
Uber has adopted Golang (Go for short) as a primary programming language for developing microservices. Our Go monorepo consists of about 50 million lines of code (and growing) and contains approximately 2,100 unique Go services (and growing).
Go makes concurrency a first-class citizen; prefixing function calls with the go keyword runs the call asynchronously. These asynchronous function calls in Go are called goroutines. Developers hide latency (e.g., IO or RPC calls to other services) by creating goroutines. Two or more goroutines can communicate data either via message passing (channels) or shared memory. Shared memory happens to be the most commonly used means of data communication in Go.
Goroutines are considered “lightweight” and since they are easy to create, Go programmers use goroutines liberally. As a result, we notice that programs written in Go, typically, expose significantly more concurrency than programs written in other languages. For example, by scanning hundreds of thousands of microservice instances running our data centers, we found out that Go microservices expose ~8x more concurrency compared to Java microservices. Higher concurrency also means potential for more concurrency bugs. A data race is a concurrency bug that occurs when two or more goroutines access the same datum, at least one of them is a write, and there is no ordering between them. Data races are insidious bugs and must be avoided at all costs.
We developed a system to detect data races at Uber using a dynamic data race detection technique. This system, over a period of six months, detected about 2,000 data races in our Go code base, of which our developers already fixed ~1,100 data races.
In this blog, we will show various data race patterns we found in our Go programs. This study was conducted by analyzing over 1,100 data races fixed by 210 unique developers over a six-month period. Overall, we noticed that Go makes it easier to introduce data races, due to certain language design choices. There is a complicated interplay between the language features and data races.
Data Race Patterns in Go
We investigated each of the ~1,100 data races fixed by our developers and bucketed them into different categories. Our study of these data races showed some common patterns and some arcane reasons that cause data races in Go:
1. Go’s design choice to transparently capture free variables by reference in goroutines is a recipe for data races
Nested functions (a.k.a., closures), in Go transparently capture all free variables by reference. The programmer does not explicitly specify which free variables are captured in the closure syntax.
This mode of usage is different from Java and C++. Java lambdas only capture by value and they consciously took that design choice to avoid concurrency bugs [1, 2]. C++ requires developers to explicitly specify capture by value or by reference.
Developers are quite often unaware that a variable used inside a closure is a free variable and captured by reference, especially when the closure is large. More often than not, Go developers use closures as goroutines. As a result of capture-by-reference and goroutine concurrency, Go programs end up potentially having unordered accesses to free variables unless explicit synchronization is performed. We demonstrate this with the following three examples:
Example 1: Data race due to loop index variable capture
The code in Figure 1A shows iterating over a Go slice jobs and processing each element job via the ProcessJob function.

Here, the developer wraps the expensive ProcessJob in an anonymous goroutine that is launched once per item. However, the loop index variable job is captured by reference inside the goroutine. When the goroutine launched for the first loop iteration is accessing the job variable, the for loop in the parent goroutine will be advancing through the slice and updating the same loop-index variable job to point to the second element in the slice, causing a data race. This type of data race happens for value and reference types; slices, array, and maps; and read-only and write accesses in the loop body. Go recommends a coding idiom to hide and privatize the loop index variable in the loop body, which is not always followed by developers, unfortunately.
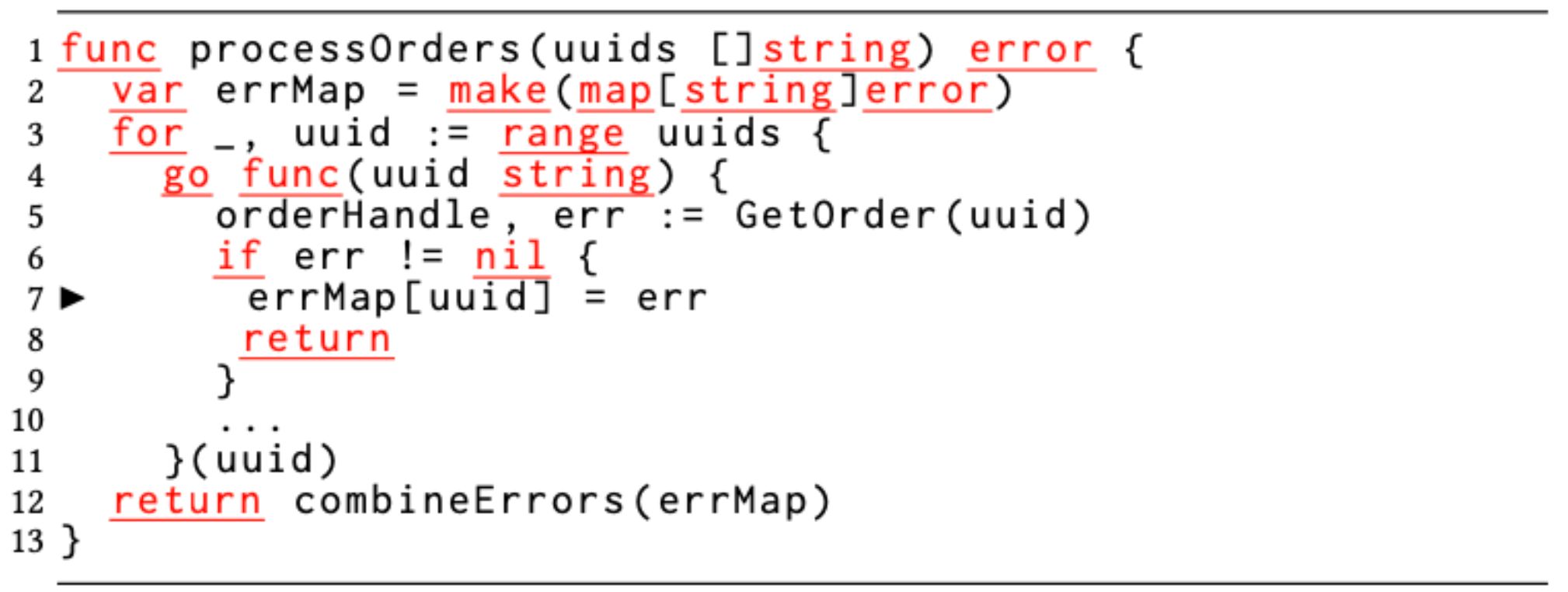
Example 2: Data race due to idiomatic err variable capture.

Go advocates multiple return values from functions. It is common to return the actual return value(s) and an error object to indicate if there was an error as shown in Figure 1B. The actual return value is considered to be meaningful if and only if the error value is nil. It is a common practice to assign the returned error object to a variable named err followed by checking for its nilness. However, since multiple error-returning functions can be called inside a function body, there will be several assignments to the err variable followed by the nilness check each time. When developers mix this idiom with a goroutine, the err variable gets captured by reference in the closure. As a result, the accesses (both read and write) to err in the goroutine run concurrently with subsequent reads and writes to the same err variable in the enclosing function (or multiple instances of the goroutine), which causes a data race.
Example 3: Data race due to named return variable capture.
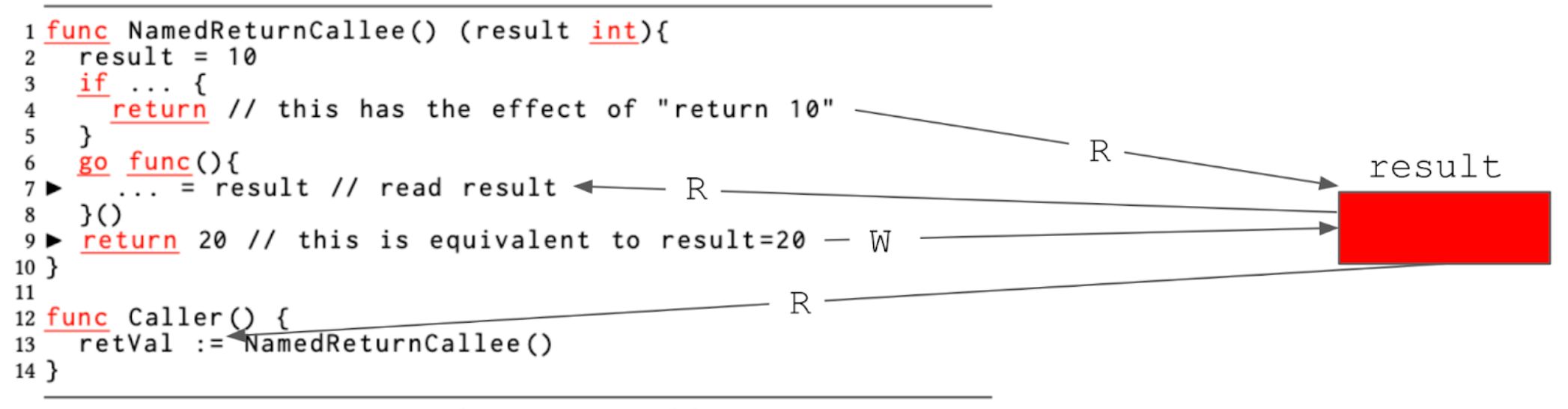
Go introduces a syntactic sugar called named return values. The named return variables are treated as variables defined at the top of the function, whose scope outlives the body of the function. A return statement without arguments, known as a “naked” return, returns the named return values. In the presence of a closure, mixing normal (non-naked) returns with named returns or using a deferred return in a function with a named return is risky, as it can introduce a data race.
The function NamedReturnCallee in Figure 1C returns an integer, and the return variable is named as result. The rest of the function body can read and write to result without having to declare it because of this syntax. If the function returns at line 4, which is a naked return, as a result of the assignment result=10 on line 2, the caller at line 13 would see the return value of 10. The compiler arranges for copying result to retVal. A named return function can also use the standard return syntax, as shown on line 9. This syntax makes the compiler copy the return value, 20, in the return statement to be assigned to the named return variable result. Line 6 creates a goroutine, which captures the named return variable result. In setting up this goroutine, even a concurrency expert might believe that the read from result on line 7 is safe because there is no other write to the same variable; the statement return 20 on line 9 is, after all, a constant return, and does not seem to touch the named return variable, result. The code generation, however, turns the return 20 statement into a write to result, as previously mentioned. Now we suddenly have a concurrent read and a write to the shared result variable, a case of a data race.
2. Slices are confusing types that create subtle and hard-to-diagnose data races
Slices are dynamic arrays and reference types. Internally, a slice contains a pointer to the underlying array, its current length, and the maximum capacity to which the underlying array can expand. For ease of discussion, we refer to these variables as meta fields of a slice. A common operation on a slice is to grow it via the append operation. When the size reaches the capacity, a new allocation (e.g., double the current size) is made, and the meta fields are updated. When a slice is concurrently accessed by goroutines, it is natural to protect accesses to it by a mutex.

In Figure 2, the developer thinks that lock-protecting the slice append on line 6 is sufficient to protect from data race. However, a data race happens when a slice is passed as an argument to the goroutine on line 14, which is not lock-protected. The invocation of the goroutine causes the meta fields of the slice to be copied from the call site (line 14) to the callee (line 11). Given that a slice is a reference type, the developer assumed its passing (copying) to a callee caused a data race. However, a slice is not the same as a pointer type (the meta fields are copied by value) and hence the subtle data race.
3. Concurrent accesses to Go’s built-in, thread-unsafe maps cause frequent data races
Hash table (map) is a built-in language feature in Go and is not thread-safe. If multiple goroutines simultaneously access the same hash table with at least one of them trying to modify the hash table (insert or delete an item), data race ensues. We observe that developers make a fundamental, but common assumption (and a mistake) that the different entries in the hash table can be concurrently accessed. This assumption stems from developers viewing the table[key] syntax used for map accesses and misinterpreting them to be accessing disjoint elements. However, a map (hash table), unlike an array or a slice, is a sparse data structure, and accessing one element might result in accessing another element; if during the same process another insertion/deletion happens, it will modify the sparse data structure and cause a data race. We even found more complex concurrent map access data races resulting from the same hash table being passed to deep call paths and developers losing track of the fact that these call paths mutate the hash table via asynchronous goroutines. Figure 3 shows an example of this type of data race.
While hashtable leading to data races is not unique to Go, the following reasons make it more prone to data races in Go:
- Go developers use maps more frequently than the developers in other languages because the map is a built-in language construct. For example, in our Java repository, we found 4,389 map constructs per MLoC, whereas the same for Go is 5,950 per MLoC, which is 1.34x higher.
- The hash table access syntax is just like array-access syntax (unlike Java’s get/put APIs), making it easy to use and hence accidentally confused for a random access data structure. In Go, a non-existing map element can easily be queried with the table[key] syntax, which simply returns the default value without producing any error. This error tolerance makes developers complacent when using Go map.
4. Go developers often err on the side of pass-by-value (or methods over values), which can cause non-trivial data races
Pass-by-value semantics are recommended in Go because it simplifies escape analysis and gives variables a better chance to be allocated on the stack, which reduces pressure on the garbage collector.
Unlike Java, where all objects are reference types, in Go, an object can be a value type (struct) or a reference type (interface). There is no syntactic difference, and this leads to incorrect use of synchronization constructs such as sync.Mutex and sync.RWMutex, which are value types (structures) in Go. If a function creates a mutex structure and passes by value to multiple goroutine invocations, those concurrent executions of the goroutines operate on distinct mutex objects, which share no internal state. This defeats mutually exclusive access to the shared memory region that is guarded, exemplified in Figure 4 below.

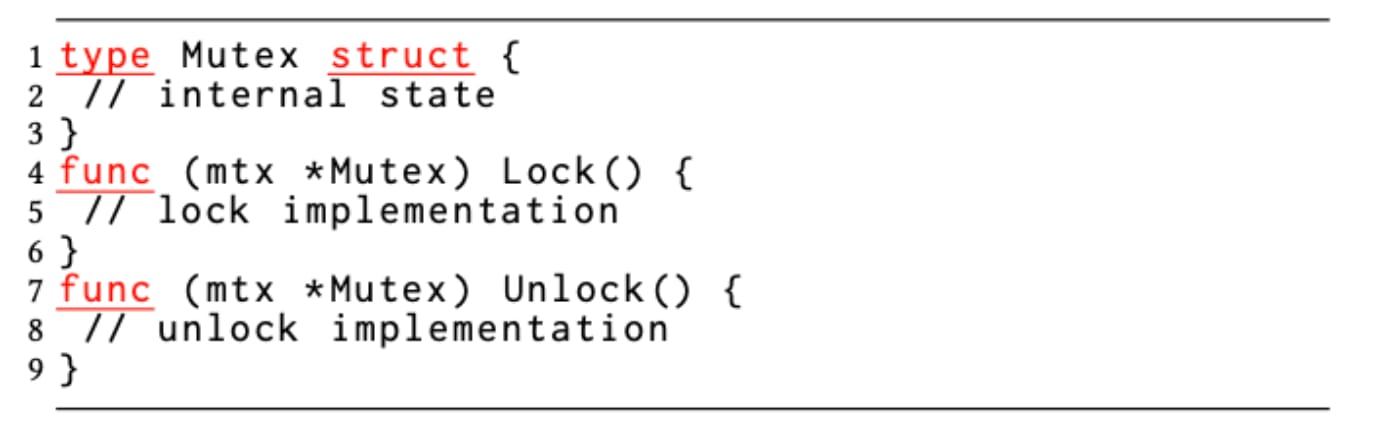
Since Go syntax is the same for invoking a method over pointers vs. values, less attention is given by the developer to the question that m.Lock() is working on a copy of mutex instead of a pointer. The caller can still invoke these APIs on a mutex value, and the compiler transparently arranges to pass the address of the value. Had this transparency not been there, the bug could have been detected as a compiler type-mismatch error.
A converse of this situation happens when developers accidentally implement a method where the receiver is a pointer to the structure instead of a value/copy of the structure. In these situations, multiple goroutines invoking the method end up accidentally sharing the same internal state of the structure, whereas the developer intended otherwise. Here, also, the caller is unaware that the value type was transparently converted to a pointer type at the receiver.
5. Mixed use of message passing (channels) and shared memory makes code complex and susceptible to data races

Figure 5 shows an example of a generic future implementation by a developer using a channel for signaling and waiting. The future can be started by calling the Start() method, and one can block for the future’s completion by calling the Wait() method on the Future. The Start()method creates a goroutine, which executes a function registered with the Future and records its return values (response and err). The goroutine signals the completion of the future to the Wait() method by sending a message on the channel ch as shown on line 6. Symmetrically, the Wait() method blocks to fetch the message from the channel (line 11).
Contexts in Go carry deadlines, cancelation signals, and other request-scoped values across API boundaries and between processes. This is a common pattern in microservices where timelines are set for tasks. Hence, Wait() blocks either on the context being canceled (line 13) or the future to have completed (line 11). Furthermore, the Wait() is wrapped inside a select statement (line 10), which blocks until at least one of the select arms is ready.
If the context times out, the corresponding case records the err field of Future as ErrCancelled on line 14. This write to err races with the write to the same variable in the future on line 5.
6. Go offers more leeway in its group synchronization construct sync.WaitGroup, but the incorrect placement of Add/Done methods leads to data races

The sync.WaitGroup structure is a group synchronization construct in Go. Unlike C++ barrier, pthreads, or Java barrier or latch constructs, the number of participants in a WaitGroup is not determined at the time of construction but is updated dynamically. Three operations are allowed on a WaitGroup object — Add(int), Done(), and Wait(). Add()increments the count of participants, and the Wait() blocks until Done() is called count number of times (typically once by each participant). WaitGroup is extensively used in Go. As shown previously in Table 1, group synchronization is 1.9x higher in Go than in Java.
In Figure 6, the developer intends to create as many goroutines as the number of elements in the slice itemIds and process the items concurrently. Each goroutine records its success or failure status in results slice at different indices and the parent function blocks at line 12 until all goroutines finish. It then accesses all elements of results serially to count the number of successful processings.
For this code to work correctly, when Wait() is invoked on line 12, the number of registered participants must be already equal to the length of itemIds. This is possible only if wg.Add(1)is executed as many times as the length of itemIds prior to invoking wg.Wait(), which means wg.Add(1)should have been placed on line 5, prior to each goroutine invocation. However, the developer incorrectly places wg.Add(1)inside the body of the goroutines on line 7, which is not guaranteed to have been executed by the time the outer function WaitGrpExample invokes Wait(). As a result, there can be fewer than the length of itemIds registered with the WaitGroup when the Wait()is invoked. For that reason, the Wait()can unblock prematurely, and the WaitGrpExample function can start to read from the slice results (line 13) while some goroutines are concurrently writing to the same slice.
We also found data races arising from a premature placement of the wg.Done()call on a Waitgroup. A subtle version of premature wg.Done()is shown below in Figure B, which results from its interaction with Go’s defer statement. When multiple defer statements are encountered, they are executed in the last-in-first-out order. Here, wg.Wait()on line 9 finishes before the doCleanup()runs. The parent goroutine accesses the locationErr on line 10 while the child goroutine may be still writing to the locationErr inside the deferred doCleanup()function (not shown for brevity).

7. Running tests in parallel for Go’s table-driven test suite idiom can often cause data races, either in the product or test code
Testing is a built-in feature in Go. Any function with the prefix Test in a file with suffix _test.go can be run as a test via the Go build system. If the test code calls an API testing.T.Parallel(), it will run concurrently with other such tests. We found a large class of data races happen due to such concurrent test executions. The root causes of these data races were sometimes in the test code and sometimes in the product code. Additionally, within a single Test-prefixed function, Go developers often write many subtests and execute them via the Go-provided suite package. Go recommends a table-driven test suite idiom to write and run a test suite. Our developers extensively write tens or hundreds of subtests in a test, which our systems run in parallel. This idiom becomes a source of problem for a test suite where the developer either assumed serial test execution or lost track of using shared objects in a large complex test suite. Problems also arise when the product API(s) were written without thread safety (perhaps because it was not needed), but were invoked in parallel, violating the assumption.
Summary of Findings
We analyzed the fixed data races to classify the reasons behind them. These issues are tabulated as follows. The labels are not mutually exclusive.
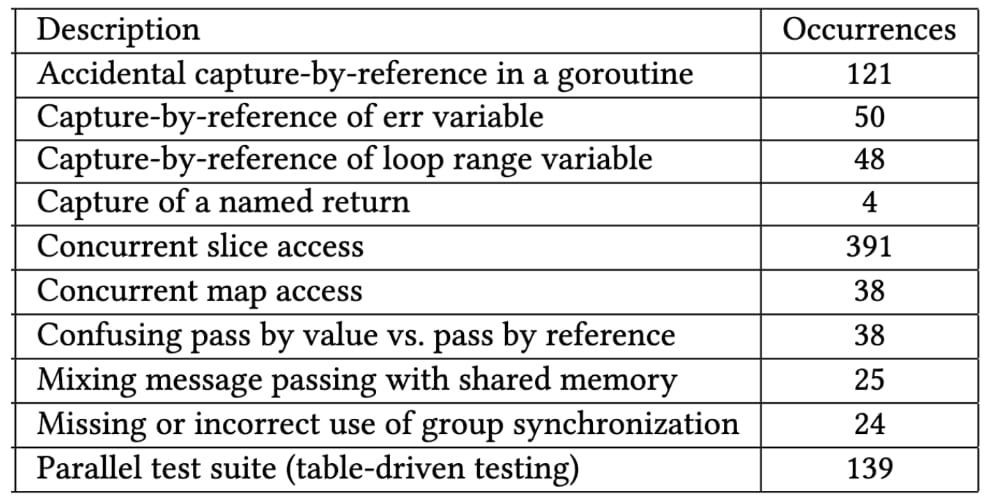
An example for each pattern of a data race is available from this link.
In summary, based on observed (including fixed) data races, we elaborated the Go language paradigms that make it easy to introduce races in Go programs. We hope that our experiences with data races in Go will help Go developers pay more attention to the subtleties of writing concurrent code. Future programming language designers should carefully weigh different language features and coding idioms against their potential to create common or arcane concurrency bugs.
Threats to Validity
The discussion herein is based on our experiences with data races in Uber’s Go monorepo and may have missed additional patterns of data races that may happen elsewhere. Also, as dynamic race detection does not detect all possible races due to code and interleaving coverage, our discussion may have missed a few patterns of races. Despite these threats to the universality of our results, the discussion on the patterns in this paper and the deployment experiences hold independently.
This is the second of a two-part blog post series on our experiences with data race in Go code. An elaborate version of our experiences will appear in the ACM SIGPLAN Programming Languages Design and Implementation (PLDI), 2022. In the first part of the blog series, we discuss our learnings pertaining to deploying dynamic race detection at scale for Go code.
Main Image Credit: https://creativecommons.org/licenses/by/2.0/

Milind Chabbi
Milind Chabbi is a Senior Staff Researcher on the Programming Systems Research team at Uber. He leads research initiatives across Uber in the areas of compiler optimizations, high-performance parallel computing, synchronization techniques, and performance analysis tools to make large, complex computing systems reliable and efficient.

Murali Krishna Ramanathan
Murali Krishna Ramanathan is a Senior Staff Software Engineer and leads multiple code quality initiatives across Uber engineering. He is the architect of Piranha, a refactoring tool to automatically delete code due to stale feature flags. His interests are building tooling to address software development challenges with feature flagging, automated code refactoring and developer workflows, and automated test generation for improving software quality.
Posted by Milind Chabbi, Murali Krishna Ramanathan
Related articles


Most popular

Adopting Arm at Scale: Bootstrapping Infrastructure

Adopting Arm at Scale: Transitioning to a Multi-Architecture Environment

A beginner’s guide to Uber vouchers for riders
