
Introduction
The Machine Learning (ML) team at Uber is consistently developing new and innovative components to strengthen our ML Platform (Michelangelo).
In machine learning, features are the data used to make model calculations and predict an outcome. You can think of them as the input to the learning model or attributes in your data that are relevant to the predictive modeling problem.
When querying Uber’s data stores for feature data, it can be hard to:
- Figure out good Uber-specific features
- Build pipelines to generate features
- Compute features in real time
- Guarantee that data used at training is the same as the data used for scoring predictions
- Monitor features
The Uber Michelangelo feature store, called Palette, is a database of Uber-specific curated and internally crowd-sourced features that are easy to use in machine learning projects. It comes to solve all the above-mentioned challenges. Pipelines are auto-generated for feature generations and feature dispersals. Palette supports various feature computation use cases, like batch and near real time, and includes precomputed features related to cities, drivers, and riders, as well as custom features generated for the EATs, Fraud, and Comms teams. Subject to our normal data access restrictions, Uber users are able to use many of the pruned features maintained by other Uber teams or even create their own and can directly incorporate these features in their machine learning models.

Palette Metastore Background
Palette provides feature management infrastructure including feature discovery, creation, deprecation, offline and online serving setup in its Metastore.
Palette Metastore is a metadata store of features where users of Palette can create, deprecate, add details about ownership/backfill/scheduling of feature generation pipelines, offline training and HDFS location. Users can specify Cassandra databases that they want to copy data for online serving along with Spark configuration, join keys, feature list along with feature metadata. Users can also include info about which features should be copied for online serving, SQL queries for generating the features from upstream dependencies and maintaining audit of changes.

A Closer Look: Problem and Motivation
A major incident occurred in 2021 due to inadequate schema validation on Palette Metadata where a bad Metadata change was pushed, which resulted in OnlineServing breaking for major Tier1 use cases, since it was unable to load Palette Metadata during boot up.
Schema validation logic used to be client side and lived in a script within the FeatureSpec repository, which is the Metadata repository for Palette customers to make metadata-related changes. Updating validation was challenging, as customer metadata updates wouldn’t pick up the latest validation always, as they didn’t rebase against the latest code changes. This led to incorrect metadata being merged into the master repository.
Metadata discrepancies caused build failures for customers rebasing against master due to incorrect metadata changes being merged into master.
Incident resolution took several hours due to several issues.
- Updating Palette Metadata in OnlineServing stack. Changing a single feature group in Palette Metadata repository led to updates for all hundreds of feature groups due to lack of an incremental update system, prolonging rollbacks.
- Lack of schema validation. The Feature Engine on-call had to dedicate substantial time to each customer diff. Majority of on-call time was spent on assisting with metadata changes in the FeatureSpec repo. Lack of a build job to verify actual Hive table schema before merging led to failures at training time. Customers made errors when creating Palette tables, missing required columns.
- Offline Metadata updates. Metadata updates took over an hour after landing changes in FeatureSpec repo since entire metadata repository was getting updated even if only a minor change was made for one of the feature groups.
These issues highlight the challenges stemming from inadequate schema validation, leading to data loss, helpdesk burden, build failures, and confusion in pipeline updates. The complex process of updating metadata and the lack of automated schema verification further compounded the problems faced by the team.
Deep Dive: Meta Store
Feature Store Object Model

Following are the new objects that we formally define in the new Palette Metadata system backed by protos:
FeatureGroup: A logical table with a collection of features for both streaming and batch features backed by daily feature snapshots in Hive tables or Cassandra for the online store.
Feature: A single feature corresponding to a column within the logical FeatureGroup (table).
Dataset: Dataset represents the metadata needed to create a table in a database/storage for a given feature group. For example, keyspace, partition key and cluster key would be the metadata needed to create a table for a given C* cluster. These would be part of the Dataset spec.
Storage: Storage is the underlying storage technology that is referred by dataset, online feature serving group.
FeatureServingGroup: A logical unit of serving in the online store that guarantees a certain SLA (throughput, latency). It is a collection of Storage (Cassandra/Redis clusters) that back the Feature Groups, and a routing map of FeatureGroups to the underlying Datasets. Note that it is common in the case of very large use cases) for FeatureServingGroup to contain multiple Cassandra clusters.
Inference Server/Palette Service: Inference Server is the logical object holding metadata for Inference Serving for a given model within a Michelangelo project. Palette Service (a service where users can just fetch feature values without needing a model setup) similarly will hold metadata for serving via Palette Service.
Metadata Organization
We broke the setup of Metadata inside Palette Metadata repository where following files are setup to simplify customer interaction and Michelangelo on-call interaction with the metadata where customers manage offline related metadata files and Michelangelo on-calls manage online serving related metadata files.
Description.json: This file contains all the metadata related to offline serving as well as ownership and alerting setup backed by OfflineSpec defined above
Features.json: This file will cover metadata related to features with schema backed by Feature CRD
OnlineServing.json: This file contains all the metadata related to online serving
HQL: This file contains Hive Queries for generating features
Metadata Registration
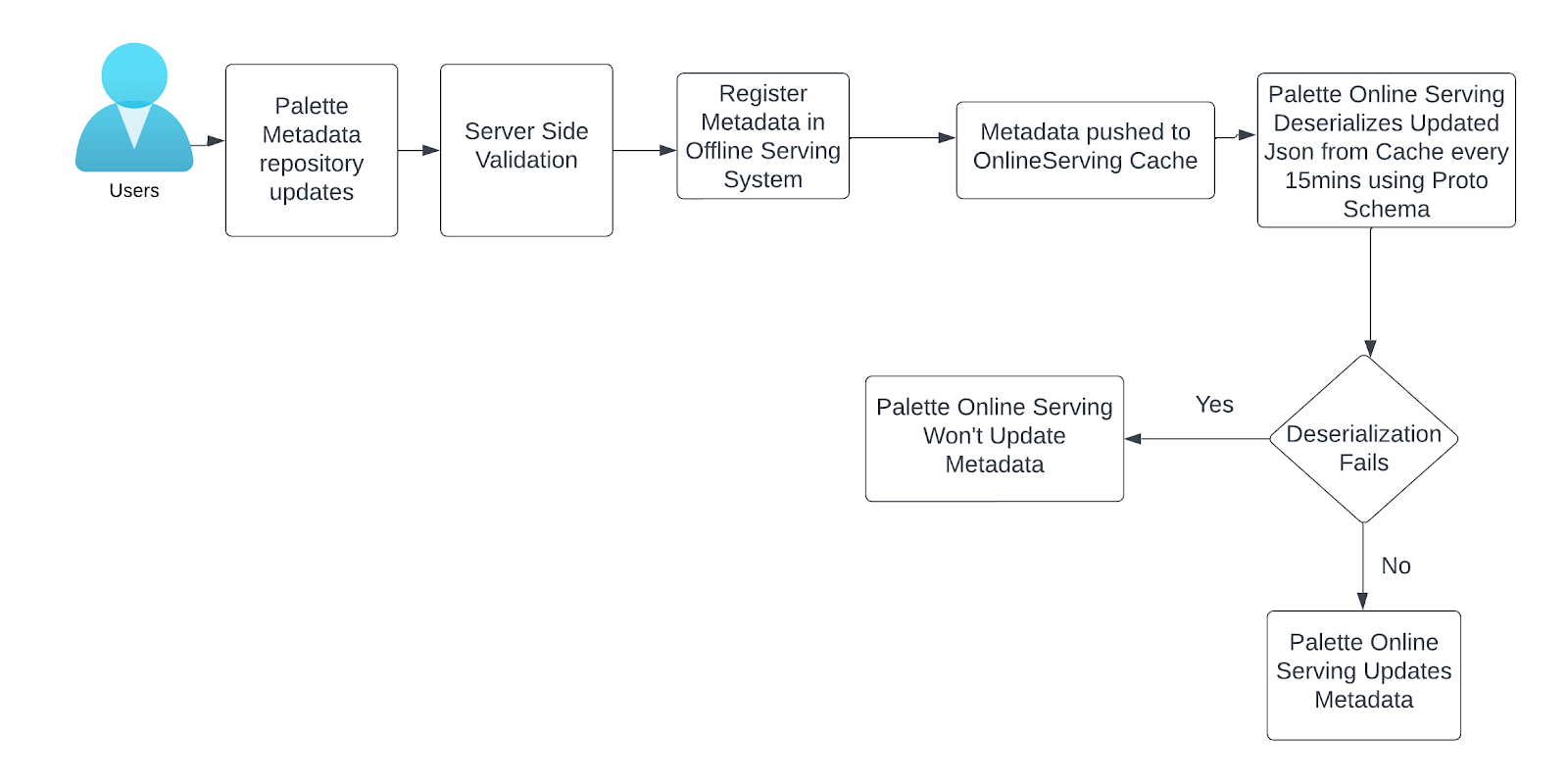
To expedite Offline and Online Metadata updates, we moved the system handling Palette Metadata updates made by customers to incrementally compute the delta of the updates, and register those updates in the OfflineServing system.
Once the updates land in UAPI, we use Kubernetes based Controller to process those updates to our highly available cache Online Serving Cache called ObjectConfig.
The E2E updates to Offlline and Online systems takes only 15 minutes now instead of over an hour previously, since only incremental updates are pushed and not the entire metadata repository.
Online Serving Re-Architecture

Metadata Unification
In the old architecture, the metadata for online serving was fragmented across various services. We decided to consolidate all the metadata for online serving in one place, which is the Palette Metadata repository.
Interface Redesign
We made an interface change to deprecate the old schema which no longer was meeting the evolving needs of the Palette online system.
Metadata Wrapper
We introduced a wrapper during migration for 2 main purposes: Interface adaptation and quick rollback. During the migration process, we made both versions of metadata available for Palette Online Serving. That gave us the ability to compare the metadata in memory. Because the meta loader will transform the metadata to a format better suited serving needs, the metadata in memory is different from what we see in the metadata service. Comparing the metadata in memory gave us more confidence for a safe migration. But due to the interface redesign, we needed serving logic to support both interfaces. So the wrapper was the one to translate the legacy metadata into the format of the new interface. We also introduced a kill switch to tell the wrapper which version of the metadata it should provide to the serving logic. Then we can do a quick rollback when any metadata issue happens during migration.
Migration Challenges
- Keep a smooth user experience during migration:
- We maintained scripts to automatically synchronize feature metadata between old and new systems. This could avoid data gaps when switching to the new system.
- Good and clean documentation was provided to help users to learn how to onboard features to the new Metadata Store.
- Track correctness for migration:
- Comparison metrics and logs were created across Feature Generation pipeline system, offline serving system to clearly articulate the differences between old and new systems. They played as a proof of evidence regarding correctness for migration.
- Traffic metrics were checked to make sure that no traffic comes through old systems after full migration.
- Ensuring Backward Compatibility:
- The updated metadata introduced substantial changes in data formats and APIs. To maintain backward compatibility, it was essential to create a robust common API wrapper. This wrapper could seamlessly bridge the gap between legacy code and the new codebase. Subsequently, we could transition the underlying implementations of the Common API wrapper gradually, facilitating a seamless migration process.
- Testing:
- The code modification incorporated itself into the Michelangelo team’s offline training, re-training, evaluation and prediction workflow. To guarantee the continued functionality of these integrations after the migration, it was imperative to conduct comprehensive integration testing involving all existing systems.
- Rollback Plan:
- In case the migration encounters unexpected issues or doesn’t yield the desired results, we also defined a thorough rollback plan which could minimize downtime and mitigate risks.
Result
The result of the Metadata migration was that Palette Onboarding Deployment time has reduced drastically by more than 95%. In addition, time to migrate Cassandra clusters has gone down by 90% since all online serving configuration is so cleanly organized which means on-calls no longer need to scramble to figure out which feature group gets served in which Cassandra. Due to the re-architecture of the offline metadata update system so that updates are processed incrementally, time for offline metadata updates has gone from hours to minutes. Additionally, we have introduced enhanced server validation for FeatureStore CRDs and cross-CRD validation
Conclusion
Overall, introduction of formal schema, consolidation of metadata, enhanced validation, and a very diligently planned migration have led to our new metadata system being easy to use for customers and Michelangelo on-calls, reducing deployment and customer onboarding time, as well as maintenance and operational costs.
Acknowledgements
This major step for Machine Learning at Uber could not have been done without the many teams who contributed to it. Huge thank you to the Feature Engine group within Uber’s Michelangelo Team, who spent 1+ year rearchitecting the Meta Store system.
We also want to give a special thank you to our partners on the Michelangelo teams for making this idea a reality, as well as our former colleagues who helped initiate this idea.
Header Image Attribution: The “Journey start here” image is covered by a CC BY 2.0 license and is credited to Johnragai-Moment Catcher. No changes have been made to the image.

Paarth Chothani
Paarth Chothani is a Staff Software Engineer on the Uber AI Gen AI team in the San Francisco Bay area. He specializes in building distributed systems at scale. Previously worked on building large-scale systems.

Nicholas Marcott
Nicholas Brett Marcott is a Staff Software Engineer, TLM on the Uber AI Feature Store team in the San Francisco Bay area. He specializes in serving data for ML models at high scale.

Dehua Lai
Dehua Lai is a Senior Software Engineer on Uber AI's Feature Store team based in Seattle. His primary focus is on building ML Platforms on large-scale distributed systems.

Xiyuan Feng
Xiyuan is a Software Engineer on the Uber AI Platform Feature Store team based in Sunnyvale.

Chunhao Zhang
Chunhao Zhang is a Senior Software Engineer at Uber AI’s Feature Store tead based in Sunnyvale. He specializes in building large scale distributed systems. Previous work on Google search indexing and display ads serving.

Victoria Wu
Victoria Wu is a Senior Software Engineer on the Uber AI’s Feature Store team based in the San Francisco Bay Area. She specializes in building large-scale distributed systems. Previously worked on building Kafka infrastructure at PayPal.
Posted by Paarth Chothani, Nicholas Marcott, Dehua Lai, Xiyuan Feng, Chunhao Zhang, Victoria Wu
Related articles



Most popular

Case study: how the University of Kentucky transformed Wildcab with Uber

How Uber Eats fuels the University of Miami Hurricanes off the field

How Uber Uses Ray® to Optimize the Rides Business

MySQL At Uber
Products
Company