Modernizing Uber’s Batch Data Infrastructure with Google Cloud Platform
2 May 2024 / Global
Introduction
Uber runs one of the largest Hadoop installations in the world. Our Hadoop ecosystem hosts more than 1 exabyte of data across tens of thousands of servers in each of our two regions. The open source data ecosystem, including the Hadoop ecosystem discussed in previous engineering blogs, has been the core of our data platform.
Over the past few months, we have been assessing our platform and infrastructure needs to make sure we are well positioned to modernize our big data infrastructure to keep up with the growing needs of Uber.
Today, we are excited to announce that we are working with Google Cloud Platform (GCP) to move our batch data analytics and ML training stack to GCP.
Uber Data Platform’s mission is to democratize data-driven business decisions through intuitive, reliable, and efficient data products. Modernizing with GCP will enable big gains in user productivity, engineering velocity, improved cost efficiency, access to new innovation, and expanded data governance.
Strategy
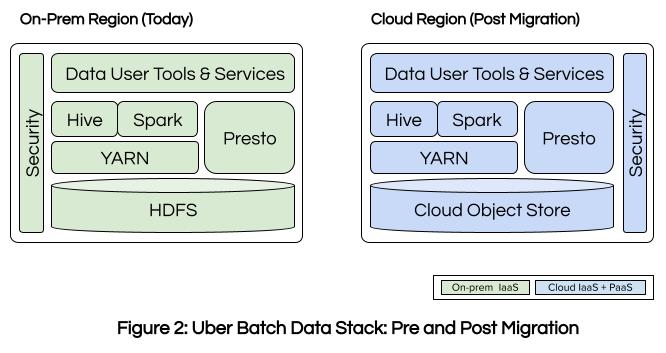
Our strategy for the initial migration to GCP is to leverage cloud’s object store for the data lake storage while migrating the rest of the data stack to cloud IaaS (Infrastructure as a Service). This approach facilitates a fast migration path with minimum disruption to existing jobs and pipelines as we can replicate the exact versions of our on-prem software stack, engines, and security model on IaaS. We plan to adopt applicable PaaS (Platform as a Service) offerings, for example GCP Dataproc or BigQuery, after the initial migration to GCP to take full advantage of the elasticity and performance benefits cloud native services provide. Our plan is to execute on this strategy over the next several quarters, documenting our progress and sharing our learnings through a series of blog posts, of which this is the first. So bookmark this blog and stay tuned!
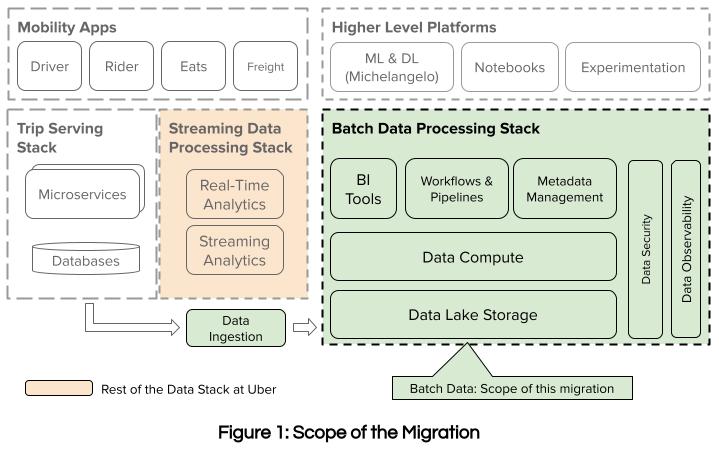
Migration Principles
Here are the core principles that we are keeping in mind for this daunting migration:
Avoid painful migrations for data users
By moving the majority of the batch data stack onto cloud IaaS as-is, we expect to shield our users such as dashboard owners, pipelines authors, ML practitioners, etc., from needing any changes to their artifacts or services. We’ll leverage well-known abstractions and open standards to make the migration as transparent as possible to data users.
We will be relying heavily on a cloud storage connector that implements the Hadoop FileSystem interface to Google Cloud Storage, providing HDFS compatibility. We will leverage open standards such as Apache Parquet™ file format, Apache Hudi™ table format, Apache Spark™, Presto’s SQL dialect, Apache Hadoop YARN™, and K8s to minimize the migration challenges even for the teams within the data platform organization. We will standardize our Apache Hadoop HDFS™ clients to abstract the on-prem HDFS implementation specifics. Therefore, all the services that access HDFS on-prem today will seamlessly integrate with the GCP-hosted object store based storage layer without any changes. The standardized HDFS client will be modified to translate the HDFS paths to Object store based paths via a “Path Translation Service.” We will share more details on this in a future blog post.
Enhance data access proxies to federate traffic across on-prem or cloud
We have developed data access proxies (for Presto, Spark, and Hive) that abstract out the details of the underlying physical compute clusters. During the testing phase, these proxies will support selectively routing test traffic toward the corresponding cloud-based Presto or YARN (for Spark and Hive) clusters. During full migration, all queries or jobs submitted to these proxies will be routed to the cloud-based stack.
Leverage Uber’s existing cloud-agnostic container and deployment infrastructure
The batch data stack sits on top of Uber’s infrastructure building blocks such as Uber’s container environment, compute platform, and deployment tools which are built to be agnostic between cloud and on-prem. These platforms easily allow us to expand the batch data ecosystem microservices onto the cloud IaaS.
Forecast potential data governance issues from cloud services
As a platform team we will build and enhance existing data management services to only support selected and approved data services from the cloud vendor’s portfolio to avoid data governance complexities moving forward.
Major Workstreams
Bucket mapping and cloud resources layout
While migrating data, we need to map HDFS files and directories from the source cluster to cloud objects, which reside in one or more buckets. We also need to apply IAM policies at varying levels of granularity such as bucket, prefix or object level. Common constraints on buckets and objects include number of buckets per organization, read/write throughput from/to a bucket, IOPS throttling, and the number of ACLs, which can be applied via bucket policies.
The goal of this workstream is to formulate a mapping algorithm that satisfies these constraints and creates the corresponding cloud buckets. We also plan to incorporate data mesh principles to organize these data resources in an organization-centric hierarchical manner, allowing for better data administration and management.
Security integration
Our existing, Kerberos-based tokens and Hadoop Delegation tokens will not directly work with cloud PaaS, specifically GCS object storage. Cloud providers generally don’t have a ready-to-use PaaS solution for such interoperability.
The goal of this workstream is to enable a seamless support for all users, groups, and service accounts to continue to be authenticated against the object store data lake and any other cloud PaaS. Also to maintain the same levels of authorized access as on-prem from there on.
Data replication
HiveSync is a permissions-aware, bi-directional data replication service built at Uber (based on ReAir/distcp). HiveSync allows us to operate in an active-active mode with the batch and incremental replication features keeping our data lakes in the two regions in sync.
The goal of this workstream is to extend HiveSync’s capabilities and Hudi library capabilities to replicate the on-prem data lake’s data into the cloud-based data lake and corresponding Hive Metastore. This includes the one time bootstrap (bulk migration) and then ongoing incremental updates till the cloud-based stack is the primary.
YARN and Presto clusters
We would provision new YARN and Presto clusters on IaaS from the GCP. The existing data access proxies which federate query and job traffic to these clusters will then route traffic to the cloud-based stack through the migration.
Challenges and Initiatives
This migration is a formidable undertaking and we are aware of the typical challenges that we
might face. Here are some of the large categories of challenges we are anticipating along with the mitigations and initiatives to handle them:
- Performance: There are several well-known differences in features and performance characteristics between Object Store and HDFS. (e.g., atomic renames, file listing performance, etc.). We would leverage the Hadoop connectors from open source and help evolve them to maximize performance.
- Usage governance: Cloud-related usage costs can balloon out of control if we don’t effectively and proactively manage them. We would leverage cloud’s elasticity to offset these costs. We will also partner with our internal capacity engineering team to build a finer attribution mechanism and tracking.
- Non-analytics/ML specific usage of HDFS by applications: Over the years, teams have also started to use HDFS as a generic file store. We would be proactively migrating these use cases to other internal blob stores while also providing a transparent migration path to avoid disruptions.
- Unknown unknowns: Finally, with a ~7 year old on-prem stack, we will definitely face unanticipated challenges. We hope to proactively uncover issues with early end-to-end integrations, refine proposed abstractions with customers, deprecate legacy use cases aggressively rather than carry them forward, etc., to stay ahead of these challenges.
Stay tuned on our journey as we will share our detailed designs, execution progress, and the lessons learned along the way!
Apache®, Apache Parquet™, Apache Hudi™, Apache Spark™, Apache Hadoop YARN™ are registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Cover Photo Attribution: “Country road and yellow field” by Infomastern is licensed under CC BY-SA 2.0.

Abhi Khune
Abhi Khune is a Principal Engineer on Uber’s Data Platform team. For the past 6 months, Abhi has been leading the technical strategy to modernize Uber’s Data Platform to a Cloud-based architecture.

Arun Mahadeva Iyer
Arun Mahadeva Iyer is a Sr. Staff Engineer in the Uber’s Data Platform team. He is currently working on re-architecting Uber's Data Platform on the Cloud.

Sahana Bhat
Sahana Bhat is a Sr. Software Engineer in the Uber’s Data Platform team in Bangalore. She has worked on building the DataMesh service and is currently driving the migration of batch data workloads to Cloud.

Matt Mathew
Matt is a Sr. Staff Engineer on the Engineering Security team at Uber. He currently works on various projects in the security domain. Previously, he led the initiative to containerize and automate Data infrastructure at Uber.
Posted by Abhi Khune, Arun Mahadeva Iyer, Sahana Bhat, Matt Mathew
Related articles



Most popular

Introducing the Prompt Engineering Toolkit

Serving Millions of Apache Pinot™ Queries with Neutrino

Your guide to NJ TRANSIT’s Access Link Riders’ Choice Pilot 2.0

Moving STRIPES: innovating student transportation at Mizzou
Products
Company