
Overview
This blog post describes Uber’s journey towards utilizing hardware efficiently via better load balancing. The work described here lasted over a year, involved engineers across multiple teams, and delivered significant efficiency savings. The article covers the technical solutions and our discovery process to get to them–in many ways, the journey was harder than the destination.
Background
Better Load Balancing: Real-Time Dynamic Subsetting | Uber Blog was a related blog post that predates the work described here. We won’t repeat the background–we recommend skimming through the overview of our service mesh there. We’ll also be reusing the same dictionary. This post focuses on the workloads communicating via the service mesh explained above. This covers the vast majority of our stateless workloads.
Problem statement
In 2020, we started work to improve the overall efficiency of Uber’s multi-tenant platform. In particular, we focused on reducing the capacity required to run our stateless services. In this blog post, we’ll cover how individual teams making rational decisions led to inefficient resource usage, how we analyzed the problem and different approaches, and how, by improving load distribution, we got teams to safely increase CPU utilization and drive down costs. The post focuses on CPU only, since this was our primary constraint.
First, some context: at Uber, most capacity decisions are decentralized. While our platform teams provide recommended targets and tools like auto-scalers, the ultimate decision to adopt specific targets lies in each of the product teams/organizations. A budgeting process exists to curb unlimited allocations.
As part of the budgeting process, we noticed what we thought were unreasonably low utilization levels. However, attempts to increase the utilization were met with concerns from the product teams–they were rightly worried that increasing the utilization would risk the system’s reliability and affect their availability/latency goals.
The cause of the problem was presumed to be suboptimal network load balancing. Many workloads had tasks with CPU usage higher than average. Those outliers worked fine during normal operations, but struggled during failovers–and the desire not to break the SLAs pushed our average utilization downwards.
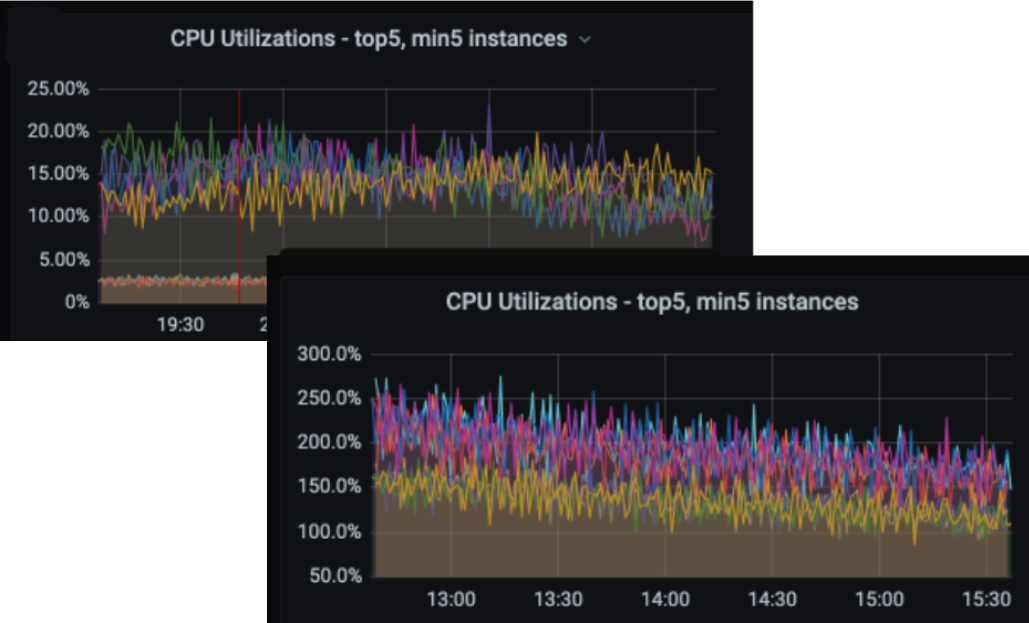
Asymmetry of impact
An important aspect of load imbalance is the asymmetry of its impact. Imagine a scenario where out of 100 workloads, 5 are under-utilized. This impacts efficiency, but the cost is relatively low–we’re not using 5% of our machines as efficiently as possible.
If the situation is reversed and the same 5 workloads are over-utilized, the situation is much more severe. We are likely affecting customer experience and potentially affecting the system’s reliability. The easy solution to avoid these hotspots is to reduce the average utilization of the whole cluster. This will now have a much more significant impact: 95% of the workloads are underutilized, meaning a much more significant waste of (financial) resources.
The forest and the trees
Since the outliers were easy to spot, we initially focused on fixing and chasing them one by one, trying to root-cause and fix each issue individually as soon as possible. The results of these individual fixes weren’t always as expected. Some of our changes had a lower impact than expected or only impacted a subset of the system. Similarly, other changes later on resulted in unexpectedly significant improvements. This was due to several independent issues being at play. This “forest of issues” resulted in the work being largely sequential–we would only find a new, more minor issue once its larger sibling was fixed.
In retrospect, the “surprise” part could have been mitigated with more analytical rigor–we could have understood the system more and collected more samples upfront. The sequentiality of the work would likely have been the same, though–it’s only through the process we learned how to understand and measure the system.
Measuring the impact
Perhaps surprisingly, one of the most disputed aspects of the project, until the very end, was measuring the impact. The discussions involved folks from different teams and organizations joining and leaving the project at different times. Each involved party had a valuable, but slightly different perspective on the problem, its priority, and potential fixes.
Just measuring the impact consistently was surprisingly complicated. Clearly, we should measure the outliers–we quickly settled on using the CPU utilization of the p99th most utilized task of a given workload. After some discussions, we agreed to use the average as the base, leaving us with p99/average as the imbalance indicator.
However, even that was surprisingly vague:
- A workload runs in multiple clusters across multiple zones. Should the p99/average be calculated across all its instances or for each cluster individually? If it’s per cluster, how do we weigh the results? This decision dramatically affects the final numbers.
- Workloads run in multiple regions, yet unlike zones, our regions exhibit strong isolation–where to send traffic is outside of networking control. Thus, the networking team might care about a different indicator than the business.
- A typical workload has a periodic pattern–a service might be most busy on a particular day of the week and underutilized at other times. Should we measure the imbalance at the peak only or throughout the day? If at peak, how long of a time frame should be considered peak? Do we only care about the single weekly peak?
- Our workloads typically run in an active-active pattern, with each region having some spare capacity for a potential failover. The load imbalance matters most during those failovers–should we try to measure it only then? If so, the frequency of our measurements will be reduced–typically, we would get a simple sample per week.
- The workloads are noisy. A service rollout typically results in an imbalance spike (as new containers come and warm up). Some workloads might be quick to roll out (per increment) but roll out tens of times per day via a CD pipeline. Other workloads are much slower, and a single rollout can take hours. Both types of rollouts can overlap with peak times. On top of that, there are “atypical events” like temporary performance regressions, traffic drains, load tests, or incident-related issues.
- Most workloads follow a “standard” pattern, but some (more critical) services have been partitioned into custom shards with separate routing configurations. Similarly, a small subset of essential workloads is additionally accessible by custom peer-to-peer routing. Finally, another small subset of services runs on dedicated hosts. These dimensions might affect our tracking.
Once we settle on the per-workload indicator, the problem expands to multi-service:
- How do we weigh the individual workloads in the final score?
- How do tiers (priority) of each service affect their weight in the final score?
- Does the fact that different workloads have different periodical patterns affect the score? Workloads typically have weekly and daily peaks, but those peaks are not simultaneous.
- Can we decompose the final indicator into sub-components to track the imbalance of individual zones or clusters?
The indicators must be available in real time for development and monitoring–here, we care about the highest precision possible, typically sub-minute. However, the same indicator must be available over long periods (years), where we need to roll the data up into day-sized chunks while keeping all the previous weighting considerations in mind.
Actual numbers:
Ultimately, we created a “Continuous imbalance Indicator.” For each workload, for each minute, we calculated the p99 (say, 5 cores) and average (say, 4 cores) CPU utilization. That, combined with the number of containers, allowed us to calculate “wasted cores.” For the example above, 10 containers would result in 10*4=40 (cores) usage, (5-4)*10=10 wastage cores, and the resulting indicator of 1+10/40=1.25. This mapped intuitively to the “standard” p99/average calculation of 125% that humans could do when debugging live.
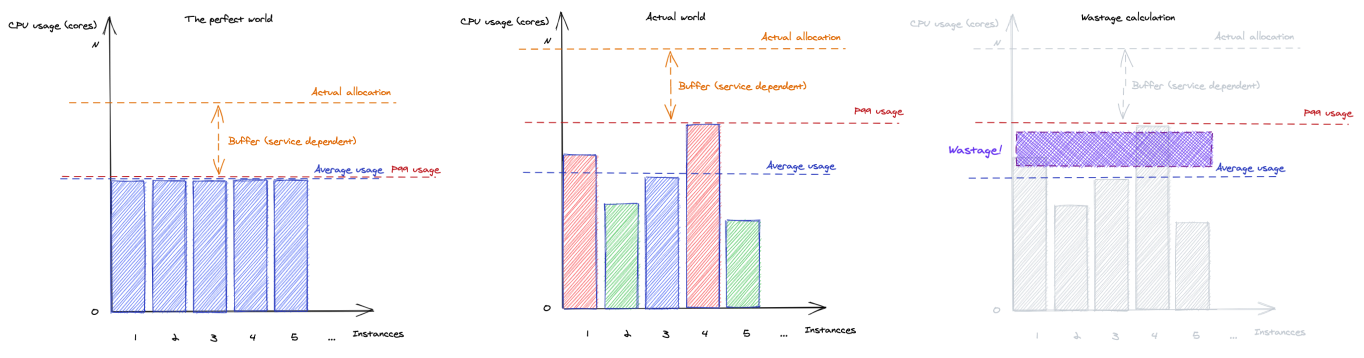
When done over time, this effectively became a ratio of areas under two curves: p99 and average utilization.

The benefit of this approach was that since the wastage and utilization were calculated in absolute numbers of cores, it allowed us to aggregate them in custom, arbitrary dimensions: per service, per service-per-cluster, per group of services, per cluster, per zone. Similarly, any time window (hour, day, week) naturally worked–it was as simple as summing up a range of integers. Additionally, the indicator naturally gives higher weight to “busy” periods–imbalance at the peak is more critical than imbalance off-peak. The downside was the difficulty of explaining the indicator to humans, but we found that the approximation as a “weighted p99/average” is acceptable.
An alternative approach of calculating a ratio of “weekly p99 of p99s” and “weekly average of averages” was easier to explain on an individual service basis but suffered from high sensitivity to random events (drains, failovers, load-tests, deployments), which made it noisy. Additionally, the cross-service weighting was less straightforward.
The above metrics were made available in real-time metrics in Grafana and long-term storage in Hive. We needed to write custom pipelines to pre-process the indicator daily for visualization.
Different slicing
A particular wrinkle about measuring load imbalance is worth calling out: how you slice your data dramatically affects the results. It is tempting to start with small slices (clusters, zones, regions) and then “average” the imbalance. Sadly, this doesn’t work in practice. For example, it’s possible to have two clusters with (averaged) p99/average ratio of 110%, but when looking across the whole workload, the imbalance might be much higher–up 140% in our cases. Similarly, combining two clusters of higher imbalances might result in a lower imbalance.
Addressing the issues
The first step: getting (hacky) data first
We started by building Grafana dashboards for real-time observability. This allowed us to measure impact individually per service in real time but didn’t help in understanding the root cause. While the assumption was that the load balancing was at fault, we didn’t *really* know. The initial problem was the lack of observability, where we faced two issues.
First, due to cardinality issues, our load balancers did not emit stats by each backend instance. With many services running thousands of containers and hundreds of procedures, this would have caused both a memory usage explosion in our proxy and made the stats not-query-able for even the medium-sized services. Luckily, an intern project that summer added an ability to emit stats on an opt-in basis (saving the proxy memory usage) on a new metrics namespace (leaving the existing stats intact). Together with roll-up rules, we could now introspect most services (as long as we only enabled the extra visibility for a few of them at a time).
Second, we had lost the ability to uniquely identify instances across our compute and networking stacks. At the time, we could see the CPU usage of each target but couldn’t easily map it to a container. The available “unique identifier” of a host:port would have broken our metrics (again, cardinality) due to our wide IP target range and dynamic port usage. The discussion of a proper solution had previously stalled for quarters. Ultimately, the networking stack implemented a short-term solution based on sorting IP addresses and emitting integer-based instance IDs. These were not stable across deployments, but together with some more hacky scripting, allowed us to get the data we needed.
This step provided important lessons:
- Always get the data first
- Well-placed, targeted, isolated hacks can be extremely useful
- You don’t need perfect observability to draw the correct conclusions
Manual analysis
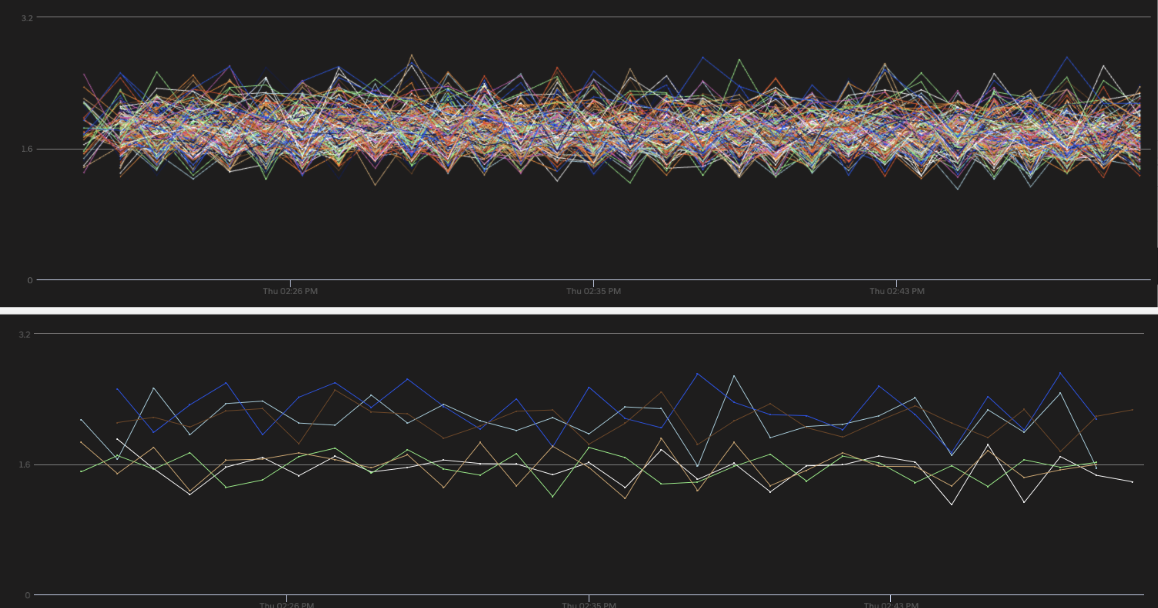
Once we had in-depth visibility into the issue, we hand-picked a few large services and tried to analyze the root causes. Surprisingly, the load balancing was not at fault–at a 1-minute window (our CPU stats resolution at the time), the RPS distribution was almost perfect. Each container was receiving an almost equal number of requests, with a difference below 0.1% for most applications. Yet, within the same window, the CPU utilization varied greatly.
After several weeks of investigations, we were able to quantify several independent reasons:
- Some significant sources of traffic forced imbalance. For example, many of our systems are “city aware,” with a city always being in a single region. This naturally drove different amounts of traffic to each region, with proportions changing continuously as cities woke up and fell asleep.
- Services ran across several hardware SKUs, both within and across clusters.
- Even the theoretically identical hardware showed significant performance differences.
Some of the imbalance was left in an “unknown” bucket. The majority of it turned out to be issues with our observability. We currently attribute the remainder (less than 20% of the original imbalance) to noisy neighbors.
The graph below shows the initial analysis for one of our biggest services from 2020.
Forced to build long-term aggregations
At that point, we wanted to start with any low-hanging fruit. The Better Load Balancing: Real-Time Dynamic Subsetting | Uber Blog gave us a few knobs we could tweak. This, however, instead of being easy, presented a new problem.
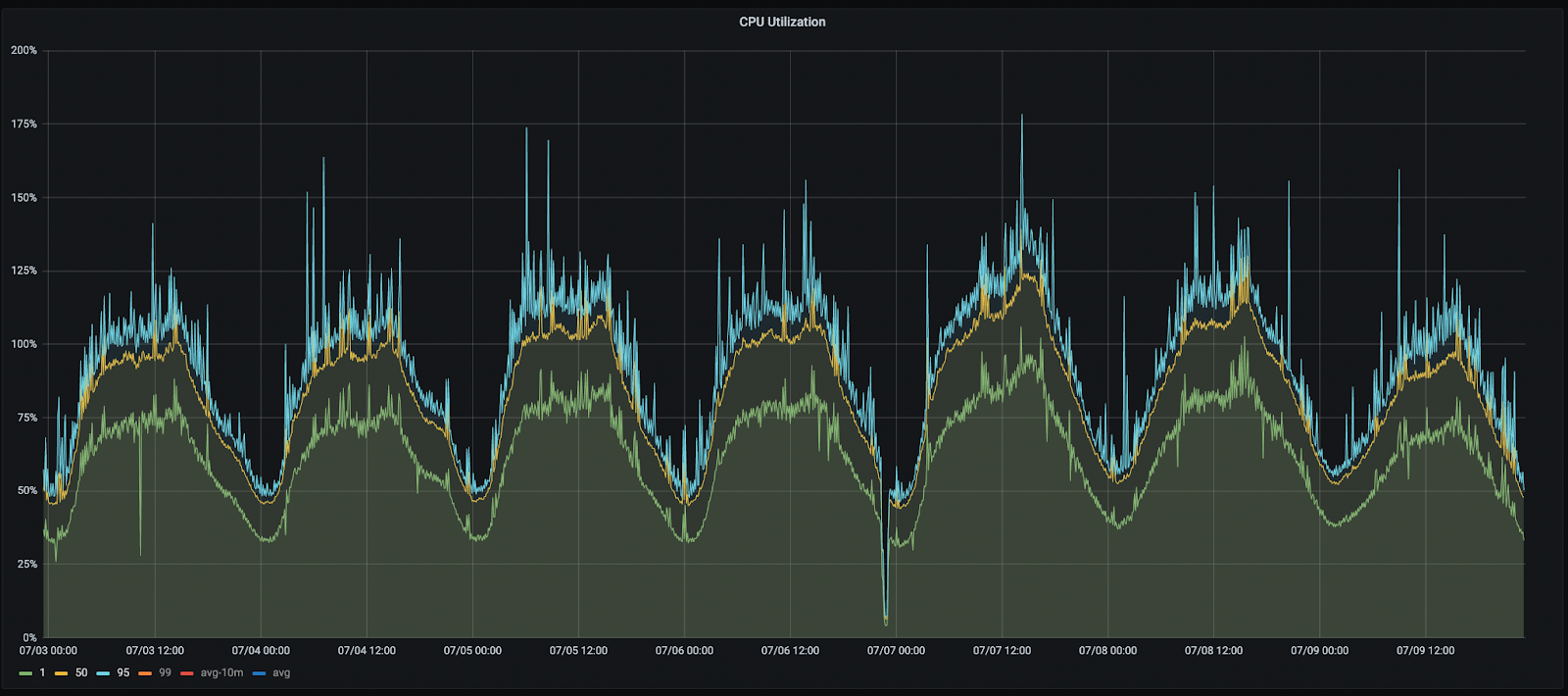
Our services exhibit heavy daily and weekly cycles (see above). On top of that, we frequently see spikes caused by failures, deployments, failovers, or ad hoc events. After rolling out a change, only a massive improvement (20%+) would be human-spottable, but our changes were too subtle.
This resulted in the observability decisions explained in the previous paragraphs. We built pipelines to aggregate data over long periods based on a stable and spike-resilient metric. On top of that, we could slice the metrics by clusters, zones, regions, or groups of services–this, in turn, lets us investigate more “suspicious” behavior.
Some pre-existing knobs let us reduce the service-mesh-induced part of the load imbalance, but it was a small fraction of the overall problem.
Possible solutions
An obvious first step was to look at low-level hardware configuration and OS settings. A few separate threads were started to look at these.
Solving the hardware heterogeneity required a more complicated process. Many approaches were possible, from:
- Modifying CFS parameters to make every host in the fleet appear the same despite the underlying hardware being different.
- This option was attractive but eventually dismissed due to unclear impact on various software stacks (like GOMAXPROCS). In retrospect, this also prevented us from configuration utilizing cpu-sets.
- Modifying host-to-cluster placement to achieve uniform clusters.
- Modifying the per-service cluster placement to guarantee stable, but not uniform, host selection.
- Moving to cloud-style host management, where each team would select a particular type of hardware.
- Many possible service mesh changes to achieve better load imbalancing.

Out of the possible options, changes to the service mesh were chosen for several reasons. Technically, changes on our layer required no changes to the physical layout of the data centers and no per-service migrations. Tactically, we could also deliver the changes quickly to most services.
Changes
Hardware
While root-causing variance within hardware SKUs we found many issues with hardware, firmware, and low-level software. They ranged across OS settings, CPU governor settings, firmware versions, driver versions, CPU microcode versions, or even kernel version incompatibility with Intel HWP. A general root cause of this was that, historically, once the hardware was ingested and turned up in the fleet, it was left untouched unless it had issues. Over time, though, that led to a drift between machines.
Uber runs in a mixed cloud/private setup, so we naturally experienced cloud-specific issues as well. Like other companies, we’ve seen multiple cases of theoretically identically provisioned VMs not performing similarly (this is still real). Similarly, we’ve seen cases where workloads running fine on-prem triggered issues on the cloud. To make it worse, the cloud meant less visibility into the details of the underlying infrastructure.
Fixing all these would be nearly impossible without a recently finished Crane project–we could measure, fix, and roll out changes to tens of thousands of machines without human involvement. All of the issues discovered are now detected and remediated automatically.
A clear benefit of these fixes was that they applied to every workload, no matter how it processed or originated its work (Kafka, Cadence, RPCs, timers, batch jobs, etc.). They were also giving us effectively free capacity, on top of the load imbalance improvements–some CPUs “became faster” overnight.
Observability
Observability was an interesting part of the problem. Before the project started, we knew we had limitations in the sample collections due to 1-minute window sizes, but we found more issues.
Technically, the problems were caused by interactions between cgroups, cexporter, our internal Prometheus metric scraper, and m3. In particular, due to the metrics being emitted as ever-increasing gauges, any delays in stats collection anywhere in the pipeline would result in (large) artificial spikes in percentile calculations. A lot of work was put into preserving the timestamps of the samples as well as gracefully handling both target and collector services restarts. An example issue was effectively breaking data collection for any large enough service.
A fascinating aspect of the observability issues was related to human interactions – or the fact that humans cannot be trusted. Early in the project, we asked service owners what level of container utilization resulted in user impact (increased latencies). Interestingly, several months later, after we had rolled out the fix, when we asked again, we received the same answer. Both statements couldn’t be valid since we knew the old data was wrong. Ultimately, human irrationality resulted in net efficiency wins: service owners ended up running their services (effectively) hotter while thinking nothing had changed.
Load balancing
As explained in Better Load Balancing: Real-Time Dynamic Subsetting | Uber Blog, our service mesh works on two levels. Initially, the control plane sends over assignments deciding how much traffic should be sent to each target cluster. The imbalance between clusters is decided here.
Later, the data plane follows this assignment, but then it’s responsible for picking the right host–a second level of within-cluster load balancing is happening here. While we considered changing this model, we kept it unchanged and rolled out two solutions for each level.
Inter-cluster imbalance
At Uber, services run in multiple zones in multiple regions. Because each zone is turned up at a different time, there is no way to guarantee the hosts in each zone are the same–usually, the newer the zones, the newer the generation hardware they have. The difference in performance of zones leads to CPU imbalance.
Our initial approach was to set a static weight for each zone; the weight will then be used in load balancing such that zones with faster hardware take more requests. The weight for each zone is calculated as the average of the Normalized Compute Unit (NCU) factor of each host deployed in that zone. The NCU factor measures host CPU/core performance based on a benchmark score, where the score depends on the product of core instructions-per-cycle (how much work is done by the core per clock cycle) and core frequency (how many clock cycles are available per second).
We could then send more traffic to more powerful/faster zones, using static zone weights as a multiplier.
Faster zones, with higher multipliers, will be routed with more traffic proportionally to increase CPU utilization, hence easing the CPU imbalance.
For example, if a service has deployed 10 instances in zone A (weight = 1) and B (weight = 1.2), the load balancing will be done as if B has 12 (10 * 1.2) instances so that B will receive more requests than A.
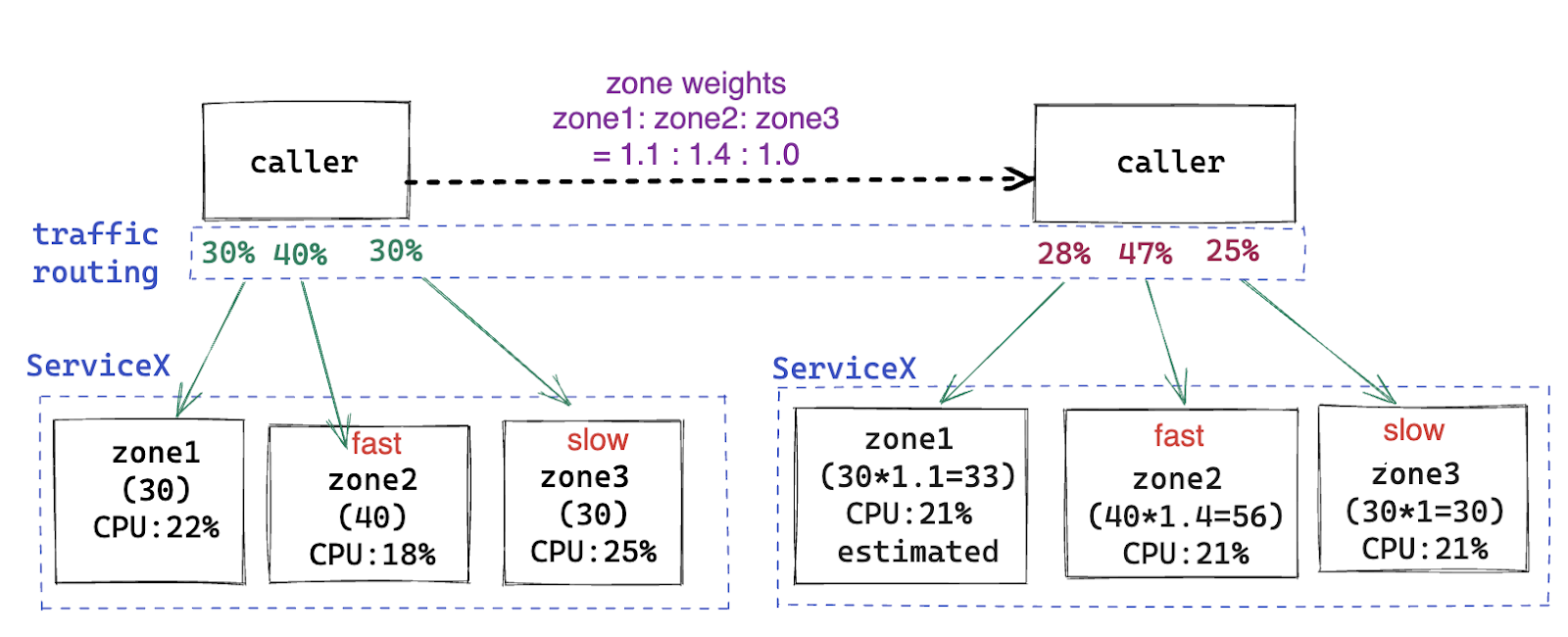
This approach worked surprisingly well–we were able to mitigate the majority of the imbalance with relatively little effort. However, there were a few issues:
- Zone weight is an estimated value (average NCU factor) across all hosts in a zone. However, a service could be extremely lucky/unlucky to be deployed on the fastest/slowest hosts in a zone.
- Though not frequently, the zones we operate on change due to turnup or turndown. Additionally, during turnup, we typically ingest hardware gradually, which might require multiple updates.
- Occasionally, we ingest new hardware into old zones to resize them or replace broken hardware. This hardware can be of a different type, resulting in a need to adjust the weights.
Dynamic Host-Aware Cluster Load Balancing
Hence, we took a second look at the problem and invested in an advanced solution: Host-aware Traffic Load Balancing.
This approach solves the drawbacks by looking at the exact hosts the service instances are deployed to, collecting their server types, and then updating the load balancing between clusters per service. This is achieved by making our discovery system aware of the mapping of a host (by IP), its host type, and weight such that for a given service deployed in a cluster, the discovery system could provide the extra weight info to our traffic control system. The diagram below shows an example:
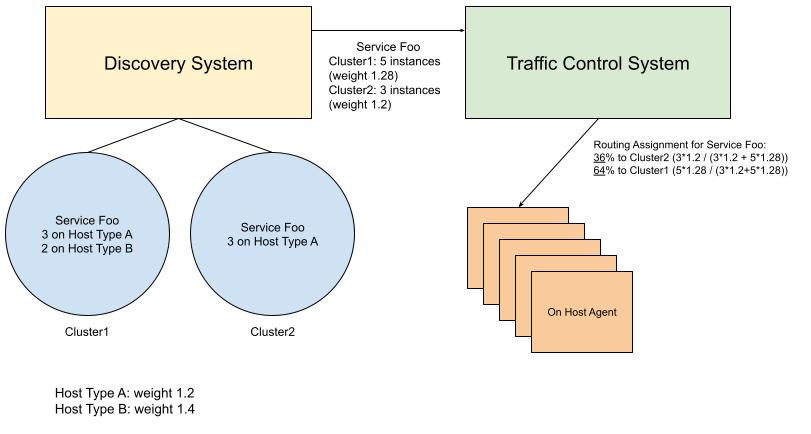
For service Foo, if we treat each instance equally, the load balancing ratio should be 37.5%/62.5% instead of 36%/64% shown in the example. The difference could become more significant if hosts are across multi-generations (we have up to 2X different weights between different hosts in our fleet).
Compared with the static weight approach, the host-aware load balancing adjusts weight per service dynamically to reduce inter-cluster imbalance. It’s also much easier to maintain, as new host types are introduced infrequently.
Intra-cluster imbalance
The intra-cluster imbalance, as explained earlier, is the responsibility of the on-host proxy (called Muttley). Each proxy had complete control of selecting the right peer for each request. The original load-balancing algorithm for Muttley used by all services was least-pending, which would send requests to the peer with the smallest number of known outstanding requests. While this resulted in almost perfect balancing of RPS when measured in 1-minute intervals, it still resulted in an imbalance of CPU utilization due to different hardware types.
Assisted Load Balancing (ALB)

We built a system where each backend assists the load balancer in selecting the next peer. An application middleware layer attaches load metadata as a header to each response. We effectively arrive at a coordinated system without central coordination. Where previously, each Muttley only knew about the load it caused (plus some information it could infer from the latencies), now, it learns about the total state of each backend dynamically. This state is affected not only by the backend itself (for example, running on slower hardware) but also by decisions made by other Muttleys. For example, if a backend is (randomly) selected into too many subsets, the system adjusts dynamically. This let us later on reduce the subset sizes for services on ALB.
While a brief mention in the Google SRE book partially inspired this approach, we made a few different choices. Both changes were related to each other and were attempted to simplify the approach. We intended to start, evaluate, and move to a more complicated solution later–luckily, we didn’t have to. Late in the implementation, we discovered a Netflix blog post, and we had arrived at similar conclusions independently.
Firstly, as the load metadata, we used the number of concurrent requests being processed, reported as an integer (q=1,q=2,..,q=100, etc). We considered reporting utilization, too, but that wasn’t immediately obvious (whether the reported utilization should be based on getrusage or cgroups). Cgroups were more natural since that’s what service owners were using to track their targets. Still, they presented more challenges–our foundation team was concerned about the cost of each docker container scraping cgroups independently and potential tight coupling if the cgroups layout was to change, including during the cgroupsv2 migration. We could have solved this by integrating with a host demon collecting the stats, but we wanted to avoid adding a new runtime dependency. In the end, just using a logical integer worked well enough (with some tweaks, explained below). Additionally, it allowed per-service overrides without changing the load balancer code–while the vast majority of the applications use the standard load indicator, some (asynchronous) applications override it to reflect their load better.
The second departure was the power of two random choices instead of the weighted round-robin. Since we had only a single integer as the load indicator, the pick-2 implementation seemed more straightforward and safer. Similarly to the above, this worked well enough that we didn’t need to change it. This approach turned out remarkably forgiving to failures across the whole range of our applications. Apart from typical crash looping or OOMing applications, we’ve had cases of bad/buggy implementations of the middleware not causing an incident. We speculate that since the weighted round-robin is more precise and “strict,” it would have likely performed “better” in some cases but could have resulted in thundering-herd-like scenarios.
Implementation-wise, each Muttley uses a modified moving average to keep the score of each peer over 25 previous requests–this value worked best in our testing. To arrive at meaningful numbers for lower RPS cases, we scale up each reported load by a thousand.
An interesting problem for the pick-2 load balancer is that the “most loaded” peer would never be selected. And because we discover peer load passively, we would also refresh its state, thus making it effectively unused until another peer gets even slower. We initially mitigated this by implementing a “loser penalty,” where every time a peer loses the selection, its “load value” is internally reduced–thus, with enough losses, the peer would be selected again. This didn’t turn out to work well for large-caller-instance-count-low-RPS scenarios, where sometimes it would take minutes for a peer to be reselected. Eventually, we changed this to a time decay where peers’ score is reduced based on the last selection time. We currently use a half-life of 5 seconds for score decay.
We also implemented a feature we call internally a “throughput reward.” This stemmed from empirical observations that the newer hardware handles concurrent requests better. We noticed that when load balancing across two peers on diverse hardware and both peers report the same “load value,” we, as expected, send more requests to the faster peer. However, the faster peer’s CPU utilization (processed=15, CPU=10%, Q=5) will remain lower than the slower peer (processed=10, CPU=12%, Q=5). To compensate for this, every time a peer “finishes” a request, we reduce its load slightly to push even more requests to it. The faster the peer is relative to other peers in the subset, the more “throughput rewards” it receives. This feature reduced the P99 CPU utilization by 2%.
A significant part (the majority) of the ALB design document was committed to the possible alternatives. We significantly considered, instead of attaching the load meta-data to each of the responses, using a central component to collect and distribute the data. The concern was that the metadata might consume a significant amount of available bandwidth. We internally have two systems that superficially seemed relevant. The first was the centralized health-checking system collecting health state from every container in the fleet in close to real time. The second was the real-time aggregation system described in the previous blog post.
Re-using either turned out to be unfeasible: the health checker system could have easily collected the load status from all containers, but after collection, that system was designed to distribute the health changes infrequently–the vast majority of the time, the containers remained healthy. The load balancing indicators, however, change constantly and by design. Since we operate a flat mesh (every container can talk to every container), we would need to constantly distribute data about millions of containers to hundreds of thousands of machines or build a new aggregation and caching layer. The load-report aggregation system, similarly, was not a match–it was operating on aggregated per-cluster values at several orders of magnitude lower cardinality.
Ultimately, we were happy with the chosen (response-header-based) approach. It was simple to implement and made the cost attribution easy – services pushing more RPS saw a higher bandwidth cost. In the absolute numbers, the cost of the extra metadata (~8 bytes per request) was almost invisible compared to the other tracing/auth metadata attached to each request.
The latency was an interesting aspect of the “distributed” vs. “centralized” collection of the load data. Theoretically, the response header approach is close to real-time since the load is attached to each response. However, since each Muttley needs to discover this independently and then average the response over the previous responses, the discovery might take some time for low RPS-based scenarios. The health-check-based approach would require a full round trip (typically ~5s), but be distributed to all caller instances immediately.
However, had we implemented it, we would have likely reduced the push frequency to something like 1 minute due to bandwidth concerns listed in the previous paragraph. This could have been enough to fix the hardware-induced skews but likely not other issues, like traffic spikes, slow-starting applications, or failovers. Both approaches could have likely worked slightly differently in different circumstances. Still, ultimately, we’re happy with the distributed approach–it’s easy to reason about and lacks centralized components that might fail.
One downside of the chosen approach was that it requires cooperation from the target services. While minimal work is required, applying it to thousands of microservices would be arduous. Luckily, most applications built in the last few years at Uber used common frameworks that allowed us to plug in the required middleware quickly. Several large services were not using the frameworks, but a concurrent multi-year effort had migrated almost all services. We found the decision to bet on the framework beneficial, as it had a compounding effect–service owners had one more reason to invest in migration. By the time we got to writing this post, virtually all services were on the common frameworks.
Static component – ALB v1.1
The initial rollout did not meet our hardware-induced imbalance reduction goals. The primary reason was that our hardware runs heavily underutilized most of the time–we have buffers for regional failovers and weekly peeks. It turned out that with relatively low container utilization, the old hardware can burst high enough for latency differences not to be visible while consuming more CPU time. While this meant the load balancing was working much better under stress (when we needed it), it made product engineers uncomfortable with our target utilization–the imbalance looked too high off-peak.
We added a second static component to the load balancing to address this. We utilized the fact that in our setup, the IP address of a host never changes. Since the proxy naturally knows the destination’s IP address, we only need to provide a mapping of the IP addresses to relative host performance. Because of the static nature of the data, we started adding this information as part of the build-time configuration. This weight in itself is not perfect: different applications perform differently on the same hardware type. However, combined with the ALB’s dynamic part, this worked well–we did not need to add application-specific weights.
Testing
A big problem during the development was testing. While we had a limited staging environment, the new solution needed to work with many parameters: some callers or callees had three instances, some three thousand. Some backends were serving <1, and some > 1,000 RPS. Some services served a single homogenous procedure, and others hundreds, with latencies varying from low milliseconds to tens of seconds. Ultimately, we used a dummy service in production with a set of fake load generators configured to represent a heterogeneous load. We ran over 300 simulations before finding the right parameters and attempting to roll out to production services.
Results
We are happy with the final results–the exact numbers depend on the service and the hardware mix within each cluster. Still, on average, we reduced P99 CPU utilization by 12%, with some services seeing benefits of over 30%. The results were better the bigger the target service had per each backend–luckily, the largest services we cared about most were typically optimized enough. The same luck applied to onboarding–while Uber has over 4,000 microservices, onboarding the top 100 gave us the vast majority of potential reach.
Rollout and future changes
The rollout went well–we have not identified material bugs. The pick-2 load balancing and safe fallback were proven to be resilient. We onboarded services by tiers, region by region, trying to find representative types of services.
ALB was rolled out to hundreds of our biggest services with minimal hiccups or changes:
- Long-lived RPC Streams. A small category of services was mixing up a small number of long-lived RPC streams with many very short-lived requests. We rolled back the onboarding there.
- Slow-starting Runtimes. Around two years into the rollout, we tweaked the solution to handle slow-starting (Java) services better. These services could not serve the same request rate after startup due to JIT, but warm-up with recorded static requests was not working well enough; we needed to warm up the service with real requests at a lower rate. Here, we decided to seed each peer’s initial “weight” with a percentage of the average weight for the pool while leaving the algorithm’s core unchanged. We found this to work very well across a range of services, and we’re happy that this doesn’t require any static window settings, unlike Envoy’s slow start mode–the algorithm adjusts to a range of RPS automatically.
- Data Prefetching on Startup. Another very small category of services was pre-loading static data upon startup for several minutes. Due to the peculiarities of our service publishing mechanism, instances of those services are visible in our service discovery as “unhealthy.” The old algorithm strongly preferred the healthy instances. We changed that in ALB to avoid a thundering-herd-like scenario when a service cannot start after a temporary overload (due to each instance being instantly overloaded as they become healthy sequentially). The new algorithm significantly prefers healthy instances, but, in some cases, requests might be sent to “unhealthy” nodes. This doesn’t work for these services–while the reported error was <0.01% and 0.002%, we’re exploring changes similar to the panic threshold to make this disappear entirely.
- IP Address Mapping. The static mapping of IP address to server type worked well for 2+ years, but it will likely need to be adjusted as we move our workloads to the cloud.
Interestingly, two services overwrote the default load providers to emit custom load metrics based on background job processing. This proves that the defaults worked well for most services, but the solution was flexible enough to support other use cases.
Summary
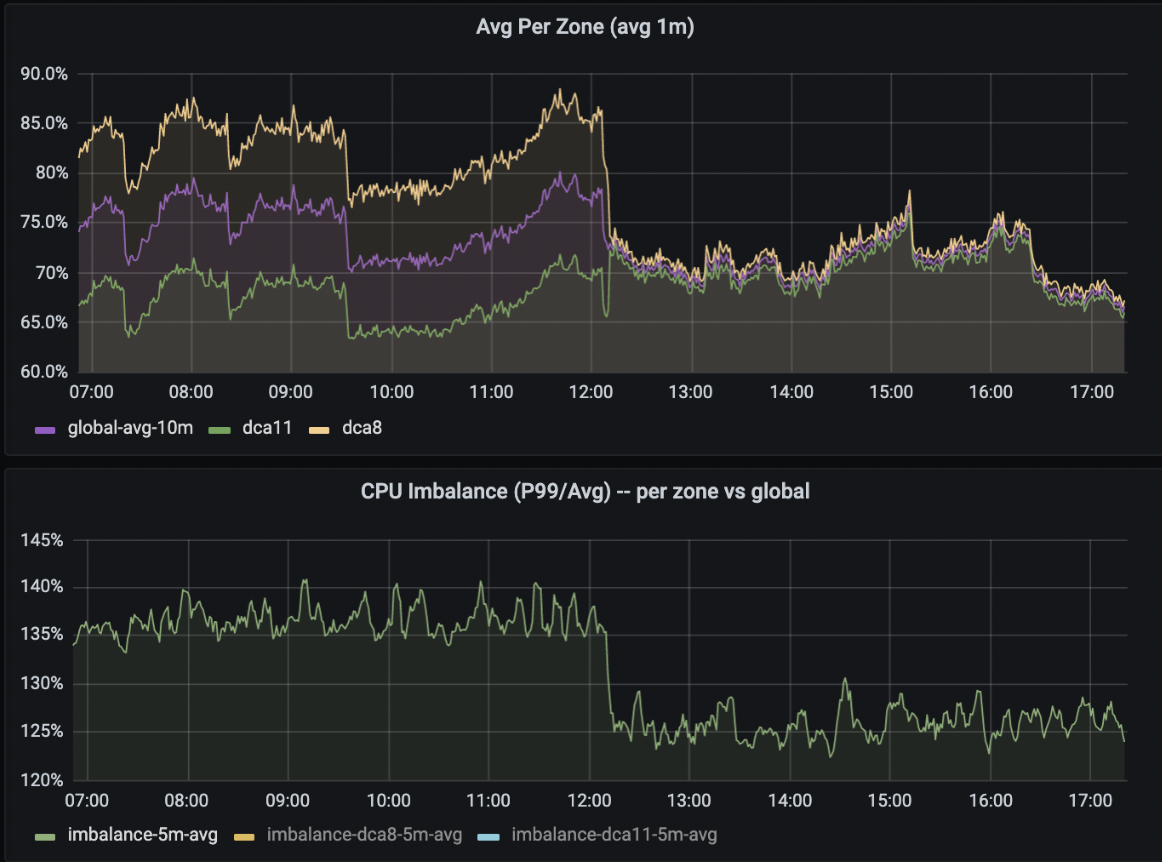
The project delivered very significant efficiency wins. We can run our containers at higher utilization levels, and load imbalance is no longer problematic for stateless workloads. The hardware configuration improvements resulted in double wins from reduced imbalance and pure compute capacity.
More interestingly, from the engineering blog perspective, the project also resulted in several learnings.
The primary one was the importance of data. The problem was real, but we started the project under the wrong assumptions. We didn’t know how to measure it; once we agreed, we lacked the tools to measure it effectively, especially over the long term. Even after that, we realized the underlying way we collect samples from the underlying infrastructure was flawed. At the same time, the data won arguments, helped us hone in on issues, and prioritized the work with other teams. Another data lesson was to set up the data infrastructure right for the long term–it helped during the project but also before. We were able to use an existing data warehouse as a base, and now afterward we periodically get questions about the load imbalance. A link to the dashboard usually answers all the questions.
The second lesson was to add workarounds in the right place of the stack to get the data we needed. Building proper real-time observability would have taken us months or quarters. Still, we quickly got the right conclusions with a targeted hack and selectively basing the observations on a sample of services. Related to that was the willingness to do a lot of manual grunt work: to build the understanding, we spent weeks staring at dashboards and verifying assumptions before we started coding. Later, when implementing ALB and Zone/Cluster weights, we started with relatively small changes, verified assumptions, and iterated to the next version.
The third, arguably less generalizable lesson, was to trust in the platforms. We made a bet that our microservices would migrate to the common frameworks. Similarly, when implementing, we built on top of years of pre-existing investments in the platform–pre-existing tooling (dashboards, debug tooling, operational knowledge, rollout policies) was there, and we could roll out major changes reasonably quickly and safely. We built with the grain of the platform and avoided major rewrites that could have derailed the project.
Acknowledgments
There were many people involved in the project. We thank Avinash Palayadi, Prashant Varanasi, Zheng Shao, Hiren Panchasara, and Ankit Srivastava for their general contributions. Jeff Bean, Sahil Rihan, Vikrant Soman, Jon Nathan, and Vaidas Zlotkus for hardware help, Vytenis Darulis for observability fixes, Jia Zhan and Eric Chung for ALB reviews, Nisha Khater for per-instance-stats project, Allen Lu for rolling out yarpc globally.
Logo attribution: “Scales of Justice – The Law – Lawyers and Attorneys” by weiss_paarz_photos is licensed under CC BY-SA 2.0.

Pawel Krolikowski
Pawel Krolikowski is a Staff Software Engineer on the Software Networking team. Before working on load balancing, he spent most of his time on the Software Networking management plane and integrations with stateful and stateless orchestration systems.

Chien-Chih Liao
Chien-Chih Liao is a Senior Staff Software Engineer on Uber’s Software Networking team. His contributions include traffic control, traffic load balancing, data center failover, and resilience features for Uber’s service mesh.

Ying Jiang
Ying Jiang is the Manager of our Network Lifecycle Team. Before she shifted her path to become a manager, she worked on various projects, including imagebuilder of Crane infra stack, making Uber portable, Canary, and traffic load balancing.
Posted by Pawel Krolikowski, Chien-Chih Liao, Ying Jiang
Related articles



Most popular

A beginner’s guide to Uber vouchers for riders

Automating Efficiency of Go programs with Profile-Guided Optimizations

Enhancing Personalized CRM Communication with Contextual Bandit Strategies
