unique racks as possible. The moment a node brings a second rack to Cassandra, all the data records will each place a replica onto the new rack, even though there is only one node in it! Figure 4 well illustrates the problem:

Due to the limitation of the replica placement algorithm, we are left with only one option which at a high level looks as follows:
- Create a new Cassandra ring, or a new “dc” as in NetworkTopologyStrategy, within the same region. The new ring is created with the multi-rack setup to meet the SZFT requirement.
- Rebuild the newly created ring through rebuild from the old live ring.
- Transparently swap the new ring with the old ring by moving the customer traffic from one ring to another.
- Remove the old ring.
We set the following principles for this whole migration:
- Zero customer involvement—our stakeholders must not be involved or exposed to the migration (e.g., changing service logic, client code, or routing)
- High Availability—no down time during migration
- Maintaining pre-existing performance SLOs, such as latency
- Rollback capability so we can switch back and forth between the old ring and the new ring as an emergency measure
The Rebuild Procedure
Phase 1: Provision a new set of “offline” multi-rack nodes in the region
In the selected region, add a new ring of nodes to the cluster. The hardware resource given to the new nodes (e.g., node count, CPU cores, memory, disk size) need to be the same as the existing ring in that region. Distribute the new nodes evenly across the zones. Group them with the zone-based strategy by configuring the cassandra-rackdc.properties file of each node as following:

Lastly, all the new nodes should be created with native transport disabled to prevent CQL connection to them. This is crucial for a seamless traffic switch later from the existing ring to the new one.

Phase 2: Data Sync for Live Writes
As our end goal is to have the new ring replace the old ring, we need to have all the data replicated and existing in both rings. This includes both the data from the live writes as well as the historical data. For the data from the live writes, we need to add the new ring to the replication setting of all the keyspaces such that they can start to indirectly receive live writes thanks to Cassandra’s cross-dc replication.


Phase 3: Data Sync for Historical Data
For historical data, we need to have the new ring stream it from the old ring. Although the new nodes are now receiving live writes, they are still lacking all the data from the past. Cassandra provides a tool to stream such data using the nodetool rebuild command. The following command needs to be run on every new node of region1_new to stream data from region1:

Phase 4: Traffic Switch
After the historical data has been streamed, we are ready to have the Cassandra client connect to the new ring of nodes and stop connecting to the old. This is done by enabling native transport on all the nodes in the new ring and then disabling native transport on all the nodes in the old ring. We’ve eliminated the need for any actions on the client side, the reason for which will be discussed in the next section where we are going to see the Cassandra client enhancement we’ve made at Uber.
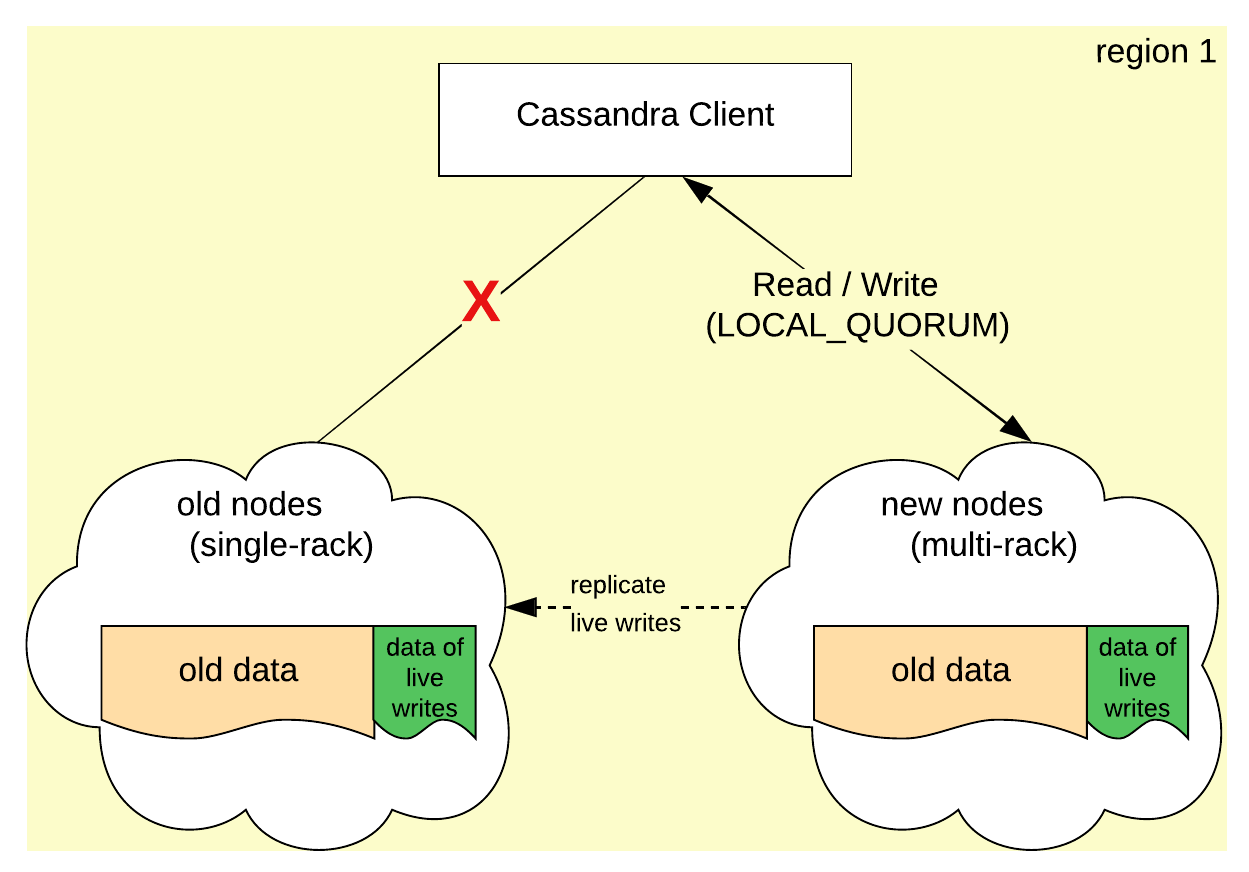
Phase 5: Remove Old Nodes
Firstly, the replication setting of all the keyspaces needs to be altered so that the old ring is no longer part of the data replication.

Once this is done, the nodes in the old ring are decommissioned.
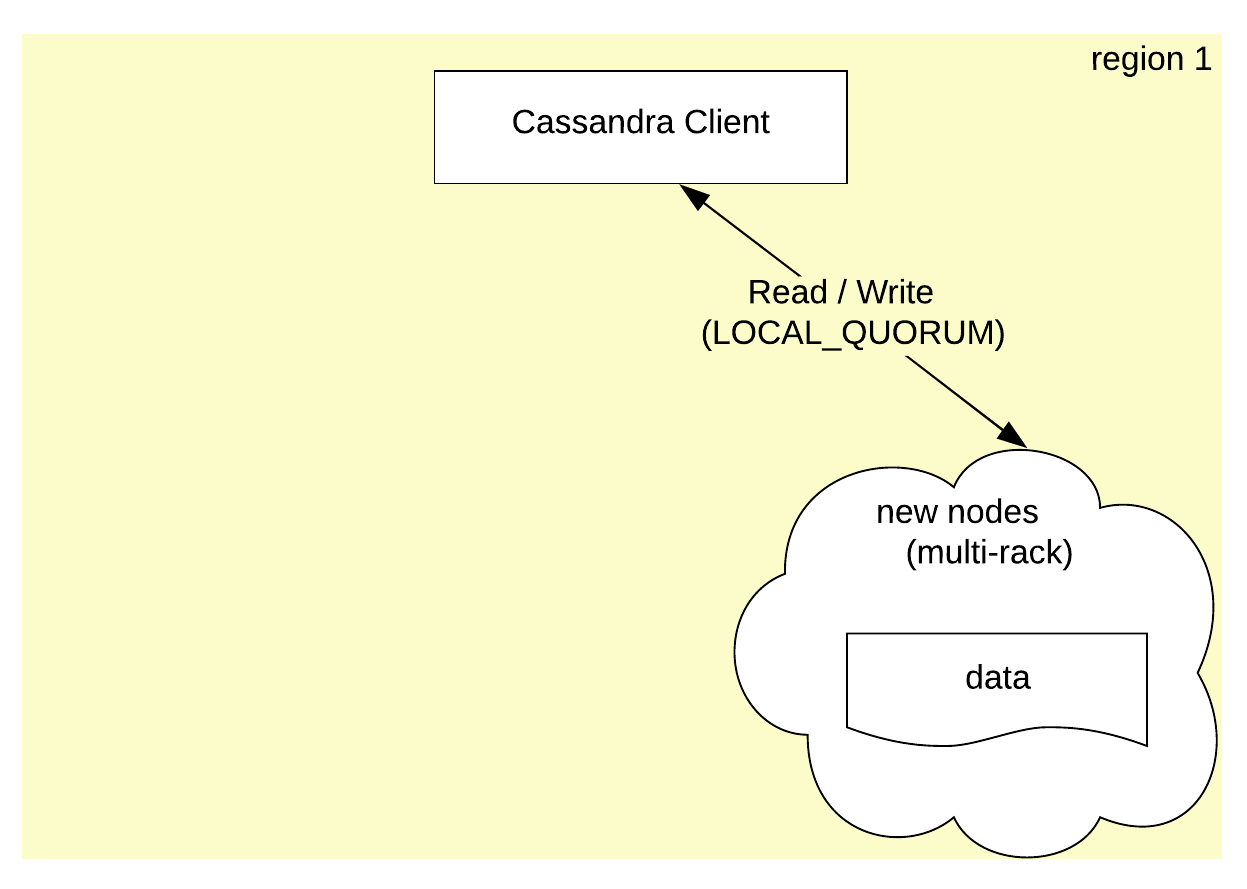
Phase 6: Repeat for the other regions
The Cassandra cluster in the selected region is now SZFT. The same procedure needs to be repeated for the other regions.
Cassandra Client Enhancement
During the above procedure, no client side actions are involved. This is because at Uber, we have a fork of GoCQL and Java drivers where we have enhanced them to be capable of dynamically switching traffic from one ring to another without a restart.
In order to achieve a seamless traffic switch, the expectation on the Cassandra clients are to:
- Always be provided with initial Cassandra contact points (i.e., the Cassandra nodes for the initial topology discovery) from the same region where the client is.
- Always choose coordinator nodes from the same region where the client is.
- Automatically connect to the nodes of the new ring, after native-transport is enabled on them and disabled on the nodes of the old ring, as in Phase 4 of the Rebuild Procedure.
Requirement #1 was fulfilled with a new micro-service that’s dedicated to publishing the contact information of Cassandra clusters. It has an integration with our Cassandra control plane and thus understands the topology of every Cassandra cluster. The consumer of this service (in this case a Cassandra client) sends a request containing only the name of the target Cassandra cluster. The service returns the contact information (e.g., IPs and ports) of all the nodes belonging to the cluster that are in the same region as the consumer.
The above logic is hidden from the client API, and our Cassandra users simply need to change their way of providing the client with contact points, as the following:

Requirement #2 was done with a new host filter we implemented at Uber within the Cassandra clients. This new host filter excludes all the coordinator nodes that are located in regions remote to the client.

Requirement #3 was achieved by specifying the load balance policy as TokenAware + RoundRobin. The thing that really matters is not the use of these policies, but the elimination of the use of DCAwarePolicy. DCAwarePolicy, which was once seen in many Cassandra applications at Uber, pins the coordinator node selection to the old ring. Open-source clients were already capable of capturing the native-transport-related changes in a timely fashion, automatically dropping connection to the native-transport-disabled nodes and automatically connecting to the newly-native-transport-enabled nodes. Therefore all we needed to do was allow clients to connect to any rings in the same region.
In the end, we standardized the Cassandra client configuration at Uber like this:

These enhancements in the client elegantly decouple users from the low-level topology detail of the Cassandra cluster–e.g., IP, port, dc (as in NetworkTopologyStrategy), etc. It paves the way for a seamless traffic switch in Phase 4 of the rebuild procedure. Moreover, the region-based coordinator selection paired with “LOCAL_QUORUM” reads and writes ensures that during the rebuild procedure in one region, Cassandra clients in the other regions won’t see any impact, as they are always directly exchanging data with Cassandra nodes in their local region, allowing for region-by-region SZFT transition.
Challenge 2: Lack of uniform spare server capacity across Zones
For the multi-rack setup where each Cassandra rack is a zone, we need to ensure there are always enough zones available (i.e., number of zones ≥ replication_factor). In addition, the spare capacity in each of the zones needs to be uniform for each of the racks to be equally scaled when scaling the cluster.
This can appear less challenging in cases where the size of the clusters is small and hence the amount of scaling needed is small or if there are stronger guarantees of spare capacity in all zones. However in practice, it is very possible to have the available capacity spread non-uniformly across the zones. In such a scenario, performing a potentially urgent horizontal upscaling of the cluster would inevitably lead to sacrificing the SZFT property of the cluster.
Regardless of the capacity situation, we should be prepared for handling such a scenario. When both the SZFT property and the urgent need for horizontal scale can not be met at the same time, we have to prioritize the immediate performance needs of the cluster via the horizontal scale. It is important to keep in mind that, once additional capacity eventually arrives at the other zones, we should be able to “relocate” the nodes added during the scale to the desired zones with minimal number of node replacements, ultimately achieving SZFT. The entire process is quite operationally demanding, and we need refined automation to significantly reduce manual effort.
We are not going to expand on this challenge in this blog, as it pertains to the server capacity management aspect. We at Uber have ensured that we are prepared to tackle such a scenario in a fully automated manner, thanks to our Stateful Platform team, which runs our underlying storage management and control plane platform.
Highlights
The success of this critical project is measured as follows:
- The rollout has completed on the vast majority of the Cassandra fleet. For months after the rollout, no issue has been seen.
- During the rollout, no major incident was caused.
- The whole exercise was entirely transparent for our stakeholders.
- We conducted multiple tests in which we virtually brought down an entire production zone, and Cassandra’s stakeholders were unaffected!
Conclusion
In this article, we have showcased the Cassandra deployment at Uber. We have also highlighted the challenges of achieving single zone failure tolerance, and dived deep into the solutions.
Cover Photo Attribution: This image was generated using ChatGPT.
Apache® and Apache Cassandra® are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Oracle, Java, MySQL, and NetSuite are registered trademarks of Oracle and/or its affiliates. Other names may be trademarks of their respective owners.

Long Pan
Long Pan is a Senior Software Engineer on the Cassandra team at Uber. He is deeply involved in a broad range of activities to maintain and enhance Cassandra at scale as a distributed database. His work spans operational improvements and development projects. Outside of work, he enjoys cooking and exploring new places.

Gopal Mor
Gopal Mor is a Sr. Staff Software Engineer and a Tech Lead Manager on the Cassandra team at Uber. He works on distributed systems, web architectures, databases, and reliability improvements. He has been part of the industry since monoliths and traditional architecture; championed resolving tail-end issues for performance, latency, and efficiency. In his most recent role, he leads and manages the team responsible for Cassandra at Uber. In his spare time, he likes to tinker with IoT devices, raspberry pi, FPGAs, and ESP32.

Jaydeepkumar Chovatia
Jaydeepkumar Chovatia is a Sr. Staff Software Engineer on the Storage Platform Org at Uber. He has contributed to big projects in core Cassandra as well as upstreamed patches to Open source Cassandra. His primary focus area is building distributed storage solutions and databases that scale along with Uber's hyper-growth. Prior to Uber, he worked at Oracle. Jaydeepkumar holds a master's degree in Computer Science from the Birla Institute of Technology and Science with a specialization in distributed systems.

Shriniket Kale
Shriniket Kale is an Engineering Manager II on the Storage Platform org at Uber. He leads Storage Foundations, which has teams focusing on three major charters (MySQL and MyRocks, Docstore Control Plane and Reliability, and Cassandra). These teams power the Storage Platform, on which all critical functions and lines of business at Uber rely worldwide. The platform serves tens of millions of QPS with an availability of 99.99% or more and stores tens of Petabytes of operational data.

Gabriele Di Bernardo
Gabriele Di Bernardo is a former Senior Software Engineer on the Stateful Platform team at Uber. His focus was on efficient and reliable node placement, large-scale fleet automation and automatic data center turn-up/tear-down.
Posted by Long Pan, Gopal Mor, Jaydeepkumar Chovatia, Shriniket Kale, Gabriele Di Bernardo
Related articles


Most popular

MySQL At Uber

Adopting Arm at Scale: Bootstrapping Infrastructure

Adopting Arm at Scale: Transitioning to a Multi-Architecture Environment
