Engineering Failover Handling in Uber’s Mobile Networking Infrastructure
14 July 2020 / Global
Millions of users use Uber’s applications everyday across the globe, accessing seamless transportation or meal delivery at the push of a button. To achieve this accessibility at scale, our mobile apps require low-latency and highly reliable network communication, regardless of where customers use our services.
The network communication for all of Uber’s mobile applications are powered by the edge and the mobile networking infrastructures. The edge infrastructure provides secure connectivity for the HTTPS traffic originating from the mobile apps to the backend services. Uber’s edge infrastructure combines the global presence of public cloud platforms that help reduce app latencies with the additional ability to fallback to our own managed data-centers when required for enhanced reliability.
On the mobile side, a core component of our networking stack is the failure handler that intelligently routes all mobile traffic from our applications to the edge infrastructure. Uber’s failure handler was designed as a finite state machine (FSM) to ensure that the traffic sent via cloud infrastructure is maximized. During times when the cloud infrastructure is unreachable, the failover handler dynamically re-routes the traffic directly to Uber’s data centers without significantly impacting the user’s experience.
After rolling out the failover handler at Uber, we witnessed a 25-30 percent reduction in tail-end latencies for the HTTPS traffic when compared to previous solutions. The failover handler has also ensured reasonably low error rates for the HTTPS traffic during periods of outages faced by the public cloud infrastructure. Combined, these performance improvements have led to better user experiences for markets worldwide.
In this article, we share the challenges faced in designing the mobile failover handler for Uber’s applications, and how the design evolved as we operationalized the system across our users globally.
Uber’s edge infrastructure
Uber’s edge infrastructure comprises front-end proxy servers that terminate secure TLS over TCP or QUIC connections from the mobile apps. The HTTPS traffic originating from the mobile apps over these connections are then forwarded to the backend services in the nearest data-center using existing connection pools. The edge infrastructure spans across public cloud and privately managed infrastructures as shown in Figure 1, below, with the front-end proxies hosted both within public cloud regions and in Uber’s managed data-centers:

Hosting the edge servers on public cloud enables us to leverage its widely deployed network of Points of Presence, or PoPs. Terminating the QUIC/TCP connection closer to the user generally results in better performance, translating to lower latency and error rates for the HTTPS traffic. In addition, the cloud’s front-end servers support newer, more performant protocols that further lowers the latencies during poor network conditions. As such, it is critical we maximize the amount of HTTPS requests from mobile routed via the cloud regions to ensure the best possible user experience.
However, if app requests are always routed to the cloud, we risk significant service interruptions during both local- and global-level disruptions. Such connectivity issues can be attributed to various components of the public clouds or the intermediate ISPs. Issues due to DNS service, load balancers, BGP routing, mis-configurations of network middleboxes, cloud outages etc. can lead to DNS or QUIC/ TCP connection timeouts. When disruptions occur, Uber’s platform must have the ability to dynamically failover and reroute incoming requests to our private data centers to ensure uninterrupted service.
The front-end servers hosted in the cloud and data-centers are registered as different domain names. By selecting the most appropriate domain-name, the mobile apps can route requests either through the cloud regions or directly to the Uber data-centers.
Mobile Failover handling
To facilitate highly performant and reliable app experiences for our users, we built an in-house failover handler that resides within the mobile networking stack as an interceptor placed above the core HTTP2/QUIC layers. As HTTPS requests are generated from the application, they pass through the failover handler, that rewrites the domain-name (or host-name) before they are processed by the core HTTP library. This ensures that the HTTPS traffic can be dynamically routed to the appropriate edge servers.
Asynchronously, the failover handler continuously monitors the health of the domains and switches the domain if required based on the errors received from the HTTPS responses. The logic that decides when to switch the domains is the core component of the failover handler, and the main topic of discussion in this article.
The failover handler uses network errors for HTTPS responses as the signal to detect reachability issues with the domain. The fundamental challenge when designing the failover handler was distinguishing between errors on the user’s end due to mobile connectivity failures and errors on our end due to edge infrastructure unavailability or unreachability. This problem is further exacerbated due to the high usage of cellular/ LTE networks for Uber’s applications, especially at global scale. Mobile networks are less reliable and stable than their wired counterparts, prone to intermittent failures, connectivity issues, and congestion.
Receiving temporary DNS errors or QUIC/ TCP connection timeouts for our primary domain (domain-name for the edge servers hosted within cloud regions) does not necessarily mean that it is unavailable; in most cases, this failure is actually due to an intermittent loss in connectivity. Imagine, for instance, going into a tunnel and losing mobile service. In such a scenario, switching the domain from a primary domain to a back-up domain does not help and may result in lower performance once connectivity recovers.
Round robin-based failover handler
A few straight-foward solutions we tested failed to address this challenge effectively. An earlier iteration of our failover handler used a round robin-based system configured with a list of domains. The first domain was the primary domain that provided the best possible performance. The primary domain was followed by back-up domains, typically Uber’s managed data-center servers, to ensure ability to fallback when the primary domain is unavailable. On receiving a specific network error—DNS errors, timeouts, TCP/TLS errors, and so on—the system switched the domain to the next in the list for all subsequent HTTPS requests.
While this round robin solution met our availability requirements, it had a few drawbacks regarding performance:
- Aggressive host switches: A few intermittent network errors cause the system to switch domains. Excessive switching across domains may result in unnecessary DNS lookups and connection setups causing additional delays.
- Substantial requests routed to non-performant domains: In the event of network errors, the system settles on one of the domains in the list with equal probability after the network recovers. We saw significant sessions settle on the lower-performing back-up domains, despite the primary domain being available. The system would only transition back to the primary domain following another round of network errors.
Threshold-based failover handler
To avoid excessive domain switching, we also experimented with a threshold-based failover handler. Instead of triggering failover based on a single network error, the threshold-based solution switches domains only after encountering a minimum number of network errors. However, it proved hard to find a threshold value that worked efficiently across different applications, regions, and network types (LTE, WiFi etc.). Setting the value too low caused unnecessary switching, but setting it too high delayed recovery in scenarios where the primary domains were actually unavailable. Besides, this system did not completely solve the drawbacks of the previous approach.
Edge-driven failover handling
Uber’s edge infrastructure has automated recovery mechanisms to mitigate domain failures, such as DNS re-mapping. In this situation, excessive errors on our primary domain triggers a reconfiguration of the domain-name to IP address mapping for the affected domain. DNS propagation is not instantaneous though, since the revised mapping must propagate across all DNS nameservers globally.
Oftentimes, the unreachability of the primary domain is also limited to a small region, a city, or a specific mobile carrier, and cannot be effectively mitigated by DNS mapping updates alone. Mobile apps have a better context of the connectivity conditions and can react in real-time. Hence, we determined that a device-local failover handler is necessary to ensure connectivity in addition to our edge-driven failover handling mechanisms.
Failover handler design
When designing Uber’s failover handler, we wanted to ensure we hit three main criteria that was lacking in existing solutions we assessed:
- Maximize the usage of primary domains: We needed our failover handling solution to operate in a way to preferentially route traffic to the primary domains, which typically offer the best performance. Maximizing the amount of HTTPS traffic going through these domains ensures lower latency and a better user experience overall.
- Effectively differentiate between network errors and host-level outages: The system required a robust mechanism that could confidently identify actual domain failures and lower the probability of switching to an alternate host because of intermittent mobile network connectivity issues.
- Reduce degraded experience during primary domain outages: Our failover handling system also needed to maximize the usage of back-up domains when primary hosts are either unavailable or unreachable.
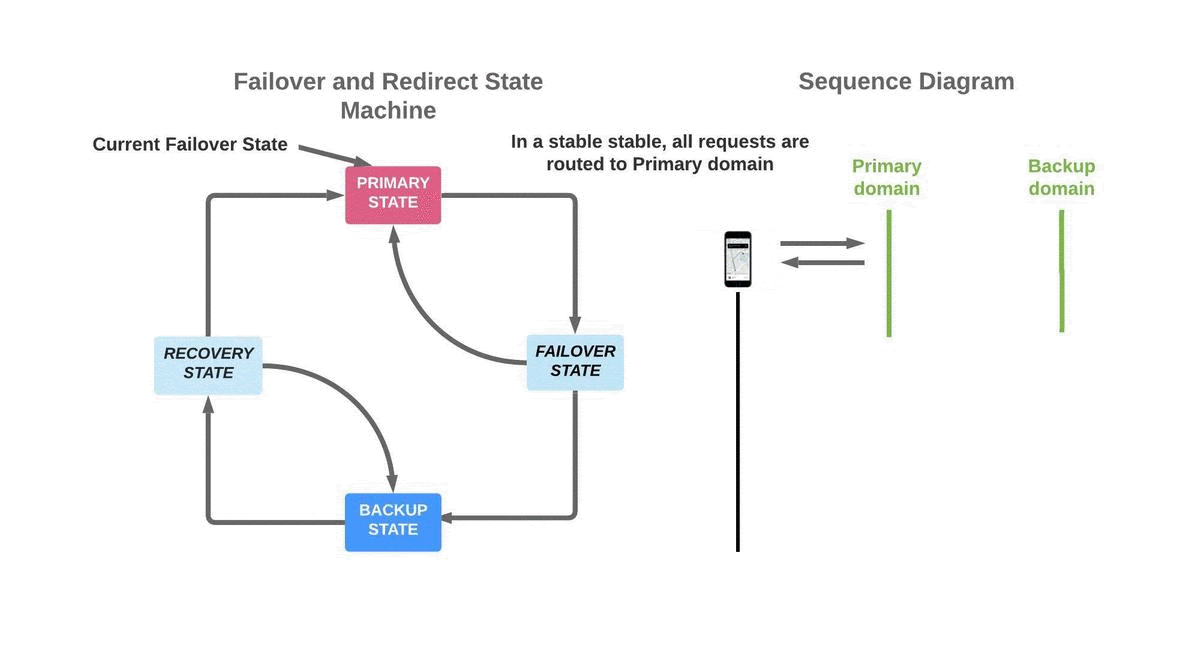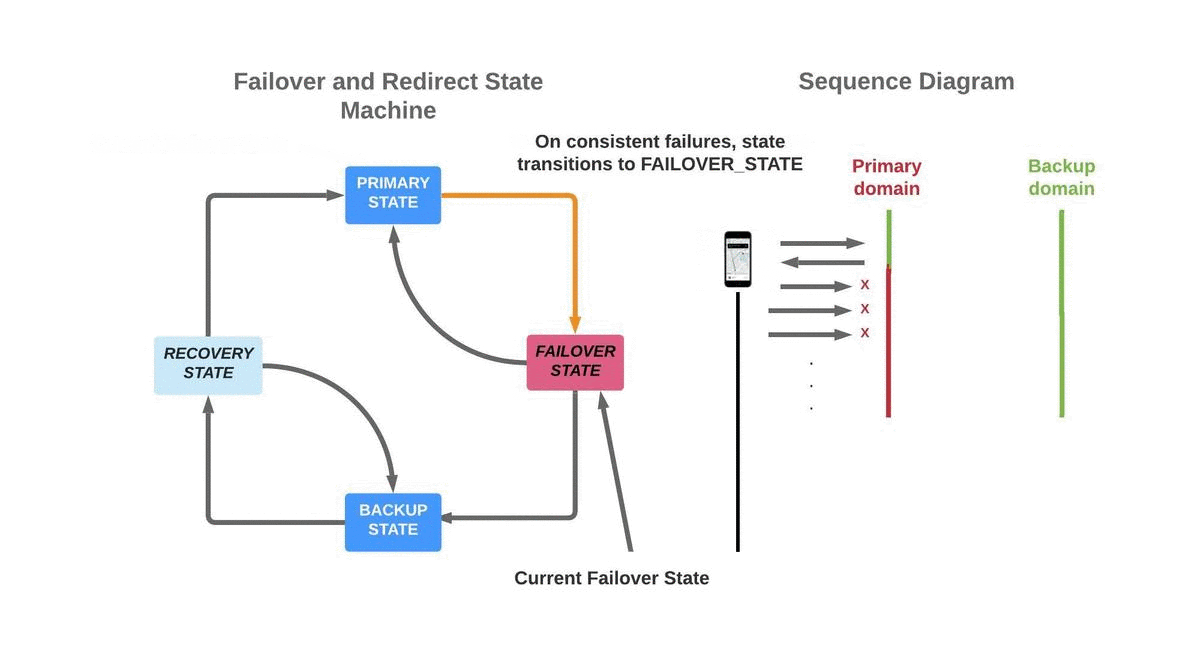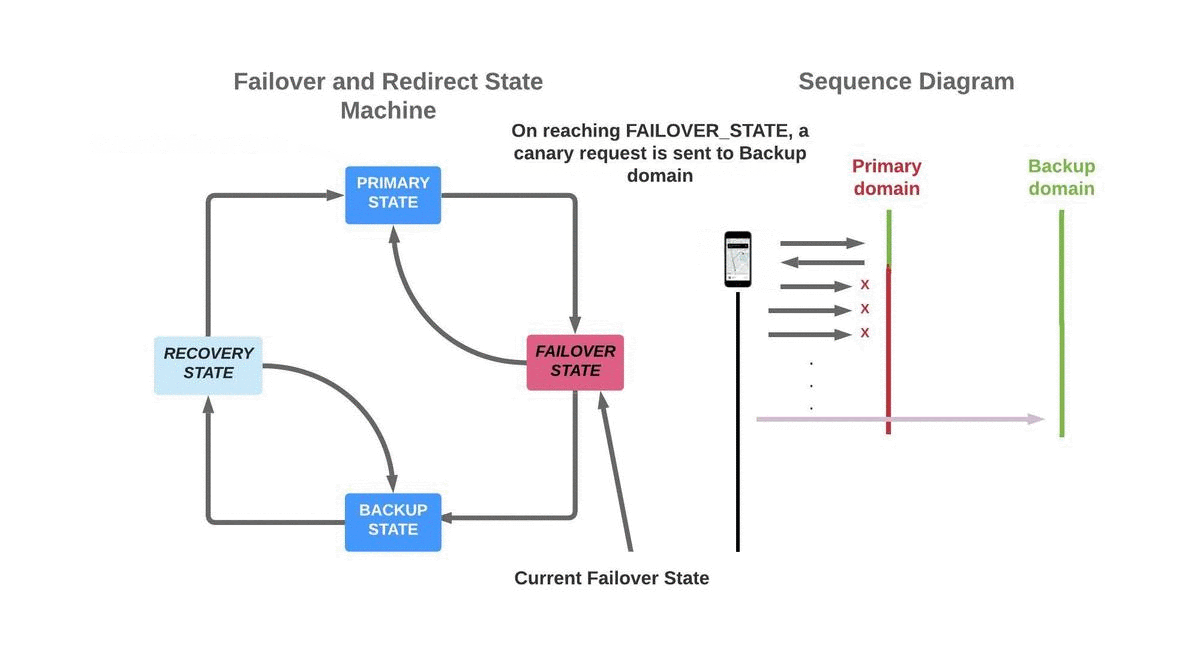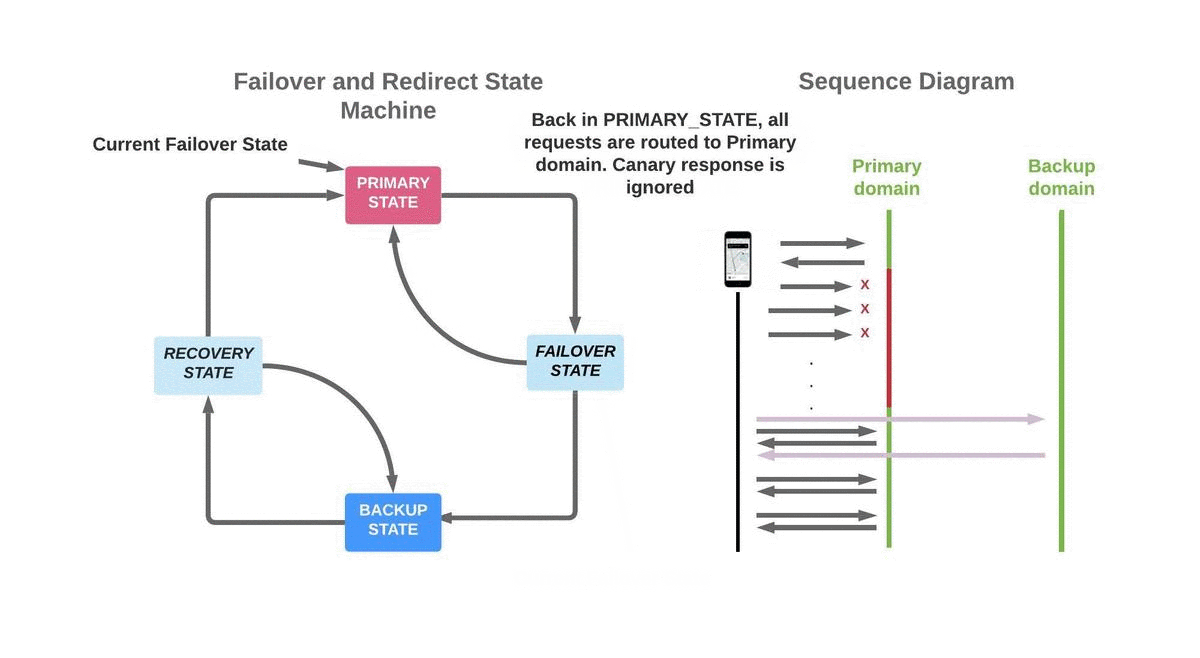
To meet these requirements, we designed our failover handler as a Finite State Machine (FSM) as shown in Figure 2, below:

The system strives to operate in two stable states: PRIMARY_STATE, where the primary domain is used to route HTTPS traffic, and BACKUP_STATE, where one of the back-up domains is used instead. The system strives to always operate in the PRIMARY_STATE, unless there is a possibility of primary domain downtime. Two intermediate states, FAILOVER_STATE and RECOVERY_STATE, ensure transitions from PRIMARY_STATE to BACKUP_STATE (and vice versa) are made with high confidence.
PRIMARY_STATE
PRIMARY_STATE is the default and desired state. In this state, the primary domain is used for all HTTPS requests. If there are no failures, or if there are only a few intermittent failures, no state change occurs. While in this state, continuous failure count is tracked to assist in transitioning to the FAILOVER_STATE. A failure here refers to an error received for a HTTPS response, such as DNS errors, TCP/QUIC connection errors or timeouts.
The FAILOVER_STATE is reached upon meeting a failover condition (i.e., “X” continuous failures over “Y” interval). In this state, all HTTPS requests are still sent over the primary domain. To ensure the system is not sensitive to the value of the thresholds (“X” and “Y”) and to increase the confidence of identifying a domain failure against device connectivity errors, we leverage a canary request. The canary request is a dedicated HTTPS request to the health endpoint (REST API) of the edge server. The canary request is sent over a list of back-up domains, until the first succeeds, at which point the system transitions to the BACKUP_STATE.
While in the FAILOVER_STATE, if a successful response is received from a regular request using the primary domain, the state instead changes back to PRIMARY_STATE. This is likely to occur if the errors on the primary domain were due to connectivity issues in the mobile network. The introduction of the canary request decreases the likelihood of failing over to back-up domains during periods of poor network connectivity.
BACKUP_STATE
If the system instead receives a successful canary response in the FAILOVER_STATE, it transitions to the BACKUP_STATE and starts using a back-up domain for all HTTPS requests. The system will usually reach this state if the primary domain is not available or unreachable for that user session.
While the system operates in the BACKUP_STATE, it is important to continuously check the health of the primary domain in the case that it may have recovered. Hence, in the BACKUP_STATE, the system maintains a recovery timer, transitioning to the RECOVERY_STATE when the timer expires. In the RECOVERY_STATE, a canary request is triggered to the primary domain, while the regular HTTPS traffic is still sent over a back-up domain. If the canary request succeeds indicating that the primary domain has recovered, the system transitions back to the PRIMARY_STATE, routing all traffic back to the primary domain.
When in the BACKUP_STATE, the system also stores the last used back-up domain in a persistent cache that is cleared once transitioning back to PRIMARY_STATE. On app launch, the system reads the domain from this cache if available and starts in the BACKUP_STATE. This ensures we always start from the back-up domain for users that are facing issues with the primary domain in previous sessions. Avoiding the system having to discover the issue on every fresh launch of the app ensures lower latencies and better experience in successive sessions.
Canary requests
One of the key choices we made was the use of canary requests. Our use of canary requests was inspired by the use of health checks that determine the health of the backend instances. By triggering canary requests to back-up domains before switching the regular traffic to the back-up domains, we increase the confidence of the liveliness of the back-up domains when our traffic is facing connectivity issues with the primary domain. In the case that the connectivity issues with the primary domain are due to the mobile networks, the canary to the back-up domains should fail as well.
We had to choose between two options for executing canary requests: sending a request to a dedicated health endpoint or piggybacking on existing application requests as canary requests.
Owing to its relative simplicity, we opted to use the first option. A dedicated canary request allows the system to trigger the canary requests on demand instead of relying on the application requests, avoiding unnecessary delays in triggering canary requests. It also avoids maintaining a whitelist of requests for each application, in case some critical HTTPS requests should not be used as canaries due to strict SLAs. Additionally, it mitigates back-end processing delays, makes it easier to debug the system, and allows for easier optimizations in the future, such as triggering multiple canaries to increase confidence in a domain’s chance of processing the request or to select a specific domain from among several options.
Failover handling in the real world
In the real world, Uber’s applications face a myriad of interesting, but challenging situations. While our first iteration of the failover handler managed most scenarios effectively, we needed to improve upon our initial design to ensure that our system was set up for success.
User enters an elevator or tunnel
Consider a scenario in which a user with good network conditions enters an elevator or tunnel. This is only a temporary disruption of mobile network service, but if the system reacts aggressively and shifts to using back-up domains, the app might experience subpar performance.
In most instances with our failover handler, the state changes to the FAILOVER_STATE, but requests to the primary domain recover before the canary request succeeds on the back-up domain, switching the state back to PRIMARY_STATE. In some scenarios, however, the state did change to BACKUP_STATE due to a race condition where the canary response is received right when the network recovers. Although this case was rare, we tuned the recovery timeout to a small initial value to ensure the system strives to transition back to PRIMARY_STATE as soon as possible.
Primary domain unavailability

In several other instances, our users using specific mobile carriers have faced connectivity errors when the traffic was using the primary domain. While in some carriers, the errors were due to DNS timeouts, in other instances we saw that the errors were attributed to TLS/TCP connection failures. In such cases, it’s hard for us to pin-point exactly the root cause of the problem, whether it’s an issue with the DNS provider, the mobile carrier or the cloud provider, since the intermediate infrastructure is not under our control. However, to provide seamless app experience, our system proved effective in both detecting the failures and successfully transitioning to BACKUP_STATE after the canary request to a back-up domain was returned successfully.
Facing such scenarios, we had to make a few additions to our design. For instance, we had only one condition to trigger a failover to the FAILOVER_STATE when we reach a minimum number of failures in a specific amount of time period. However, in certain situations where our apps were generating a low volume of traffic due to lower user activity, we noticed lag in the trigger of a failover. To solve this case, we added another timeout threshold: after reaching this timeout, the state machine transitions to FAILOVER_STATE without requiring to reach a minimum number of failures.
Primary domain recovery

In addition to connectivity issues limited to smaller regions or carriers, we have encountered several instances of regional outages in the public cloud. Typically, such outages are short-lived, but impacts a significant subset of users during that time. In such scenarios, the system needs to swiftly failover to back-up domains and then reroute to the primary domain as the cloud infrastructure recovers.
If you recall from the design section, our failover handler maintains a recovery timer in the BACKUP_STATE and enters the RECOVERY_STATE on a timed expiration to verify the health of the primary domain. This flow ensures that our mobile apps switch back to primary domain as the cloud infrastructure recovers.
In production, we had to re-evaluate the design of the mechanism to update the value of recovery timeout to ensure consistent performance. If the value of the recovery timeout was lowered, it helped transition back to primary domains faster. However, it caused sub optimal user experience when primary domains were only available intermittently as it resulted in excessive switching between PRIMARY_STATE and BACKUP_STATE. To avoid the excessive switching across states, we linearly increase the value of the recovery timeout with every transition to the BACKUP_STATE. This ensures the system is aggressive in trying the primary domains for the first cycle, but lowers its rate of probing on each subsequent cycle.
Measuring success
We showcase key metrics that prove out the efficacy of the failover handler in meeting our key design goals. To further drive our point on the drawbacks of existing solutions, we compare the performance of our Failover handler (UBER-FH) with the Round-robin based failover handler (RR) that we had explained in a previous section.
Maximize the usage of primary domains
Our first goal was to ensure that we preferentially route our traffic through the public cloud networks to maximize the performance in terms of lower network latencies. Figure 1a shows the distribution of traffic across primary and back-up domains for different failover strategies. UBER-FH routes almost 99% traffic using the Primary domain. However, RR routes more than 20% traffic to back-up domains since it cannot effectively distinguish between mobile network induced errors and actual primary domain outages.

In the case of RR, we witnessed the problem further exacerbates when we persistently cache the back-up domain to ensure that new app launches start with the back-up domain in the case that the primary domain was unreachable. Every time the system makes an error in switching to a back-up domain, it not only penalizes the current session, but subsequent sessions as well.
To quantify the performance impact due to the increased usage of Primary domains, figure 1b shows the percentage reduction in tail-end latencies for HTTPS requests with UBER-FH against RR. While we saw significant gains across all apps for both iOS and Android, we did see higher gains for certain apps. The main reason for the higher gains is that some apps are accessed by highly mobile users who face more intermittent connectivity due to the higher usage of cellular networks.

The performance gains by the increased usage of the primary domain can be attributed to two factors: (i) Closer termination of QUIC or TCP connections improves the performance of the transport protocols over wireless networks and (ii) Increased usage of QUIC since we currently rely on cloud front-end servers for QUIC termination. As seen from Figure 2 below, we saw about a 5-25% increase in the usage of QUIC with the UBER-FH when compared to RR.

Effectively differentiate network errors from domain-outages
The usage of canary requests has significantly helped UBER-FH reliably detect the availability of the domains in the presence of network errors and avoid unnecessary switches to alternative domains. Figure 3 below compares the number of failover events across UBER-FH and RR. A failover event is defined as a single event when the domain used to route traffic is switched from primary to a back-up domain or vice versa. The figure plots the number of failover events across user sessions. Specifically, a rider session is a single trip taken by a rider or an eats session is a single food order placed by an eater. Further, we group the sessions based on the network conditions, i.e., based on the error or failures rates of the HTTPS traffic within those sessions.

As clearly seen from the figure, RR based failover is too reactive in switching domains even during average network conditions that results in a few network errors. In more severe conditions, RR resulted in significant domain switches since it encountered multiple network errors. Instead, UBER-FH proved effective in significantly bringing down the number of failover events even in severe network conditions without compromising on latencies or availability.
We did see a few instances when UBER-FH unnecessarily switches to back-up domains during high network error rates. In such instances, we saw that when the network recovers, the success of the canary request was processed before the success of regular requests, resulting in a transition to BACKUP_STATE. However, such instances are now rare and the failover handler is effective to quickly move back to PRIMARY_STATE after the initial value of the recovery timeout.
Reduce degraded experience during primary domain outages


Fig 4: (left) Graph depicts the distribution of traffic over primary and backup domains for users using 8 carriers in a particular country. (right) Graph plots the error rates for HTTPS requests in the same 8 carriers.
To appreciate the design of UBER-FH, it is important to measure how it works during periods of intermittent unavailability of the primary domain. In a particular instance, we saw a high number of DNS errors at most times for our primary domain for users using a specific carrier (anonymized as c4) in a particular country C. Figure 4 (left) plots the distribution of the traffic using primary and back-up domains for 8 mobile carriers from country C. As seen from the figure, the UBER-FH is effective in ensuring that the traffic falls back to the back-up domains for the carrier c4 that was facing issues with availability of the primary domain. More importantly, our design choices ensured that the user experience did not suffer for users from carrier c4. In figure 4 (right), we plot the error rates across all the carriers during the same time period. Error rate is defined as the number of failed HTTPS requests divided by the total HTTPS requests. Clearly, the error rate for our traffic from carrier c4 is within the range of error rates we see from other carriers in the same country.
Moving forward
Our failover handler has successfully been rolled out to all users on the Uber platform, leading to quicker application response times, and better overall customer experiences. Going forward, we plan to leverage all the learnings and the data from production to further improve the reliability of the system. Specifically, we are evaluating systems that can use historical data to predict performance and reliability across users in a region, network type, carrier to further enhance the decision making at the mobile. With the option to leverage multiple cloud providers, we aim to tackle challenges around using the best cloud provider or in-house infrastructure in real-time on a per user session basis in order to further reduce latencies, while potentially saving costs.
Acknowledgements
We’d like to thank Vinoth Chandar and Jatin Lodhia for their contributions to this project.

Sivabalan Narayanan
Sivabalan Narayanan is a senior software engineer on Uber’s Core Infrastructure team.

Rajesh Mahindra
Rajesh Mahindra is a senior software engineer on Uber's Infrastructure Connectivity team.

Christopher Francis
Christopher Francis is a senior software engineer on the Uber Eats Mobile Platform team.
Posted by Sivabalan Narayanan, Rajesh Mahindra, Christopher Francis
Related articles





Most popular

MySQL At Uber

Adopting Arm at Scale: Bootstrapping Infrastructure

Adopting Arm at Scale: Transitioning to a Multi-Architecture Environment
