Navigating the LLM Landscape: Uber’s Innovation with GenAI Gateway
11 July 2024 / Global
Introduction
Large Language Models (LLMs) have emerged as pivotal instruments in the tech industry, unlocking new avenues for innovation and progress across various sectors. At Uber, the impact of LLMs is particularly noticeable, with over 60 distinct use cases being identified in diverse domains, ranging from process automation to customer support and content generation. As teams at Uber embark on the journey of integrating LLMs into their products, several challenges have surfaced. Notably, the disparate integration strategies adopted by different teams have led to inefficiencies and redundant efforts.
To address these challenges and harness the growing demand for LLMs, Uber’s Michelangelo team has innovated a solution: the GenAI Gateway. The GenAI Gateway serves as a unified platform for all LLM use cases within Uber, offering seamless access to models from various vendors like OpenAI and Vertex AI, as well as Uber-hosted models, through a consistent and efficient interface. The GenAI Gateway is designed to simplify the integration process for teams looking to leverage LLMs in their projects. Its easy onboarding process reduces the effort required by teams, providing a clear and straightforward path to harness the power of LLMs. In addition, a standardized review process, managed by the Engineering Security team, reviews use cases against Uber’s data handling standard before use cases are granted access to the gateway. If testing is successful these projects go through our standard, cross-functional software development process. The centralized nature of the gateway also streamlines the management of usage and budgeting across various teams, promoting greater control and operational efficiency in the integration of LLMs across the company.
Design & Architecture
A pivotal design decision was to mirror the HTTP/JSON interface of the OpenAI API. This strategic choice is rooted in OpenAI’s widespread adoption and thriving open-source ecosystem highlighted by libraries like LangChain and LlamaIndex. This alignment fosters seamless interoperability, ensuring GenAI Gateway’s compatibility with existing open-source tools and libraries while minimizing the need for adjustments. Given the rapid evolution of the open-source community, a proprietary interface would risk becoming quickly outdated. By aligning with OpenAI’s interface, GenAI Gateway stays in step with cutting-edge advancements. This approach not only streamlines the onboarding process for developers but also extends GenAI Gateway’s reach, allowing users to access LLMs from various vendors, like Vertex AI, through a familiar OpenAI API framework. See Figure 1 below for the high-level architecture diagram.
The following code snippets demonstrate how to use GenAI Gateway to access LLMs from different vendors with unified interface:

Answer from gpt-4: The capital of the USA is Washington D.C.
Answer from chat-bison: Washington, D.C. is the capital of the USA.
Answer from llama-2-70b-chat-hf-0: The capital of the United States of America is Washington, D.C.
As can be seen from above, developers write code as if they’re using native OpenAI client, while being able to access LLMs from different vendors.
Architecture-wise, GenAI Gateway is a Go service that acts as an encompassing layer around the clients for third-party vendors, complemented by the in-house serving stacks tailored for Uber’s LLMs.
Our approach to integrating with OpenAI involved developing an internal fork of the Go client implementation sourced from the GitHub repository. When it came to integrating Vertex AI, specifically for accessing PaLM2, we faced a challenge: the absence of a suitable Go implementation at that time. We took the lead in developing our version and subsequently open-sourced it, contributing to the broader community. We encourage community engagement, inviting contributions ranging from bug reports to feature requests. This library mainly focused on features like text generation, chat generation, and embeddings. At the time of writing this blog, Google has also published their Vertex AI Prediction Client but we will continue to support our library because of its ease of use.
For Uber-hostedLLMs, we’ve engineered a robust serving stack built upon the STOA inference libraries, to optimize performance and efficiency. This blend of external integration and internal innovation reflects our commitment to staying at the forefront of LLM technology and contributing to its evolving ecosystem.
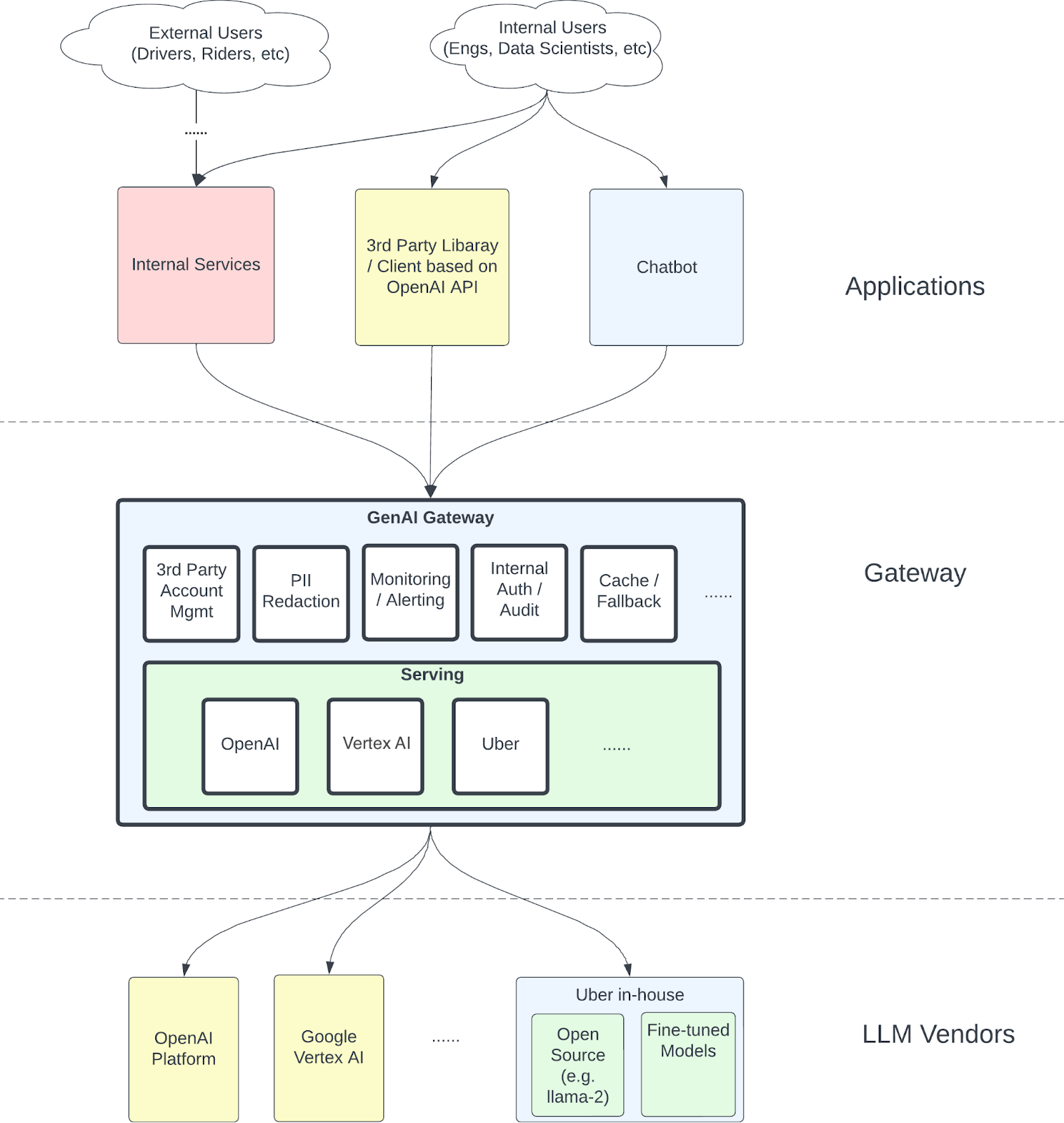
Beyond its serving component, an integral facet of GenAI Gateway is the incorporation of a Personal Identifiable Information (PII) redactor. Numerous studies have underscored the susceptibility of LLMs to potential data breaches, presenting significant security concerns for Uber. In response, GenAI Gateway incorporates a PII redactor that anonymizes sensitive information within requests before forwarding them to third-party vendors. Upon receiving responses from these external LLMs, the redacted entities are restored through an un-redaction process. The goal of this redaction/un-redaction process is to minimize the risk of exposing sensitive data.
Complementing its core functionalities, GenAI Gateway incorporates additional components designed for authentication and authorization, metrics emission to facilitate reporting and alerting, and the generation of audit logs for comprehensive cost attribution, security audit purposes, quality evaluation, and so on. All these components are seamlessly integrated into Uber’s in-house ecosystem, ensuring a cohesive and synergistic integration that aligns with the organization’s broader technological framework. This strategic alignment underscores GenAI Gateway’s commitment to not only meeting immediate needs, but also seamlessly integrating with Uber’s established infrastructure for enhanced efficiency and compatibility.
Today, GenAI Gateway is used by close to 30 customer teams and serves 16 million queries per month, with a peak QPS of 25.
Comparison to similar offering
Although Databricks recently introduced the MLflow AI Gateway that shares several features with our GenAI Gateway, GenAI Gateway stands apart in key ways from the MLflow AI Gateway. Our GenAI Gateway closely mirrors OpenAI’s interface, offering benefits not found in the MLflow AI Gateway, which has adopted a unique syntax for LLM access (create_route and query). In addition to aligning with OpenAI’s interface, GenAI Gateway enables a consistent approach to data security and privacy across all use cases. Furthermore, our platform extends beyond Python, providing support for Java and Go, which are the primary programming languages used in Uber’s backend infrastructure. This multi-language support, combined with our focus on security and alignment with OpenAI’s familiar interface, underscores GenAI Gateway’s unique position in the realm of LLM platforms.
Challenges
The aim is for this platform to emulate the performance and quality of the native OpenAI API so closely that the transition is imperceptible. In this section of our blog, we will delve into the challenges encountered in achieving this seamless integration, particularly through the lens of handling PII.
PII Redactor
The PII redactor, while essential for privacy and security, introduces challenges to both latency and result quality. To understand how PII redactor introduces these challenges, we first need to understand how PII redaction works.
The PII redactor scans input data, identifying and replacing all instances of PII with anonymized placeholders. Its sophisticated algorithm adeptly recognizes a wide range of PII categories. Each type of PII is substituted with a unique placeholder–for example, names are converted to ANONYMIZED_NAME_, while phone numbers are changed to ANONYMIZED_PHONE_NUMBER_. To maintain distinctiveness, these placeholders are assigned sequential numbers, creating unique identifiers for each occurrence: the first name in a dataset is labeled as ANONYMIZED_NAME_0, followed by ANONYMIZED_NAME_1 for the second, and so forth. The following example illustrates this process in action:
Original Text
George Washington is the first president of the United States. Abraham Lincoln is known for his leadership during the Civil War and the Emancipation Proclamation.
Anonymized Text
ANONYMIZED_NAME_0 is the first president of the United States. ANONYMIZED_NAME_1 is known for his leadership during the Civil War and the Emancipation Proclamation.
The mapping of PII data to anonymized placeholders is used in the un-redaction process that restores PII data from anonymized placeholders back to its original form, before returning the result to users.
Depending on the location the PII data is in the input, the same word can be redacted to different anonymized placeholders as it will be appended with different sequential numbers:
Original Text
Abraham Lincoln is known for his leadership during the Civil War and the Emancipation Proclamation. George Washington is the first president of the United States.
Anonymized Text
ANONYMIZED_NAME_0 is known for his leadership during the Civil War and the Emancipation Proclamation. ANONYMIZED_NAME_1 is the first president of the United States.
Latency
While most additional components in GenAI Gateway are lightweight, the PII redactor, by nature of scanning and anonymizing entire requests, incurs added latency proportional to the length of the input request. In cases where the input request is notably large, such as a few thousand tokens, the PII redactor alone can introduce a latency of several seconds. To address this, we’ve transitioned to a CPU-optimized model, resulting in a substantial 80%+ reduction in latency, without compromising accuracy. Furthermore, we are in the process of assessing more advanced models, including one that leverages GPU technology, to further enhance the processing speed and overall efficiency of the PII redactor.
Quality
The PII redactor can inadvertently impact the quality of results. Its process of anonymizing sensitive data, while safeguarding user information, sometimes strips away crucial context, thereby affecting the response quality of LLMs. For example, a query like “Who is George Washington?” is transformed into “Who is ANONYMIZED_NAME_0” for LLM processing. This anonymization can hinder LLMs’ ability to generate relevant responses due to the loss of specific contextual information.
Furthermore, the PII redactor’s mechanism presents unique challenges in scenarios like LLM caching and Retrieval Augmented Generation (RAG). LLM caching, which stores responses for frequently asked questions to facilitate quick retrieval, faces a dilemma. Anonymized queries, such as “Who is George Washington?” and “Who is Abraham Lincoln?”, become indistinguishable post-redaction, leading to potential inaccuracies in cached responses. Similarly, RAG, which relies on fetching pertinent documents to aid LLMs in response generation, struggles with the inconsistencies introduced by anonymization. For instance, embedding a historical article about the American Revolutionary War might involve different anonymized placeholders for the same entity in offline and online contexts, leading to the retrieval of incorrect documents.
These challenges highlight a fundamental issue: the difficulty in linking anonymized placeholders back to their original entities, causing errors in cached results or document retrieval. While maintaining a global table mapping original entities to anonymized placeholders is impractical, we are exploring solutions: One approach encourages customers to use Uber-hostedLLMs, which do not require PII redaction. Simultaneously, we are evaluating the security assurances of third-party vendors to consider the possibility of forgoing the PII redactor entirely, striving to balance privacy concerns with operational effectiveness.
Other Challenges
Beyond the previously mentioned difficulties with PII redaction, the GenAI Gateway encounters additional, diverse challenges. The ever-evolving landscape of Large Language Models (LLMs) in recent months has prompted us to dynamically adjust our priorities. For instance, the recent introduction of GPT-4V shook things up by altering the request interface to accommodate image URLs and base64-encoded images. Fortunately, the responsive open-source community swiftly proposed solutions to seamlessly adapt to this change.
Given that GenAI Gateway’s core functionality revolves around forwarding requests to relevant LLM vendors, its availability is closely tied to the operational status of these vendors. In the event of a vendor outage, effective communication with users is crucial to prevent any misattribution of issues to the gateway itself. To bolster resilience, we are actively exploring the possibility of incorporating Uber-hostedLLMs as a fallback option when a third-party vendor encounters downtime.
Use Case: Summarisation of Chats for Agents Resolution
In our continuous pursuit of enhancing customer support efficiency, Uber leverages large language models (LLMs) to streamline the process for our customer support agents. The primary focus is on swiftly summarizing user issues and suggesting potential resolution actions, significantly reducing the time it takes to address user queries. This not only expedites query resolutions but also contributes to an overall improved user experience. We leverage LLMs internally for following
- Enhance chatbot-to-agent transitions, providing agents with concise summaries of prior interactions for improved understanding, faster resolution and addressing key challenges
- Furnish agents with crucial background information and user sentiments, enabling empathetic and contextually accurate support.
- Implement automatic summarization of contact interactions, reducing manual summarization time by 80% and improving operational efficiency.
Impact
The implementation of LLMs has proven highly beneficial, with 97% of generated summaries found to be useful in resolving customer issues. Agents report significant time savings in reading and documentation, thereby enhancing their overall productivity. The agents are able to revert back to users 6 seconds faster than before. We are generating ~20 million summaries per week leveraging the LLMs, which we plan to expand to more regions and contact types in the future.
In essence, our utilization of LLMs at Uber transcends mere automation–it’s a strategic enhancement focused on empowering our customer support agents to provide faster, more accurate, and empathetic resolutions. All with the goal of delivering an unparalleled experience to our users.
How Gen AI Gateway is used
Within Uber’s Customer Obsession organization, the CO Inference Gateway was initially employed to expose various ML Task-based API contracts internally to other services, abstracting out different ML Model hosts. For Summarization, we expanded this service to include a new Generation ML Task for Text, Chat, and Embedding Generation. This extension enables connections to both Open AI and Google Vertex AI models, fostering flexibility and adaptability.
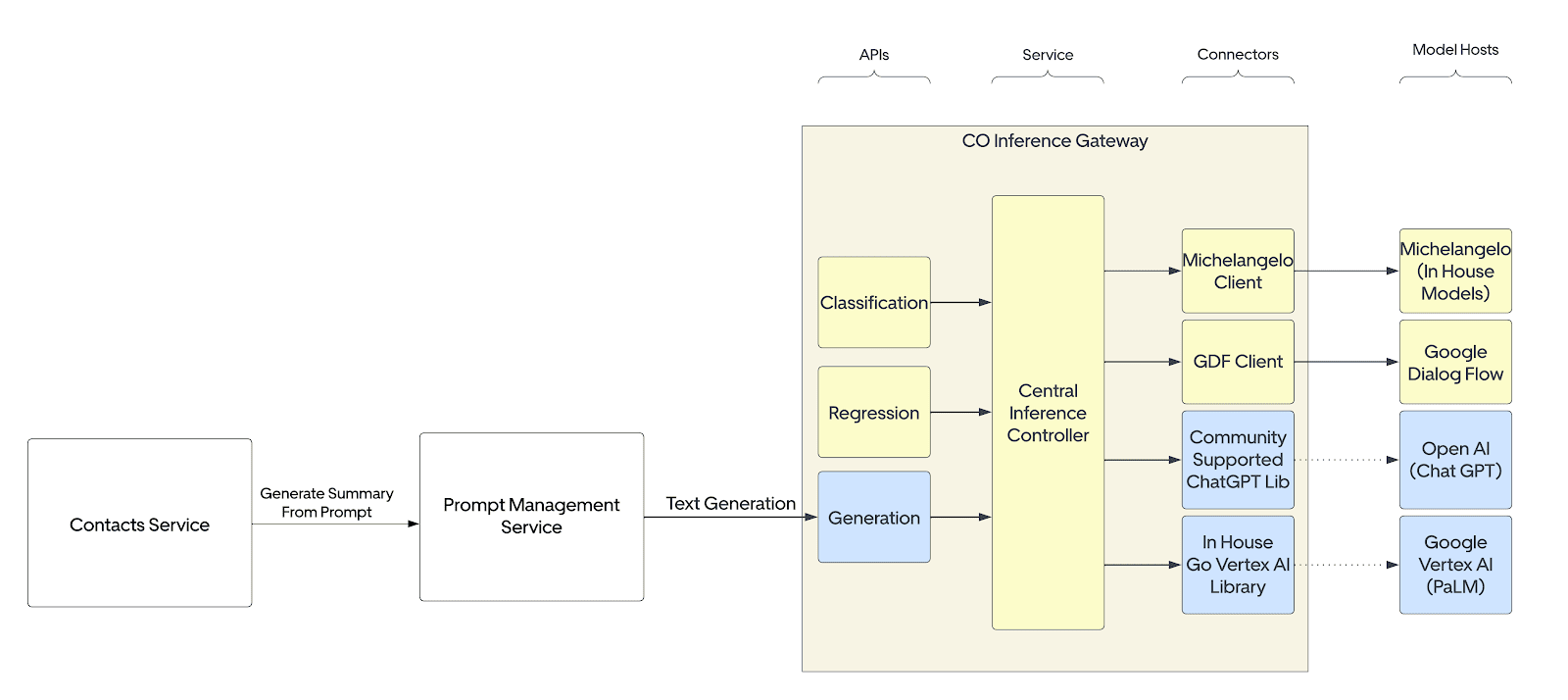
Encountering challenges such as PII Redaction, Cost attribution, and the imperative for a centralized service at Uber to connect with any external Language Model (LLM), we made a strategic decision to leverage the Gen AI Gateway instead of directly calling external models. This decision was guided by the need for a comprehensive solution that not only addresses challenges effectively but also ensures a robust and secure integration. By doing so, we navigate complexities and optimize the utility of our AI-powered solutions, aligning with Uber’s commitment to innovation and excellence in customer support.
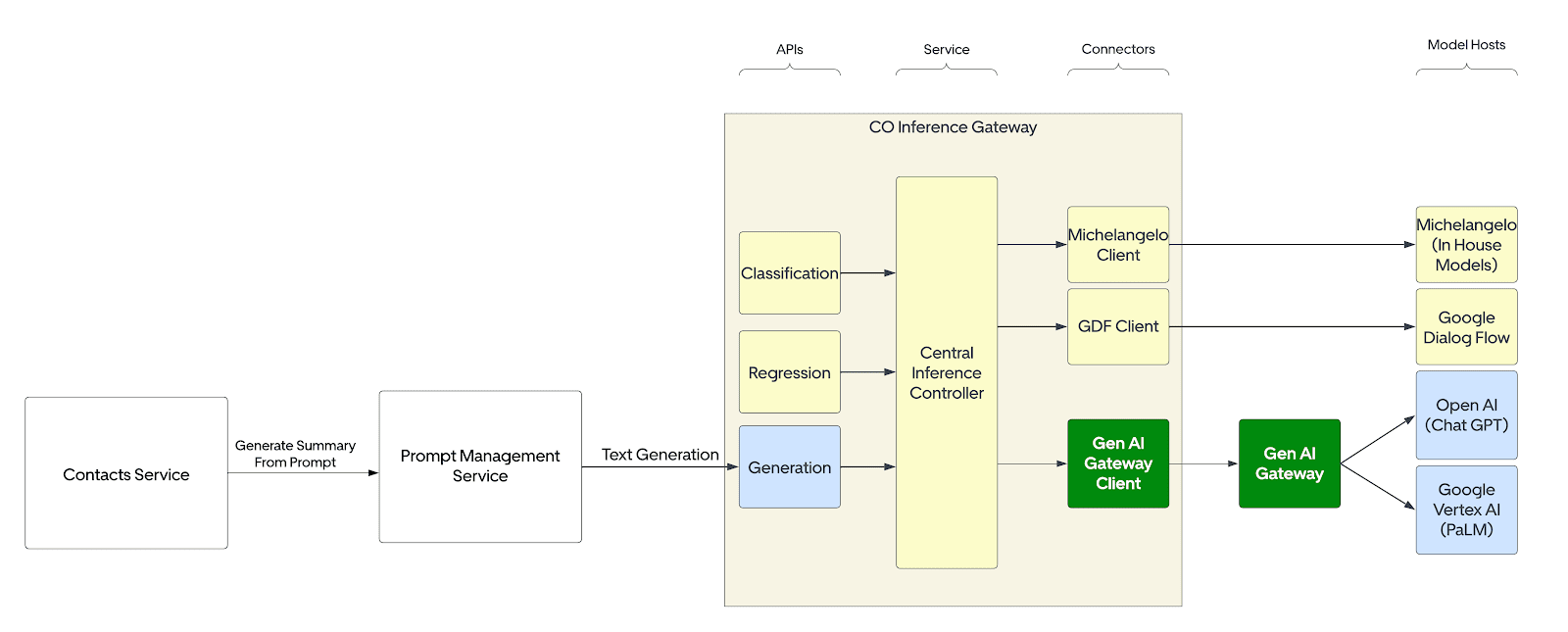
Prompt
Following is a sample Prompt for the summarisation of contact tickets. We provide a few examples in the prompt context for few-shot learning.
The following is a conversation between an Uber Customer support Bot called BOT, possibly a customer support agent called AGENT and an Uber Eats Customer called USER. Provide a detailed breakdown of the conversation. Identify all issues or intents and associated sentiments from the user. Extract the most pertinent part of user utterances and agent responses for each identified problem.
input:
{{conversation_log}} // Conversation log is the actual message history between customers, chatbots and agents.
Learnings
In reflecting on our journey with LLMs, a fundamental lesson stands out: the critical need for adaptability in the face of the rapidly evolving LLM landscape. As we delve deeper into the realm of advanced LLM applications, the importance of skillfully managing the interplay between ever-changing technologies, user privacy, and efficiency becomes increasingly evident. This landscape is constantly shifting, and our dedication to continuous improvement is more crucial than ever. Navigating these dynamics with agility and foresight is pivotal to our mission, ensuring that we not only keep pace with technological advancements but also uphold our commitment to user privacy and system efficiency.
Future Works
Looking ahead, our vision for the GenAI Gateway is to elevate and refine its capabilities to better serve our users. A key focus is on enhancing the onboarding process for new models. Whether these are bespoke, fine-tuned models tailored to specific needs or those sourced from the vibrant open-source community, our goal is to make their integration as fluid and user-friendly as possible. Moreover, we are keen on augmenting the gateway with advanced features that address the dynamic challenges of working with Large Language Models. This includes implementing intelligent LLM caching mechanisms, developing robust fallback logic, and introducing sophisticated hallucination detection. Safety and policy guardrails are also on our agenda to ensure that our platform remains secure and compliant with evolving standards.
In our journey to expand the gateway’s capabilities, we also recognize the importance of tapping into the vast potential of the open-source ecosystem. To this end, we are actively working towards integrating with libraries. This will not only enhance the functional breadth of our system, but also make it more versatile, enabling our users to explore and leverage a broader range of solutions. These future endeavors underscore our commitment to continually evolve the GenAI Gateway, ensuring it remains a cutting-edge, versatile, and secure platform for harnessing the power of LLMs.
Conclusion
LLMs have become a transformative force. The integration of LLMs at Uber, however, has not been without challenges. Inconsistent integration strategies and the absence of a standardized approach have led to inefficiencies and difficulties in monitoring costs and vendor usage.
Addressing these issues, Uber’s Michelangelo team developed the GenAI Gateway, a unified platform facilitating access to LLMs from multiple providers, including OpenAI and Vertex AI, as well as Uber’s in-house models. This platform streamlines the integration process, ensuring compliance with privacy and security standards and efficient usage management. GenAI Gateway’s design, mirroring the OpenAI API, ensures compatibility with existing tools and maintains pace with the evolving open-source community. It also features a PII redactor, enhancing security. This strategic development of the GenAI Gateway, coupled with its focus on operational efficiency and alignment with Uber’s broader technological framework, exemplifies Uber’s commitment to innovation while addressing the dynamic challenges of working with LLMs.
Acknowledgments
We could not have accomplished the technical work outlined in this article without the help of various engineering teams, Uber AI, and the Uber Customer Obsession Team. We would also like to thank the various product teams working with us in adopting Gen AI Gateway.
Cover Photo Attribution: The “Artificial Intelligence, AI” image is covered by a CC BY 2.0 license and is credited to mikemacmarketing. No changes have been made to the image (source).
Vertex AI™, PaLM™, Google Dialogflow™ and Go™ are trademarks of Google LLC and this blog post is not endorsed by or affiliated with Google in any way.

Tse-Chi Wang
Tse-Chi Wang is a Senior Software Engineer on Uber's AI Serving team based in Seattle. He’s one of the main contributors to GenAI Gateway.

Roopansh Bansal
Roopansh Bansal is a Senior Software Engineer in Uber’s Customer Obsession Organization, based out of San Francisco. He collaborated with Uber AI to evolve Gen AI Gateway into what it is today. He is the primary author of the Vertex AI Go Library.
Posted by Tse-Chi Wang, Roopansh Bansal
Related articles




Most popular
Important Update: Changes to App Ride Pickup Location at Helsinki-Vantaa Airport

Case study: how the University of Kentucky transformed Wildcab with Uber

How Uber Eats fuels the University of Miami Hurricanes off the field
