Introducing WorkflowGuard: The Workflow Governance and Observability System That Oversees over 120,000 Data Workflows
13 October 2022 / Global
Data is critical for Uber’s business. At Data Infrastructure, we strive to provide a better experience for our users who are running petabyte-scale data applications. The cost of running these applications continues to grow. In fact, the Big Data Platform was one of the most expensive among the internal platforms at Uber (ref).
We plan to expand our infrastructure while keeping the costs low.
At Uber, over 120,000 production workflows are orchestrated, scheduled, and executed every day. These workflows are owned by over 3,000 users across many teams within Uber, powering critical ETL jobs, business metrics, dashboards, machine learning models, or critical regulatory reports. Internally, the Data Workflow Platform (DWP) team makes this happen by developing Uber’s centralized workflow management system with high infrastructure reliability and minimum scheduling latency. The workflow management system also comes with a user-friendly application that allows users to create, author, and manage both streaming and batch workflows in a self-serve way.
However, problems arise as the number of workflows running on the platform grows. One problem is the increasing compute resource demand from rapidly growing workflows. With the straightforward workflow management UI, authoring and managing workflows has become a cakewalk, which can be finished in minutes with a few clicks on the website. As a result, the number of workflows and their executions has continued to increase over the past few years. For instance, we have a Presto Task that executed approximately 240,000 Presto queries weekly at the beginning of H1 2021, and that number was growing at a steady pace of 4% per week. At this rate, it is estimated that the number of active Presto queries would double every 5 months with additional clusters required.
Another problem is the task execution delay with “traffic burst.” Traffic burst occurs when a lot of tasks are scheduled to run concurrently at the same time. It brings congestion in the downstream service and overloads the computing clusters. When the clusters are overloaded, the tasks step on each other to compete for the shared resources, and as such are more likely to timeout. These timeout tasks could exacerbate the traffic burst when they are re-submitted with the retry mechanism. In a traffic burst, all tasks sharing the same pool are impacted. However, the most significant consequence comes from those production workflows, high-priority tasks, and tight-SLA ETLs. Failures or missed SLA in these top-tier workflows could cause high-impact incidents.
In order to solve the above problems, create a better user experience, and also achieve greater reliability, workflow health, and cost efficiency, DWP introduced WorkflowGuard, the workflow governance and observability system. WorkflowGuard implements workflow task prioritization, resource isolation, workflow recycling, and workflow configuration sanity checks for the entire workflow lifetime and provides observability on usage and costs.
What is WorkflowGuard?
WorkflowGuard is a comprehensive service for workflow configuration, workflow resource and life cycle management that covers the entire workflow lifetime. DWP relies on WorkflowGuard to enforce good user behavior in workflow creation and deployment, prioritize and isolate resources, flag inefficient workflows or cost-heavy user groups, monitor workflow performance, track computing resource growth, and in many other areas. DWP translates these governance details into policies, and provides user-interactive governance UI as a centralized place for users to check all the policies applied to a workflow and fix the violations in a self-serve way.
One typical use case for WorkflowGuard is to prioritize and isolate resources for workflows. WorkflowGuard allows users to tag workflows with “Tier” tag to define the importance of a workflow in terms of business/revenue impact to Uber. With Tier tag DWP can isolate important workflows from unimportant ones, and prioritize critical workflows in scheduling, throttling, computing, and allocation of resources. In terms of resource isolation, DWP isolates resources based on not only the workflow tier but also the team LDAP group name. In this way, each team has their own resource quota and shared pools. Coordinating resources within one team turns out to be more efficient. Also a traffic burst is easier to detect and solve when it happens on a team level, and won’t impact workflows of external teams.
Another typical use case is to detect and recycle inefficient workflows. A workflow can be inefficient when it is very expensive, keeps failing, or turns into a legacy workflow as business goals shift. The majority of these workflows are left unattended in the platform without proper governance. They eventually compete for resources with crucial production workflows on the platform and impact the performance of all other workflows. With WorkflowGuard, DWP is able to bring attention to these workflows hidden underneath the surface, and automatically depriorize/suspend/delete the workflows before they could potentially degrade the entire service.
Architecture and Design
Overview
DWP¹ built WorkflowGuard as a governance and monitoring service with a foundation in event processing and metadata across multiple services.
On the presentation layer, it provides the interactive UI to create and manage governance rules.
On the product layer, it translates requirements of task prioritization, resource isolation, and workflow recycling into policies, and makes API calls for governance action implementation. It also visualizes the workflow execution metadata and resource usage for monitoring and insight purposes.
On the core infrastructure layer, it centralizes the underlying knowledge base, infrastructure and operations. It leverages the event and metadata from multiple services for workflow efficiency analysis, workflow tiering fulfillment, and governance rule violation detection. It then makes the governance decision based on the information collected, and notifies the user about the governance decision and workflow status change. This will be discussed with more details in the following section.
¹ DWP uses the workflow Tier to define the workflow importance. Workflows become less important from Tier 1 to Tier 5. For example, a Tier 1 workflow is one of the most impactful that generates critical source-of-truth data, and its failure will have a direct impact on revenue, brand, loss of license, or breach of regulatory/finance compliance. In contrast, Tier 5 are temporary workflows used for testing purposes and are subject to cleanup at any time.
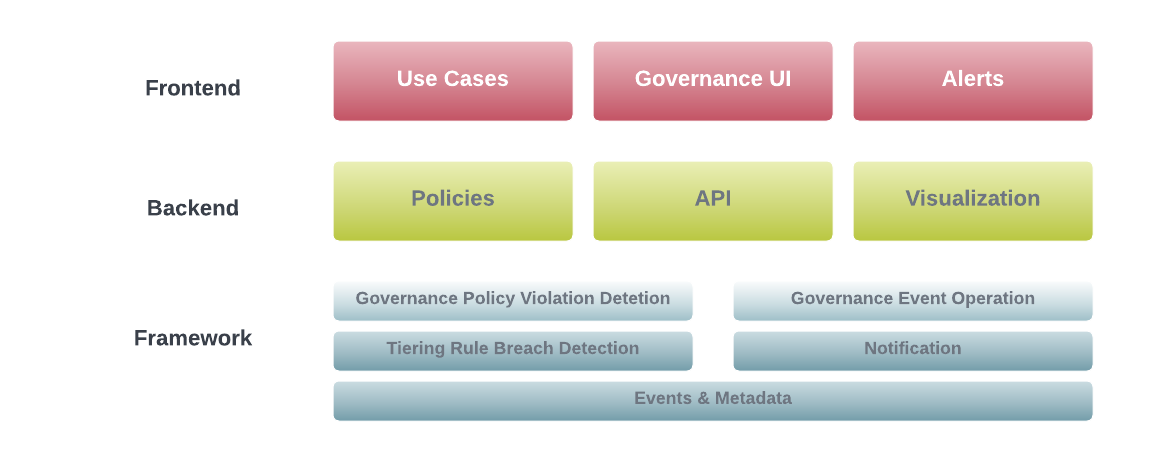
Architecture
WorkflowGuard includes 5 main components: event detector, policy validator, governance executor, notification service, and governance observability service. Their interactions, the flow of data, and the controlling path are illustrated in the system architecture in Figure 2.
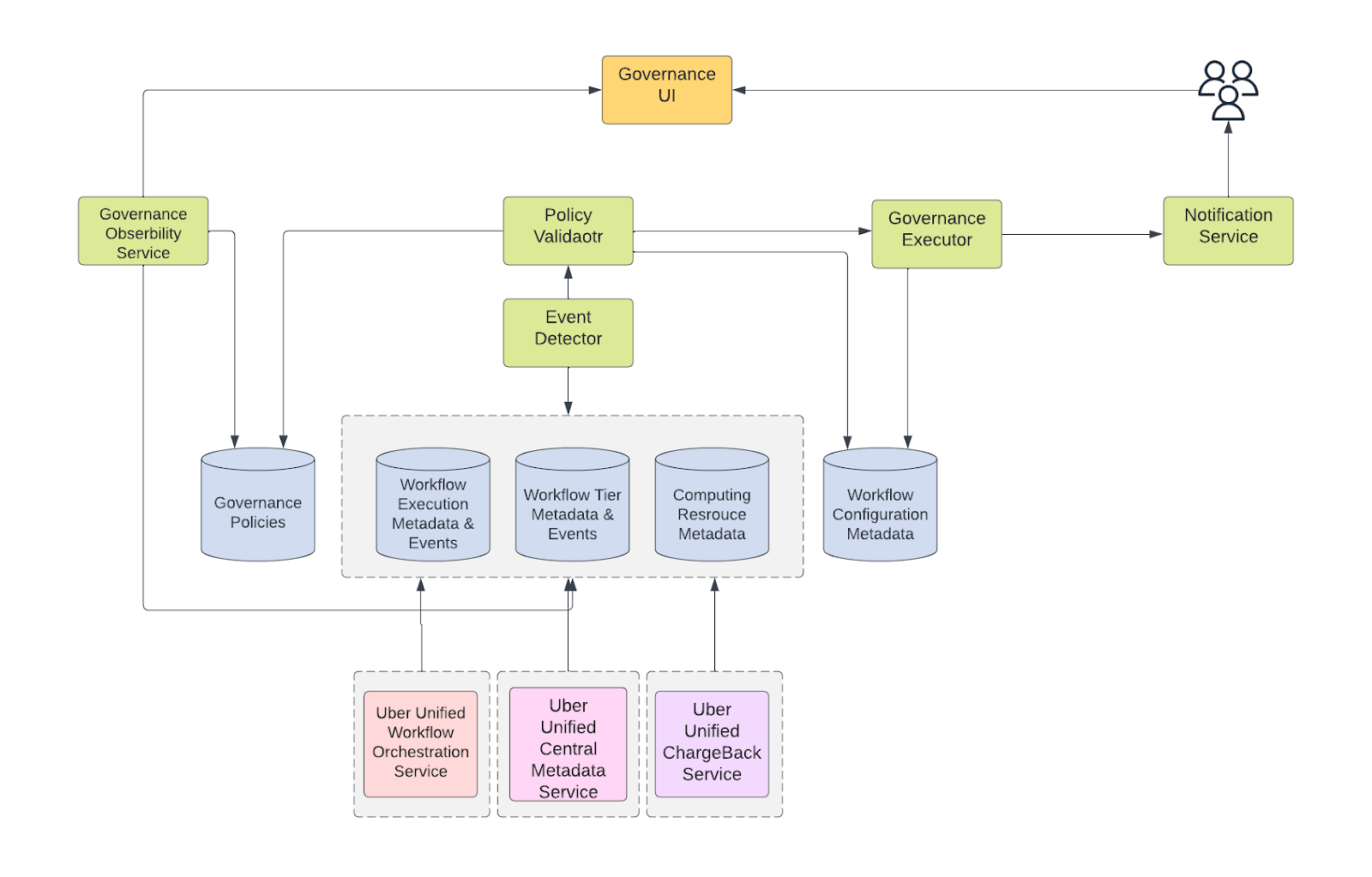
Event Detector
Event detector collects and detects major events of a workflow, such as execution status update, tier change, and computing cost aggregation. A pull model is applied here to collect metadata and events from multiple services on a regular basis. Some latency in detection is acceptable here, as the majority of workflows are scheduled on at least an hourly basis, plus DWP doesn’t request real-time governance for now.
Policy Validator
Policy validator implements the validation function in 2 aspects. First, it validates a workflow event against the governance policies after it receives a signal from the event detector. Based on the governance policies, it makes the decision whether to suspend/delete/downgrade the workflow. The policies can be configured in Flipr (an Uber centralized rules engine).
| Suspend | – Workflow retention period reached – Owner left Uber – Task kept failing – Heavy query/resource quota exceeded |
| Delete | – Workflow has been in inactive/paused status for more than 180 days |
| Tier Downgrade | – Workflow alert setting does not meet tier-based criteria (for example, page alert is required for Tier 1 workflows) – Workflow ownership unknown/unclear – 90 days’ success rate drops below tier-based threshold |
Second, it performs the sanity check on workflow configuration. To enforce standards during workflow creation and deployment, DWP defines dedicated rules on workflow settings. These rules include retention period, resource pool, schedule intervals, max retries, and are validated by the policy validator at runtime during the workflow creation and deployment process, as shown in the following:
| Resource Type | Before Governance Enforcement | After Governance Enforcement |
| Workflowretention period | Unlimited | Varies based on workflow tier, can be as long as one year |
| Number of tasks per workflow | Unlimited | 2K |
| Max JSON size of API based workflow | Unlimited | 2MB |
| Minimum schedule interval | No restriction | 15 min for scheduled workflows, no restriction for event-trigger workflows |
| Task Retries | Unlimited | 3 |
| Task timeout | As long as 48 hours | 8 hours |
| Workflow/Job execution history | Unlimited | Job history is kept for up to 2 years or up to the last 1,000 executions |
| Resource pool access | No restriction | Restricted access based on LDAP and task type |
| Consecutively failing workflows | No restriction | Auto-pause after consecutively failing for the last 10 scheduled runs |
Governance Executor
Governance executor receives the governance decision from the policy validator. It updates workflow status metadata directly in the workflow configuration database. When the cleanup signal is received, it cleans up the workflow metadata in the database, as well as all the data properties associated with the workflow, such as tier, alert, ownership, and data-quality checks. Governance executor also sends the signal to the notification service so that users are aware of the workflow status change immediately.
One thing to note is that for some policies DWP sets a “grace period” for users to fix the violations before the governance action is implemented. For example, when a workflow is approaching its end date, the governance executor actually triggers the notification service to send out the reminders 7 days ahead of the end date. In this way users have enough time to revisit their workflows, and extend the TTL by renewing their workflow.
Notification Service
Notification service receives notification requests, and notifies users before and after the governance event happens. The notification channels include email, page, and JIRA.
Governance Observability Service
Governance Observability collects metadata from multiple services and calculates workflow metrics. It is not directly involved in the “governance process,” but it is also a crucial part of WorkflowGuard as it answers questions such as what policies are applied, why the workflow is suspended, how reliable this workflow is, how much money it spends, and what is the estimated SLA. These are all important questions to both users and us as workflow platform owners. DWP will discuss this more later.
Performance Improvement from Governance
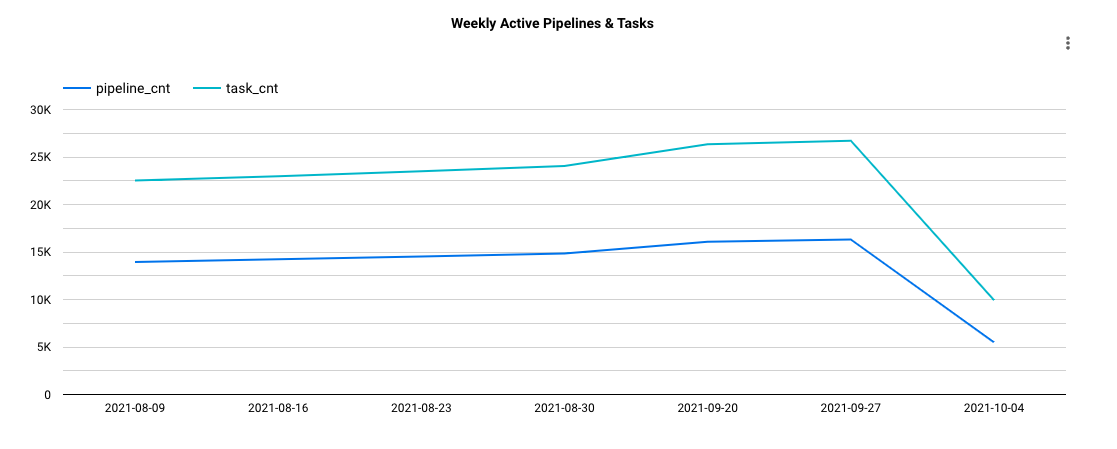
DWP has seen significant improvement in workflow reliability and cost efficiency since introducing WorkflowGuard. Taking Presto executions for example, DWP saw over 9,000 Presto workflows deactivated (66% reduction, see Figure 3) after rolling out the workflow retention policy. These are all legacy workflows without maintenance.
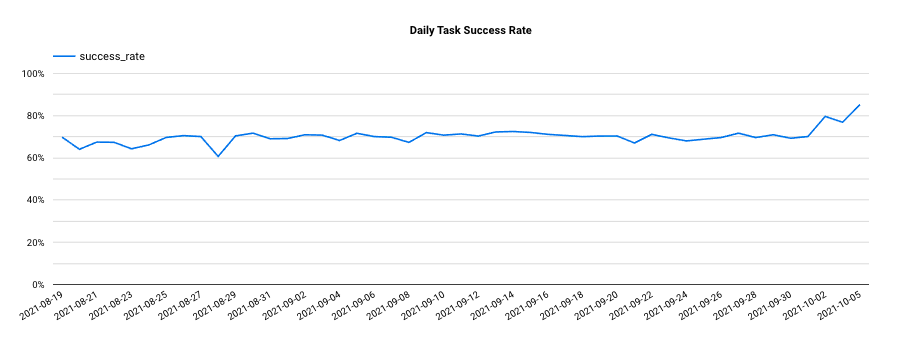
DWP also saw the overall Presto execution success rate increase from 69.28% to 85.22% (Figure 4). This is because a bunch of consecutive failed executions retired with the legacy workflow cleanup, which used to drive down the overall success rate. Besides that, the computing power was greatly released, which reduces the chance of timeout failure.
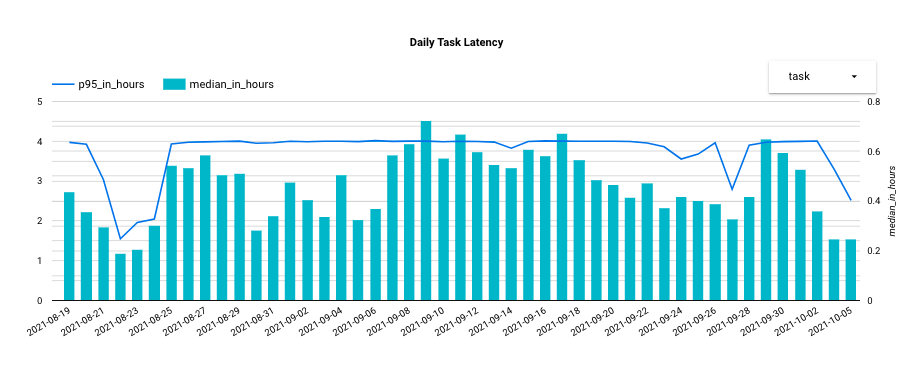
With the computing power release, the total amount of queued tasks (Figure 5) and queueing time was significantly reduced, and the overall median task execution latency reduced from 40 to 15 minutes (62.5% reduction, Figure 6).
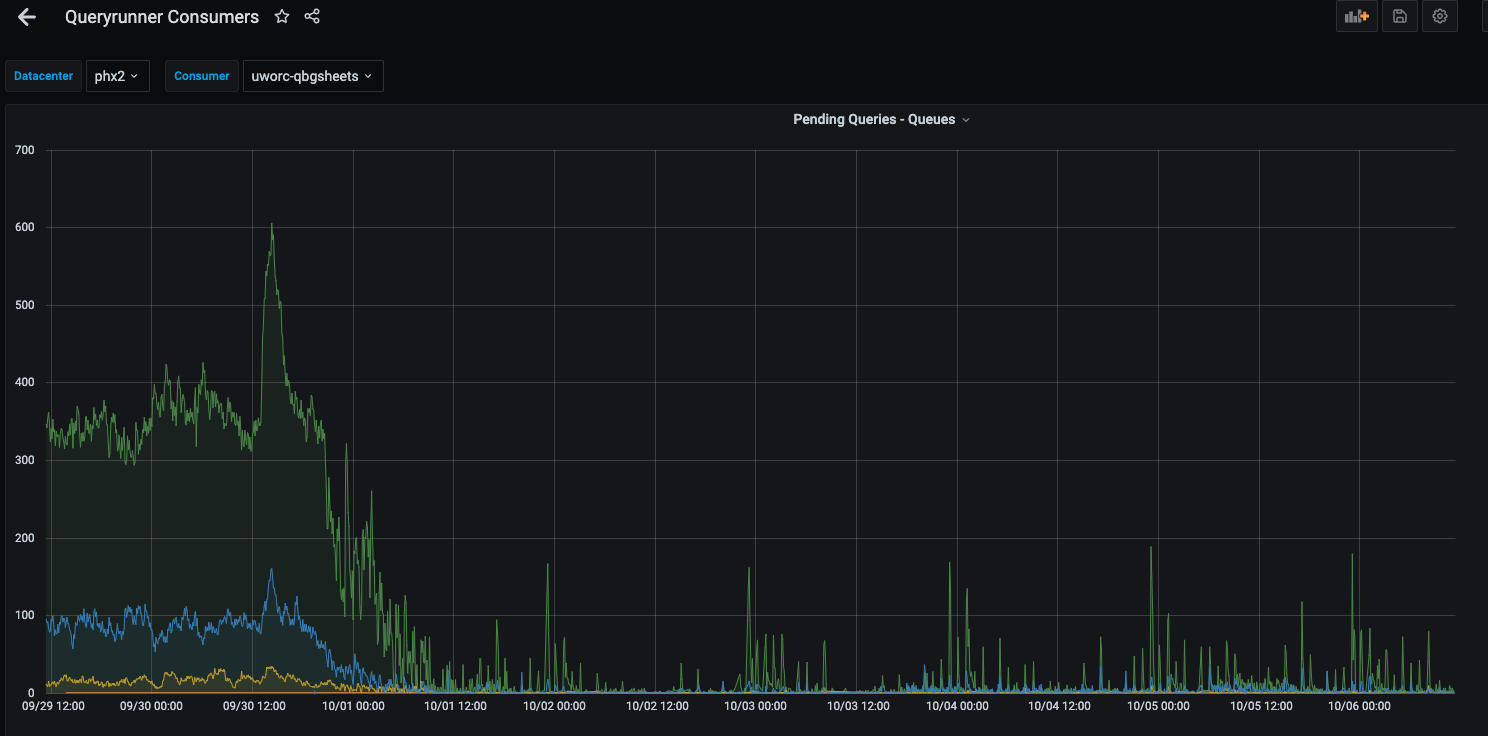
The amortized annual savings of Presto computation from such one policy is around $200,000.
Interactive Workflow Governance
As mentioned earlier, observability has always been one of the top considerations during workflow governance. We put ourselves into the shoes of users, and imagine that here comes a workflow governance alert: some workflow is downgraded/suspended due to governance policy violation. In most cases this needs to be fixed ASAP, since having a workflow regulated can be extremely disruptive–and often very expensive–to the business, making every minute count. The key to helping users mitigate governance violations is to help them rapidly understand why things went wrong, which policy is violated, where in the workflow it’s happening, and most of all, how to fix it.
To achieve this, DWP is building the interactive governance UI, which serves as the centralized place to show all the governance information and provide users the tools to interact with workflow governance functionality.
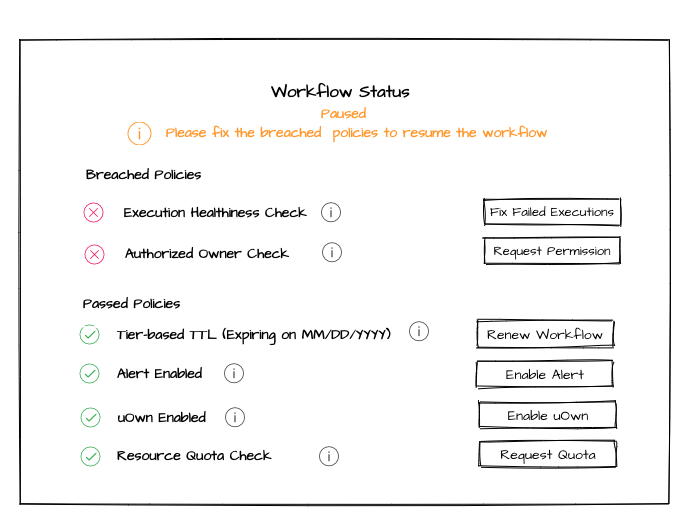
The governance UI enables users to interactively explore governance policies and fix violations. When the policy is breached, users receive either an email alert or a pager which guides them to the governance UI page. In a violation scenario, the workflow status turns into abnormal status (e.g., “paused,” “expired,” etc.), with a warning message urging a fix for the issue. The list of breached policies is shown at the top of the governance page, with the button for one-click fix next to each policy. Seamless support for one-click fix was crucial to reduce overhead in troubleshooting and mitigate the violation.
Collaborative Workflow Insight Dashboards
Observability also plays an important role in helping users and service owners better understand the workflows, and hence reduce the communication overhead. Before WorkflowGuard came online, the health, scheduling, queueing, and resource consumption were a blackbox to users. Without insights, it is difficult for users to understand why the executions are pending, queue buildup, query slowdown, and the workflow’s financial impact.
WorkflowGuard provides such insights by monitoring and visualizing multiple workflow metrics. The visualization brings convenience to both users and service owners.
Let’s showcase WorkflowGuard’s insight dashboard with a visual demonstration. In this specific example, one of the user teams is seeing slowness in recent executions, and figures out that the increased time comes from waiting in queue. To speed up the execution and avoid missing SLA, they request a 25% increase in their computing resource quota.
Before approving their request, DWP would like to evaluate the workflow resource usage status of this specific team. WorkflowGuard provides different grain and levels of aggregation for users to filter.
DWP then walks through WorkflowGuard’s various visualization dashboards to narrow the investigation down further. DWP first leverages the time-serious view to determine the overall resource consumption trend of this team. In this case, DWP found that the overall resource usage was actually down in recent weeks. However, the breakdown of workflow service sources showed that there was an increase in backfilling usage (Figure 8).
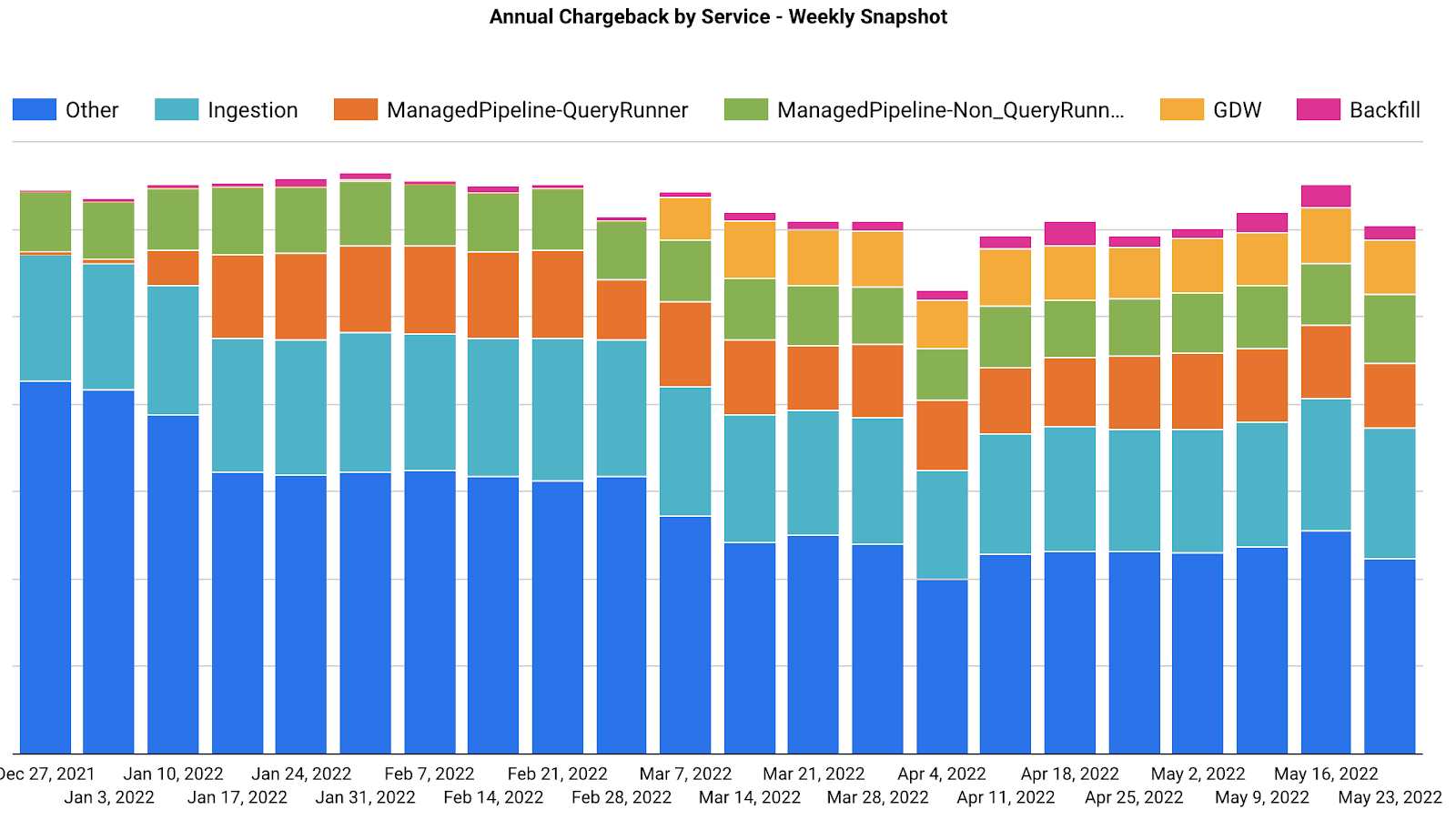
DWP then switched to the Top Usage Workflow Dashboard, with the purpose of understanding which workflows are consuming the most resources. DWP found that in addition to high-tier workflows, there are also several backfilling workflows with low-tier or no-tier status serving as top consumers on the list (Figure 9). These expensive backfilling workflows all came from one single user.
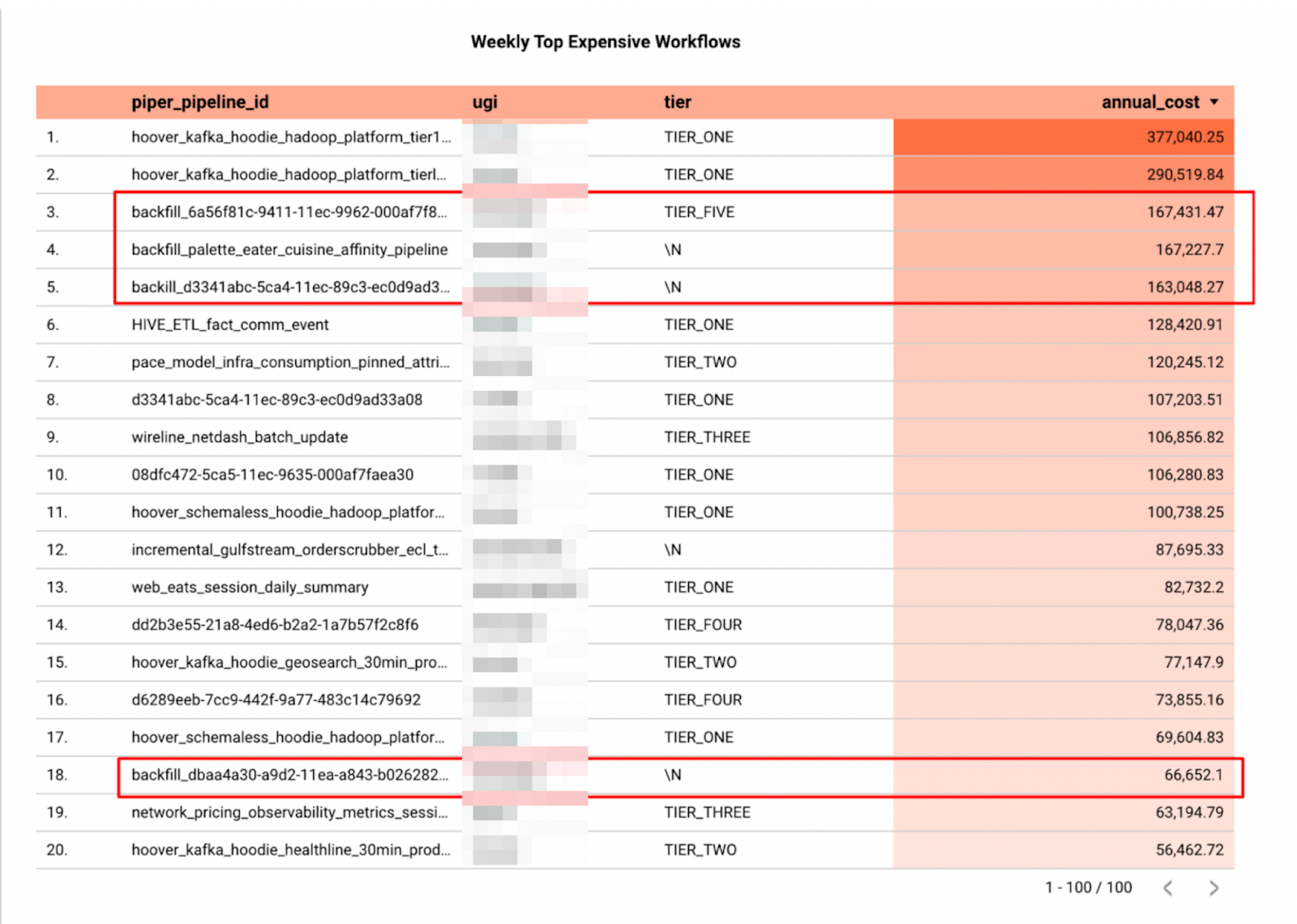
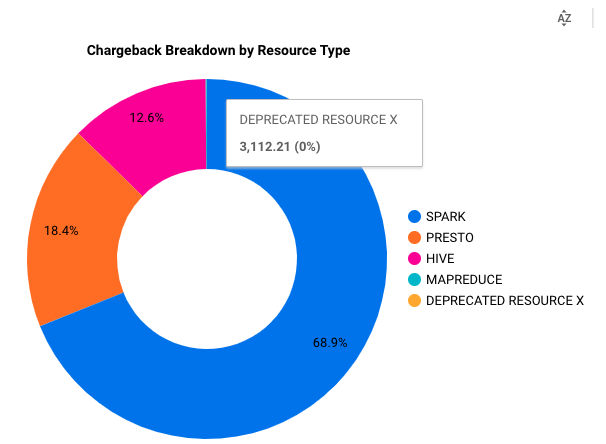
With the metrics and information provided by the dashboard, DWP suspected that the workflow slowness was caused by the expensive backfilling workflows. DWP took a closer look at these backfilling workflows, and noticed that they were using a resource type that is under deprecation. By changing the dashboard breakdown to specific resource type, DWP found that this resource only contributes to 0.01% of total resources usage of this team (Figure 10), which means several random expensive workflows could dominate the resource pool and slow down all other production workflows. DWP then reached the conclusion that before increasing the resource quota, we needed to understand the purpose of these unexpected backfilling workflows, rather than increase the resource capacity right away for unconscious usage. Finally we assembled our results into a shareable report with additional comments and references. Since the users also have access to the insights, they can use this report to refer back to the metrics and data sources involved or even continue and refine the investigation. At DWP we commonly use this functionality to investigate resource-related issues, analyze the issue with usage dashboards, communicate with users, then monitor the recovery, and ultimately serve as an archived report for future reference.
Looking Ahead
Push model to trigger governance event: Apart from the pull model, we are considering enabling a push model for governance events. This will allow near-real-time punishment for the violation of critical policies (e.g., unauthorized launch of Titan workflows).
Cascading cleanup: In many cases, cleaning up a workflow indicates a business goal has reached its end of life. In fact, not only does the workflow need to be cleaned, but the dataset/report/dashboard also needs to be removed or archived. At the same time, the removal of downstream assets can indicate the suspension/deletion of upstream workflows. Thus DWP has the plan to work with downstream teams to enable the lineage of workflow and data assets, and automate the cascading cleanup of upstream and downstream.
Conclusion
Introducing WorkflowGuard has been a major improvement to workflow reliability, cost efficiency and observability. Infrastructure-wise, it allowed us to suspend inefficient workflows, recycle computing resources, prioritize crucial executions, and isolate resources. From a product perspective, it enforces best user practice, brings workflow observability to users, and provides a better user experience by reducing the chance of traffic burst and workflow slowness. Together these improvements have made the workflow platform more stable and improved the data user experience at Uber.

Chengchun Yan
Chengchun Yan is a Senior Software Engineer on Uber’s Data Workflow Platform Team. She works on building workflow governance, improving workflow reliability, resource cost-efficiency and user observability.

Jing Shi
Jing Shi is a Senior Engineering Manager for the Data Workflow Platform team at Uber. Her team builds a scalable, reliable, and multi-region platform to orchestrate, schedule, and execute production grade repetitive data jobs. Users can leverage their unified workflow UI and ecosystem to author, manage, and govern streaming and batch workflows with self-serve, automation capability.

Sudhir Mallem
Sudhir Mallem is a Sr. Staff Engineer on the Data Infrastructure team at Uber. He has worked on building and scaling the global data warehouse. Over the last year he has been focusing on several projects on cost-efficiency and reliability of data workflows and supporting the Data Workflow Platform team to scale their services.
Posted by Chengchun Yan, Jing Shi, Sudhir Mallem
Related articles




Most popular

Making Uber’s ExperimentEvaluation Engine 100x Faster

Genie: Uber’s Gen AI On-Call Copilot

Open Source and In-House: How Uber Optimizes LLM Training

Horacio’s story: gaining mobility independence through innovative transportation solutions
Products
Company