
The performance of Uber’s services relies on our ability to quickly and stably launch new features on our platform, regardless of where the corresponding service lives in our tech stack. Foundational to our platform’s power is its microservice-based architecture, a commonly used structural style where applications consist of interoperating services.
Microservice architectures, which can support stable deployments and modularity, are well-known for being scalable. With diverse engineering teams at Uber working on interoperating services, it’s important to ensure that our stack can both safely roll out new changes and reliably reuse parts of the architecture in a modular way. Taken together, these functionalities allow for high developer velocity and quick release turnaround times, giving us the flexibility to build on independent schedules while still meeting service level agreements (SLAs).
One of the most effective ways of facilitating this stability and modularity comes from allowing multiple systems to co-exist in a microservice architecture, often referred to as multi-tenancy. Using tenants, which could be tests, canary releases, shadow systems, or even service tiers or product lines, enables us to guarantee code isolation and make routing decisions based on traffic tenancy. Tenancy for both data-in-flight (e.g., requests or messages in the messaging queue) and data-at-rest (e.g., storage or persistent caches) allows for isolation and fairness guarantees, as well as tenancy-based routing opportunities. Multi-tenancy helps us achieve a variety of functions on a simple microservice stack, including an improved integration testing framework, shadow traffic routing, recording and replaying traffic, hermetic replay of live traffic for experimentation, capacity planning, realistic performance prediction, and even running multiple product lines at once.
Taken together, these benefits of multi-tenancy facilitate a more flexible, scalable microservice architecture that allows for both greater productivity and improved application performance, benefiting engineers and platform users alike.
Microservice landscape
Microservice architectures allow teams to roll out new features and bug fixes for their services independent of other services, increasing developer velocity. For instance, imagine that a team owns four services (referred to together as System 1) with agreed upon SLAs that regularly interacts with multiple other services with their own SLAs.
In Figure 1, below, we demonstrate how the team’s four microservices, Services A, B, C, and D, interact. In this diagram, Service A receives a request from System 2. System 1 processes the request by connecting to Service B, which in turn connects to Service C and Service D.

In this example, if we make a change to Service B, we have to make sure it still interoperates well with Services A, C, and D. In a microservice architecture, we need to perform these integration testing scenarios to test a service’s interaction with other services in the system. Generally, there are two fundamental ways of conducting integration testing for a microservice architecture: parallel and testing in production.
Parallel testing
The first approach, parallel testing, necessitates the creation of a staging environment which looks and feels like the production stack, but is only used for handling test traffic. As depicted in Figure 2, below, this stack is always on and running production code, although it is isolated from the production stack and often operating at smaller scale:

During parallel testing, an engineering team implementing a change to the production service first deploys the service with the new code to the test stack. This approach allows developers to stably test any service without affecting production, making it easier to identify and contain bugs and other hiccups before release.
Parallel testing requires that test traffic never leaks to the production stack, which can be achieved by physically isolating the two stacks into separate networks and ensuring that test tools only operate in the test stack.
Although parallel testing can be a very efficient means of integration testing, it poses a few challenges that can affect the success of the microservice architecture:
- Additional hardware cost: Having to provision an entire stack for testing, along with all its datastores, message queues, and other infrastructure components, means additional hardware and maintenance costs.
- Synchronization issues: A test stack is only useful if it is identical to its corresponding production stack. As the two stacks deviate from each other, it becomes increasingly difficult for the test stack to mirror the production stack, and there is an additional burden on the infrastructure components to keep the stacks in sync.
- Unreliable testing: As teams deploy their experimental and potentially buggy code to the test stack, those services may or may not be able to operate correctly, leading to frequently failing tests. For example, suppose the team owning Service A triggers a parallel test to see if their new code works, but the test fails due to a bug in Service B. Since we’re testing in a completely different build as our production build, it would be difficult to diagnose where the bug is; moreover, we don’t know that changes made to Service A are safe until the test passes the entire flow, meaning we are blocked until the team owning Service B deploys clean code back to the test stack. This particular downside can be mitigated by having a routing framework to route traffic to yet another sandbox environment where the service-under-test is instantiated.
- Inaccurate capacity testing: To assess the capacity of the entire stack or sub-stack, we need to push test load on the test stack. If we want to test for a particular capacity, we have to increase the capacity of the test stack before we can apply the delta load, meaning the increase in target capacity over the current production load, on to the test stack. This delta load may not be able to saturate the test stack, making it unclear as to how much more capacity we should add to the production stack to achieve the target capacity.
Testing in production
Another approach to integration testing in a microservice architecture would be to make the current production stack multi-tenant and allow both test as well as production traffic to flow through it. Figure 3, below, shows one such example:
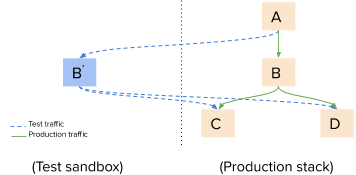
This rather ambitious approach means that we have to make sure every service in the stack is able to handle production requests alongside test requests.
In this approach, since we are testing Service B, the test build is instantiated in an isolated sandbox area which is allowed to access production Services C and D. We route test traffic to Service B’, the test build, while production traffic flows as usual through the production instances. Service B’ services only test traffic and not production traffic. Also, it is critical to make sure production traffic is not affected in any way by the test traffic.
Although this is a simplified view, it helps explain how multi-tenancy can help solve integration testing. There are two basic requirements that emerge from testing in production, which also form the basis of multi-tenant architecture:
- Traffic Routing: Being able to route traffic based on the kind of traffic flowing through the stack.
- Isolation: Being able to reliably isolate resources between testing and production thereby causing no side-effects in business-critical microservices.
The isolation requirement here is particularly broad since we want all the possible data-at-rest to be isolated, including configuration, logs, metrics, storage (private or public), and message queues. This isolation requirement is not only for the service that is under test, but for the entire stack, too.
Multi-tenancy paves the way for other use cases beyond integration testing, such as staged deployments and replaying traffic in the stack.
Canary deployments
When a developer makes a change to their service, even though the change is well reviewed and tested, we may not want to deploy the change to all the running instances of the service at once. This is to make sure the entire user base is not vulnerable should there be an issue or bug with the change being made. The idea is to roll out the change first to a smaller set of instances, called canaries. We then monitor the canaries with a feedback loop and gradually roll out the code change widely.
A canary can be treated as yet another tenant in our multi-tenant architecture, where canary is a property of a request that can be used for making routing decisions. With canaries, resources are isolated during deployments. At any given time a service might have a canary deployed to which all the canary traffic will be routed. The decision to sample requests as canary can be made closer to the edge of the architecture based on attributes of the request itself, such as user type, product type, and user location.
Capture/replay and shadow traffic
Being able to see how changes to a service fare while serving actual production traffic is an effective means of getting a strong signal on the safety of the change being made. Replaying previously captured live traffic or replaying a shadow copy of live production traffic in a hermetically safe environment is another use case of multi-tenancy.

In this case, we stub responses for any outbound calls made by the instance being tested. Capturing and replaying production traffic can be treated as a sub-category of integration testing since these use cases are within the realm of testing and experimentation.
Replay traffic is technically test traffic and can be part of test tenancy, allowing for isolation from other tenancies. With replay traffic, we have the flexibility to assign a separate tenancy to allow further isolation from other test traffic.
As such, an important feature of a multi-tenant architecture is its ability to protect and isolate multiple business critical product lines or different tiers of the user base.
Tenancy-oriented architecture
In a tenancy-oriented microservice architecture, tenancy is treated as a first class object. The notion of tenancy is attached to both data-in-flight as well as data-at-rest. Making a multi-tenant microservice architecture involves attaching context to incoming requests and propagating that context throughout the request’s lifecycle, which enables users to route requests based on that context.
Tenancy context
Since a microservice architecture is a group of disparate services running on an interconnected network, we need the ability to attach a tenancy context to an execution sequence. This context, which we can attach to a request as it enters an edge gateway, tells us about the tenancy of the request. We want this context to stay with the request for the life of the request and get propagated to any new requests that are generated in the same business logic context, preserving the tenancy for the sequence of requests.
Here is a simple tenancy context format and some examples:
|
{ “request-tenancy” : <product-code>/<tenancy-id>/<tenancy-tags>… } Examples: “request-tenancy” : “product-foo/production” |
Context propagation
In general, when any service in the call chain receives a request we want its tenancy context to be available with it because the service may leverage the tenancy context as part of its business logic. However, it is required that the service propagates the context further as it makes further requests as part of processing the same incoming request.
Most services may not need to look at the tenancy context, however some may assess the request context to bypass some business logic. For example, an audit service verifying users’ phone numbers may want to bypass the check for test traffic since the users involved in a test request are test users. Additionally, when running test traffic through a transaction processing services talking to a bank gateway to transfer funds for users, we might want to stub out the bank gateway, or alternatively, talk to the bank’s staging gateway (if one is available for testing) to prevent any real transfer of money. Tenancy context propagation can be achieved with open source tools like OpenTracing and Jaeger that enable distributed context propagation in a language and transport agnostic way.
Tenancy context should also be propagated to other data-in-flight objects, like messages in an Apache Kafka messaging queue. Newer versions of Kafka support adding headers and open source tracing tools can be used to add context to messages.
We might also want tenancy context to be propagated to data-at-rest, including all the data storage systems that are used by services for storing their persistent data, like MySQL, Apache Cassandra, and AWS. Distributed caches like Redis and Memcached can also be classified as data-at-rest. All the storage systems and caches leveraged by an architecture need to support storing context along with the data at a reasonable granularity to allow for retrieval and storage of data based on the tenancy context. At a high level, the only requirement from data-at-rest components is the ability to isolate data and traffic based on the tenancy.
Exactly how the data is isolated and how the tenancy context is stored along with the data is an implementation detail that is specific to the storage system.
Tenancy-based routing
Once we have the ability to tag a request with tenancy, we can route requests based on its tenancy. Such routing is crucial for testing in production, record/replay, and shadow traffic. Also, canary deployment requires routing the canary requests to particular service instances running in the isolated canary environments.
It is important to consider the deployment and services tech stack when identifying a routing solution that works seamlessly without overhead. Languages in which services are written as well as the transports and encoding they use to communicate with each other might need to be considered when selecting a fleet-wide routing solution. Open source service mesh tools like Envoy or Istio are also highly suited for providing tenancy-based routing which works agnostic to the service language and the transport or encoding used.
Generically, tenancy-based routing can be implemented either at the egress or ingress of the service. At the egress, the service discovery layer can help determine what service instance to talk to depending on the request’s tenancy. Alternatively, the routing decision can be made at the ingress and then the request can be re-routed to the correct instance, as shown in Figure 5, below:

In the example shown in Figure 5, a sidecar can be used to forward the request to a test instance if the request tenancy is test. A sidecar can be a process acting as a proxy to all the traffic entering the service, and is co-located with the service. The traffic is first received by the service’s sidecar where we can inspect the request’s tenancy context and, based on the context, make a routing decision.
We need additional metadata in the tenancy context depending on the use case we want to address. For example, for testing-in-production, we want to redirect test traffic to the test instance of a service if the service is under test. We can add additional information in the context that will allow this behavior, as shown below:
| { “request-tenancy” : <product-code>/<tenancy-id>/<tenancy-tags>… “services_under_test” : [ “foo” : { “redirect” : <test instance Id>, }, … ] } |
When we make a routing decision, we can check if the request-tenancy is test and if the request recipient is one of the services_under_test. If these conditions are satisfied, we route the request to the <test instance Id>.
Data isolation
We want to build an architecture in which every infrastructure component understands tenancy and is able to isolate traffic based on tenancy routing, allowing greater control within our platform to run different microservices, such as metrics and logs. Typical infrastructure components used in a microservice architecture are logging, metrics, storage, message queues, caches, and configuration. Isolating data based on its tenancy requires dealing with the infrastructure components individually. For example, we might want to start emitting tenancy context as part of all the logs and metrics generated by a service. This helps developers filter based on the tenancy, which might help avoid erroneous alerts or prevent heuristics or training data becoming skewed.
Similarly, when considering storage services, the underlying storage architecture needs to be taken into account to efficiently create isolation between tenants. Some storage architectures readily lean towards multi-tenancy. Two high-level approaches are to either embed the notion of tenancy explicitly alongside the data and co-locate data with different tenancies, or to explicitly separate out data based on the tenancy, as shown in Figure 6, below:

The latter approach provides better isolation guarantees, while the former often requires less operational overhead. For messaging queue systems like Kafka, we can either transparently roll out a new topic for the tenancy or dedicate a separate Kafka cluster altogether for that tenancy.
For data isolation, context needs to be propagated up to the infrastructure components. It is important to make sure services have minimal overhead with respect to data isolation. We would ideally want services to not deal with tenancy explicitly. Also, we would ideally want to place the isolation logic at a central choke point through which all the data flows. Gateways are one such choke point where the isolation logic can be implemented, and is our preferred approach. Client libraries can be another alternative to implement tenancy-based isolation, although coding language diversity makes it a bit harder to keep the logic in sync among all the language-specific client libraries.
Similarly for configuration isolation, we want the configuration data for a service to be tenancy-specific, thereby making sure configuration changes for one tenancy do not affect others.
Moving forward
Microservice-based architectures are still evolving and becoming instrumental facilitators of agility for both developers and organizations at large. A carefully planned multi-tenant architecture can increase developer productivity and support evolving lines of business.
Uber’s implementation of multi-tenancy has reaped various benefits, such as making automated rollout of code and configuration safe, which in turn improves developer velocity. The isolation guarantees of the multi-tenant architecture enabled Uber to re-utilize the same microservice stack for various purposes, including the test traffic.
Interested in building infrastructure that supports 14 million rides in cities around the world every day? Consider joining our team!

Amit Gud
Amit Gud is a senior software engineer on Uber's Infrastructure team.
Posted by Amit Gud
Related articles



Most popular

How medical schools support the next generation of doctors with Uber

Uber’s Journey to Ray on Kubernetes: Ray Setup
