Open Source and In-House: How Uber Optimizes LLM Training
17 October 2024 / Global
Introduction
Generative AI powered by LLMs (Large Language Models) has a wide range of applications at Uber, like Uber Eats recommendations and search, customer support chatbots, code development, and SQL query generation.
To support these applications, Uber leverages open-source models like Meta® Llama 2 and Mistral AI Mixtral®, and closed-source models from OpenAI, Google, and other third-party providers. As a leading company in mobility and delivery, Uber also has considerable domain-specific knowledge that can improve LLM performance for these applications. One way Uber incorporates this domain-specific knowledge is through RAG (Retrieval Augmented Generation).
Uber also explores ways to adapt LLMs to Uber’s knowledge base through continuous pre-training and instruction fine-tuning. For example, for Uber Eats, we found that a model finetuned on Uber’s knowledge of items, dishes, and restaurants could improve the accuracy of item tagging, search queries, and user preference understanding compared to open-source model results. Even further, these finetuned models can achieve similar performance to GPT-4 models while allowing for much more traffic at Uber’s scale.
AI community support and open-source libraries like transformers, Microsoft DeepSpeed®, and PyTorch FSDP empower Uber to rapidly build infrastructure to efficiently train and evaluate LLMs. Emerging open-source initiatives like Meta® Llama 3 llama-recipes, Microsoft LoRA®, QLoRA™, and Hugging Face PEFT™ simplify the fine-tuning lifecycle for LLMs and reduce engineering efforts. Tools like Ray® and vLLM™ maximize the throughput of large-scale pre-training, fine-tuning, offline batch prediction, and online serving capabilities for open-source LLMs.
The novel in-house LLM training approach described in this blog ensures Uber’s flexibility and speed in prototyping and developing Generative AI-driven services. We use SOTA (state-of-the-art) open-source models for faster, cheaper, and more secure and scalable experimentation. Optimized in-house LLM training helps Uber maintain cutting-edge technology innovations and passes on the benefits to people who use the Uber app.
Infrastructure Stack
A critical component of LLM training at Uber is the thoroughly tested infrastructure stack that enables rapid experimentation.
Layer 0: Hardware
Uber’s in-house LLM workflows are scheduled on 2 kinds of computing instances: (1) NVIDIA® A100 GPU instances in Uber’s on-prem clusters and (2) NVIDIA H100 GPU instances on Google Cloud. Each Uber on-prem A100 host is equipped with 4 A100 GPUs, 600 GB memory, and 3 TB SSD. On Google Cloud, each host is a 3-highgpu-8g machine type, with 8 H100 GPUs, 1872GB CPU memory, and 6TB SSD. These machines are managed as part of the Crane infrastructure stack.
Layer 1: Orchestration
Computing resources are managed by Kubernetes® and Ray. Kubernetes is used to schedule training workloads and manage hardware requirements. Ray, along with the KubeRay operator, is used for distributing the workload to the workers.
Layer 2: Federation
The end-to-end flow of resource management is depicted in Figure 1 below. Our multiple Kubernetes clusters are managed by a federation layer, which schedules workloads based on resource availability. Training jobs are modeled as a Job with multiple Tasks. The JobSpec defines the goal state of the Job and includes information like the instance SKUs, clusters, compute/storage resources, and post-Docker-launch commands to set up tokens and environment variables.

Training Stack
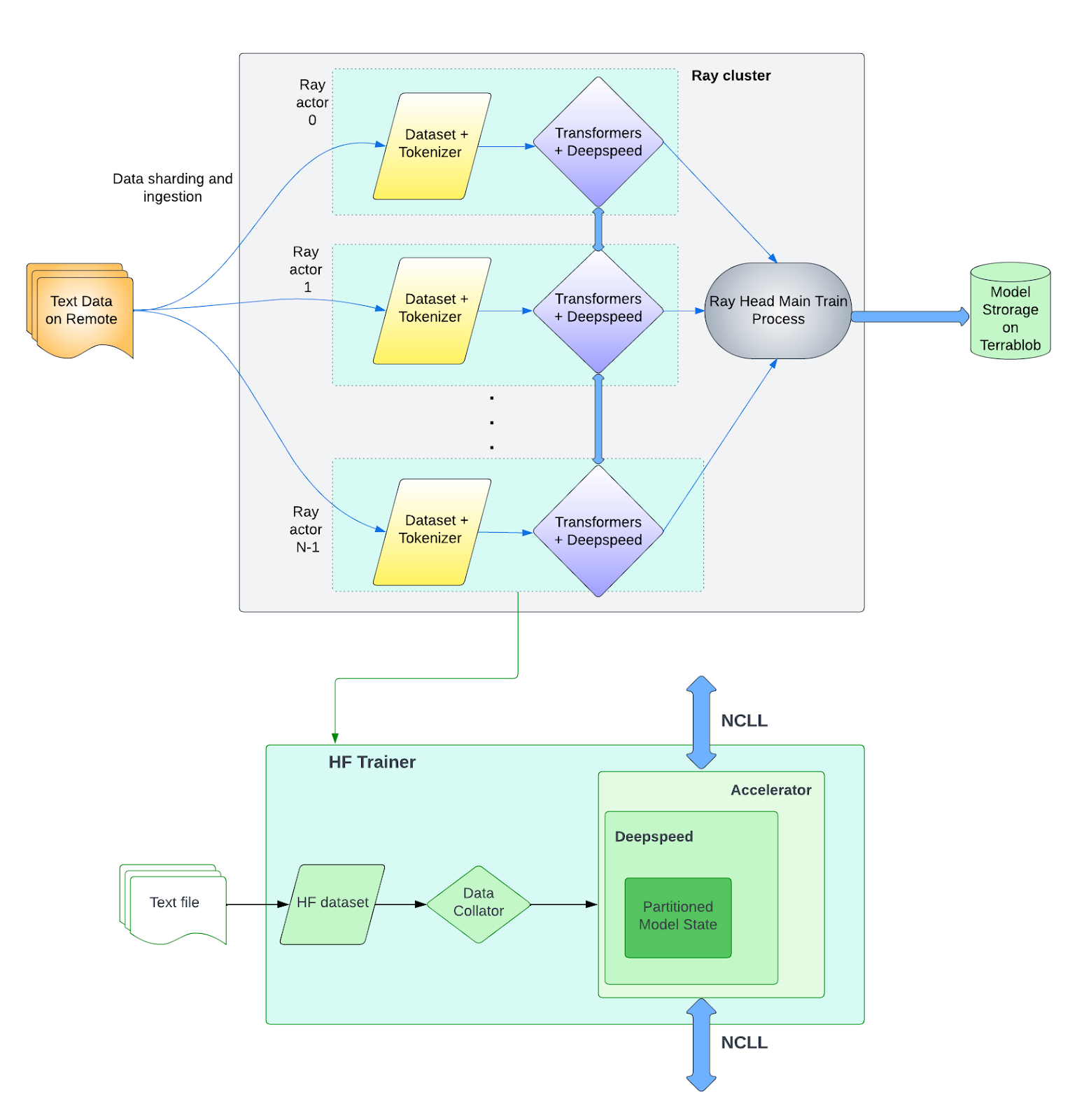
We fully embraced open source when building our LLM training stack. Specifically, we integrated PyTorch, Ray, Hugging Face, DeepSpeed, and NCLL to enable training LLMs with the Michelangelo platform.
- PyTorch is our chosen deep learning framework because most SOTA open-source LLMs and techniques are implemented in PyTorch.
- Ray Train provides a thin API to perform distributed training using PyTorch on Ray clusters.
- Hugging Face Transformers provide APIs and tools to download and train SOTA transformer-based models.
- DeepSpeed is a deep learning optimization software suite that enables unprecedented scale and speed for deep learning training and inference.
As shown in Figure 2 below, Ray is at the top of the LLM training stack for coordinating tasks. NCCL is at the bottom level for GPU communication.

Distributed Training Pipeline
To support our in-house implementation, we built an LLM distributed training pipeline that includes host communication, data preparation, distributed model training, and model checkpoint management. Here is how it works:
- Multi-host and multi-GPU communication. To start, a TorchTrainer in Ray Train creates multiple workers in the form of Ray Actors, handles in-bound communication (used by Ray Object Store), and initializes a PyTorch distributed process group (used by Deepspeed) on GPUs across all hosts.
- Data preparation. The LLM training framework supports remote data sources on Uber HDFS, Uber Terrablob, and Hugging Face public datasets.
- Model training. Tokenization converts input text into integers that will be fed into the models. For distributed training, each GPU worker initializes a Hugging Face Transformers Trainer object using the DeepSpeed ZeRO stage 1/2/3 options.
- Saving results. Metrics associated with the training experiment are saved on the Uber Comet server. The main training process on the Ray head node pushes training model weights and associated configuration files to Terrablob storage.
Training Results
Our exploration involved demonstrating that the in-house Michelangelo platform has the capability and scalability to train any open-source LLM with throughput optimization.
Training on State-Of-The-Art LLMs
We found that the Michelangelo platform can support the largest open-source LLMs while training under different settings, including full-parameter fine tuning and parameter-efficient fine tuning with LoRA and QLoRA.

Figure 4 (above) shows the training loss curve for Llama 2 13B and Llama 2 70B with and without LoRA. We found that, even if LoRA and QLoRA use far fewer GPUs and train much faster with fewer GPUs, the loss decreases much less than the full parameter training. Therefore, it’s important to improve the throughput/Model Flops Utilization (MFU) for full parameter fine-tuning of LLMs.
Throughput/MFU Optimization
Scaling the transformer architecture is heavily bottlenecked by the model’s self-attention mechanism, which has quadratic time and memory complexity. To achieve better training throughput, we’ve explored several industry recommended efforts to optimize GPU memory usage: CPU offload and flash attention.
The first training throughput optimization we explored was using DeepSpeed ZeRO-stage-3 CPU Optimizer Offload, which led to at least 34% GPU memory reduction with the same batch size when training Llama 2 70B. This allowed us to increase the batch size by 3-4 times but still keep the same forward and backward speed, so the training throughput increased by 2-3 times.
The second training throughput optimization explored was following Hugging Face’s suggestion to use flash attention. Flash attention is an attention algorithm used to reduce quadratic complexity and scale transformer-based models more efficiently, enabling faster training. With flash attention, we could save 50% of GPU memory with the same batch size. If we maximized the usage of GPU memory, then we could double the batch size while keeping compatible forward and backward speed.
To study training efficiency, we used Hardware Model Flops Utilization (MFU). MFU is the ratio of the observed throughput to the theoretical maximum throughput if the benchmarked hardware setup was operating at peak FLOPS with no memory or communication overhead.
In our benchmark, we used Deepspeed Flops Profiler to obtain the expected FLOPS number. FLOPS per GPU was calculated as: forward and backward FLOPS per GPU/iteration latency. Then we divided it by the device’s peak theoretical performance and obtained our final MFU metric. In all our experiments, we maximized the batch size under different optimization settings so that GPU memory was fully utilized. We did this with the training arguments, setting gradient_accumulation_steps = 1 so that macro_batch_size = micro_batch_size x num_gpus x 1.
Here’s what we found:
- Throughput: Both flash attention and CPU offload saved GPU memory, enabling us to increase batch size 2 to 7 times during Llama 2 70B training with maximum GPU memory usage (70GB-80GB) on 32 GPUs (8 hosts on A100, 4 hosts on H100). This led to significant throughput increases.
- MFU: MFU on H100 was lower than on A100, and GPU utilization wasn’t full with maximum GPU memory usage. This might indicate that for Llama 2 70B training, we have memory-bound GPU instead of compute-bound. That’s also why CPU offload could help the most to improve MFU, as plotted in Figure 5 below.
- Compute or Memory Bound: The story is slightly different for Llama 2 7B on 4 A100/H100 on a single host, where we may have compute-bound GPU instead of memory-bound GPU. We saw that the MFU of training Llama 2 7B was higher than training Llama 2 70B, and CPU offload was not helpful to improve MFU. Flash attention could help the most, as shown in Figure 6 below.
- Network: In our experiment, the network usage was around 10GB/second on H100 and 3GB/second on A100 for Llama 2 70B model training. This is small compared to the infra theoretical value, indicating that the network is yet to be a bottleneck compared to GPU compute and memory.


LLM Scorer
To evaluate the raw or finetuned models, we also implemented an offline LLM scorer to predict on large datasets. We used Ray to create a cluster on Kubernetes with multiple instances and each instance with multiple GPUs. This way, we could distribute the data and score in parallel. On each instance, we used inference servers such as vLLM.
In our implementation, we used Ray jobs as the operational foundation. Each Ray job allocates a specified number of CPU and GPU resources, downloads models, and partitions datasets by rank. The Ray `ActorPool` aggregates the outputs from different Ray Actors. Figure 7 below shows the implementation of this LLM scorer.
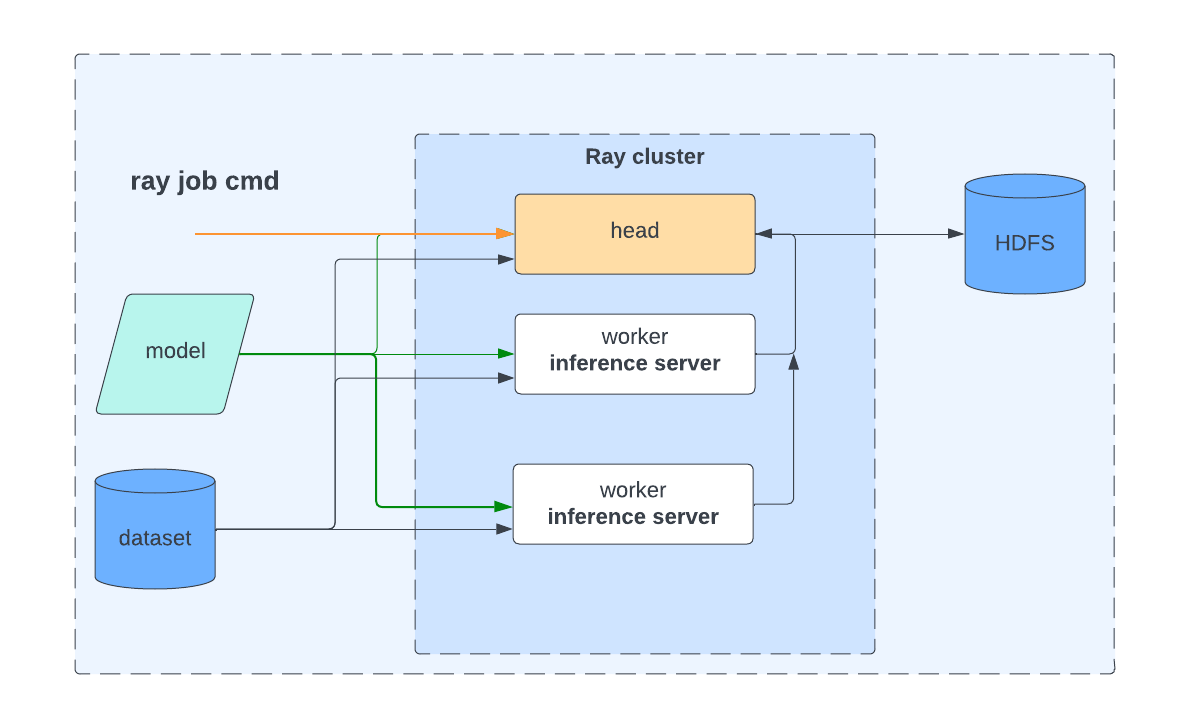
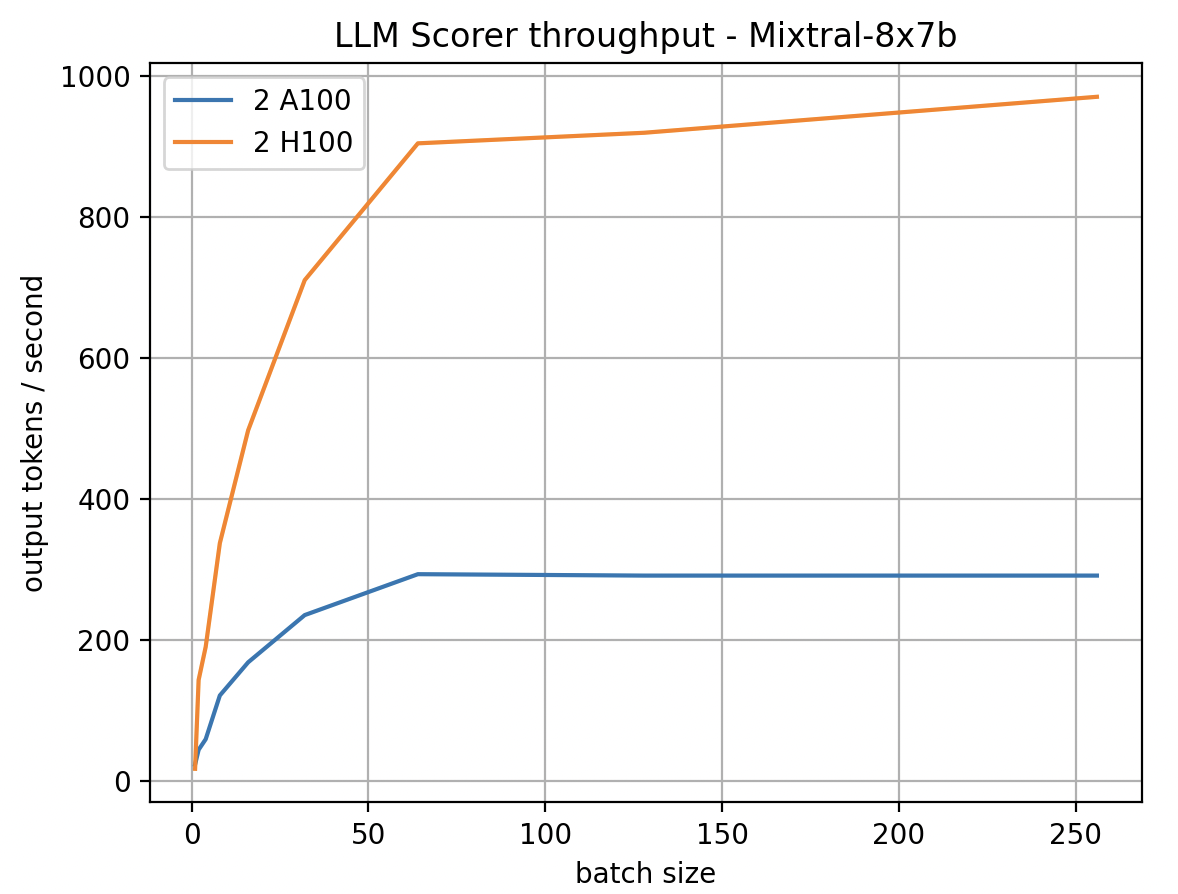
Figure 8 below summarizes the performance of batch prediction for Mixtral 8x7b models using 2 A100 and H100 GPUs, where the input token size is 4K and the maximum output tokens are 700. We observed that output tokens per second increased linearly for batch sizes up to 64 on both GPU types. Notably, the H100 achieved a throughput 3 times higher than the A100. This benchmark helps teams make production decisions and plan resource requirements.
Conclusion
As more and larger open-source models get published, like Llama 3 450B, we’ll improve our LLM training infrastructure to support fine-tuning them. Using these finetuned models will help us improve things like Uber Eats recommendations and search.
Thinking about the broader industry, our journey exploring in-house LLM training has brought us these insights:
- Embracing open source is the key to catching up with generative AI trends. In a short time, we’ve seen and benefitted from the fast-growing open-source community Hugging Face and the rapid adoption of DeepSpeed. Open-source model structures like Falcon, Llama, and Mixtral are published one-after-another every few months. With open-source solutions, we can train SOTA LLMs and achieve the industry standard MFU to maximize GPU usage.
- Having long-time-tested and extensible cluster management is critical to catching the latest trends quickly. Our well-established Ray and Kubernetes stack makes it easy to integrate new open-source solutions into our production environment.
Acknowledgements
This major step for GenAI at Uber couldn’t have happened without the many teams at Uber who contributed to it: Michelangelo, Applied AI, Dev Platform, and Platform Core Service.
Apache®, Apache Kafka, Kafka, Apache Spark, Spark, and the star logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Deepspeed® and its logo, LoRA® and its logo are registered trademarks of Microsoft® in the United States and other countries. No endorsement by Microsoft is implied by the use of these marks.
Kubernetes® and its logo are registered trademarks of The Linux Foundation® in the United States and other countries. No endorsement by The Linux Foundation is implied by the use of these marks.
Llama 2®, Llama 3® and their logos are registered trademarks of Meta® in the United States and other countries. No endorsement by Meta is implied by the use of these marks.
Mixtral® and its logo are registered trademarks of Mistral AI® in the United States and other countries. No endorsement by Mistral AI is implied by the use of these marks.
NVIDIA® and the NVIDIA logo are trademarks and/or registered trademarks of NVIDIA Corporation in the U.S. and other countries. No endorsement by NVIDIA is implied by the use of these marks.
PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation.
Transformers® and its logo are registered trademarks of Hugging Face® in the United States and other countries. No endorsement by Hugging Face is implied by the use of these marks.

Bo Ling
Bo Ling is a Staff Software Engineer on Uber’s AI Platform team. He works on NLP, Large language models and recommendation systems. He is the leading engineer on embedding models and LLM in the team.

Jiapei Huang
Jiapei Huang is a Software Engineer working on Deep Learning training infrastructure at Uber Michelangelo team. He has end-to-end experience of AI infra and unblocked multiple business-critical scenarios like LLM, time series modeling, etc.

Baojun Liu
Baojun Liu is a Software Engineer working on online and offline serving, software and hardware co-development for AI Infra at Uber Michelangelo team. Prior to that, he was a deep learning framework architect working on DL compiler intermediate representation, software stack development for heterogeneous architecture, and its enabling for serving and training.

Chongxiao Cao
Chongxiao Cao is a Senior Software Engineer at Uber, leading the development of the deep learning training infrastructure on Michelangelo, including scaling up data throughput, accelerating training speed, increasing model size, and optimizing resource utilization. He also serves as a leading contributor to the Horovod distributed deep learning framework and Petastorm data loading library.

Anant Vyas
Anant Vyas is a Senior Staff Engineer and the Tech Lead of AI Infrastructure at Uber. His focus is on maximizing the performance and reliability of their extensive computing resources for training and serving.

Peng Zhang
Peng Zhang is an Engineering Manager on the AI Platform team at Uber. He supports the teams dedicated to developing modeling and training frameworks, managing GPU-based clusters, and enhancing ML infrastructure for training classical, deep learning, and generative AI models.
Posted by Bo Ling, Jiapei Huang, Baojun Liu, Chongxiao Cao, Anant Vyas, Peng Zhang
Related articles



Most popular

A beginner’s guide to Uber vouchers for riders

Automating Efficiency of Go programs with Profile-Guided Optimizations

Enhancing Personalized CRM Communication with Contextual Bandit Strategies
