
Introduction
Apache Pinot™ is a real-time OLAP database capable of ingesting data from streams like Apache Kafka® and offline data sources like Apache Hive™. At Uber, Pinot has proven to be really versatile in handling a wide spectrum of use cases: from real-time use cases with over one million writes per second, 100+ QPS, and <500 ms latency, to use cases which require low-latency analytics on offline data.
Pinot tables fall in three broad categories: real-time, offline and hybrid. Real-time tables support ingesting data from streams like Kafka, offline tables allow uploading pre-built “segments” via Pinot Controller’s HTTP APIs, and hybrid tables have both real-time and offline parts. Hybrid tables allow a single logical table (same name and schema) to ingest data from real-time streams as well as batch sources.
This article shares how Uber uses Pinot’s offline tables to serve 100+ low-latency analytics use cases spanning all lines of businesses.
Background
Uber has a huge data lake with more than 100 PB of data, and we have been using Presto®, Apache Spark™ and Apache Hive™ since almost a decade to serve many of our internal analytics use-cases. Presto® in particular is quite good at handling use-cases with low QPS (in the low 10s) and latencies on the order of a few seconds. However, there are a lot of use-cases where our users need sub-second p99 latency at a higher QPS. Most users also want dedicated resources for their use-cases to avoid noisy neighbors.
Apache Pinot’s ability to run low-latency queries at high qps, with built-in multi-tenancy and offline data ingestion support, made it a natural fit for serving these use-cases. We have seen this play out over the last few years and Pinot now supports 100+ offline table analytics use-cases at Uber, with 500+ offline tables running in production.
Pinot Offline Table Ingestion Primer
Pinot stores data for its tables in “segments” for both real-time and offline tables. For real-time tables, the data from Kafka is consumed in memory in a “mutable segment” until a threshold is reached, after which the segment is committed to build an “immutable segment.” After the commit is done, a new mutable segment is created to continue consumption from the last read offset.
For offline tables, Pinot allows uploading pre-built immutable segments via a POST /segments API in the Pinot controller. Building segments outside Pinot can be achieved using the “SegmentIndexCreationDriver” and “RecordReader” interfaces. The RecordReader interface allows feeding data to the segment driver from any arbitrary source. The segment driver also allows configuring the indexes and the encodings that should be used for each column.
Once a segment for an Offline table is built outside Pinot, you can create a tarball out of it, upload it to a “deep-store” location, which Pinot servers can access, and hit the POST /segments API in the controller. The controller will create a new segment or update an existing segment’s metadata if one with the same name exists already. It will then send a message to the servers to download and load the segments, making them queryable. The controller also has an API to delete an existing segment, which means that for offline tables you can manage your Pinot data at segment level by adding a new segment, replacing an existing segment, or removing an existing segment.
Self-Serve Platform
Given how segments are built and added/updated/removed, the question is how do we build a self-serve platform to allow 100+ users to create and manage new offline Pinot tables seamlessly?
For this, we leveraged our internal no-code workflow orchestration framework called uWorc. We have a dedicated workflow type for ingesting data from Hive to Pinot. uWorc provides users a UI where they can set their table name, their Apache SparkTM or Presto® query, the indexes they want, etc. It also allows users to configure when a job should run, and has rich support for tracking execution history, which can be used to see the status and logs for each run.
In each pipeline run, we run the SparkSQL or PrestoSQL specified by the users, and the output set of records is added/updated in the table.
Data Modeling
We support two types of offline tables via uWorc:
- Overwrite Tables: When a table is marked as Overwrite, each run of the pipeline will rewrite all of the data for the table completely.
- Append Tables: These tables have “day-based partitions” reminiscent of the datestr-based partitions found in Hive tables. A pipeline run for a given day will either add data for that day, or if it already exists, update data for that day.
Both of these table-types are required to have a “secondsSinceEpoch” column generated in the SparkSQL query, which is used by Pinot for retention purposes.
Ingestion Job
Pinot only allows managing data for offline tables at segment level and the overwrite/append table semantics described above do not natively exist in Pinot. We use our ingestion job instead to implement them.
Our ingestion job is implemented using Marmaray: Uber’s open-source data dispersal framework built on top of Spark. Marmaray supports ingesting data from “any source to any sink.” It does this by providing 3 key SPIs: Source, Sink, and an intermediate data format based on Apache Avro™. We have implemented a PinotSink which can technically ingest from all internally available sources. However, at present we only use it to ingest data from a Hive source.
PinotSink receives a JavaRDD<AvroPayload> from the Source and performs the following steps at a high level:
- Repartition the RDD to meet the number of segments, table-type, and column partitioning requirements. Each Spark partition ultimately corresponds to exactly 1 segment.
- Build and upload the segments to deep-store.
- Make a HTTP POST /segments call to the Pinot Controller to add/update the built segments.
- Remove any segments from Pinot to meet the overwrite/append table-type semantics.
Below we explain how each of the table-types are supported.
Overwrite Tables
Overwrite tables may involve a RDD repartition to meet either the configured “Number of Segments” requirement and/or the “column partitioning” requirement. If we don’t have any column partitioning requirement, then we use a custom Spark Partitioner to randomly distribute records across each Spark partition.
When column partitioning is enabled, we use Murmur2 hash on the configured column to partition the tuples into the required “Number of Segments” partitions. The logic for that is quite simple:

For overwrite tables, we always generate segment names with the format “<table-name>_<spark-partition-number>”. If users decrease their “Number of Segments”, then the subsequent job will produce fewer segments than the one before it. In that case, the subsequent job will delete the extra segments in Pinot to prevent data-duplication.
Append Tables
For append tables, the “Number of Segments” property is used to control the number of segments that should be created for each unique day in the data. For example, if you configure the number of segments as 4, and your ingestion job generates data for the dates “2022-01-01 to 2022-01-05”, then the total number of segments generated by the job would be 20, 4 for each day. This means that we always have to repartition the RDD for append tables since the Source RDD may be arbitrarily partitioned. Moreover, for each date we have to ensure that we generate a preconfigured number of segments.
The Spark Partitioner API allows us to map a tuple to an integer partition ID. So the question is how do we map a record to an integer partition ID to meet the append table semantics?
To achieve this, we use a Spark partitioner that looks like the following:
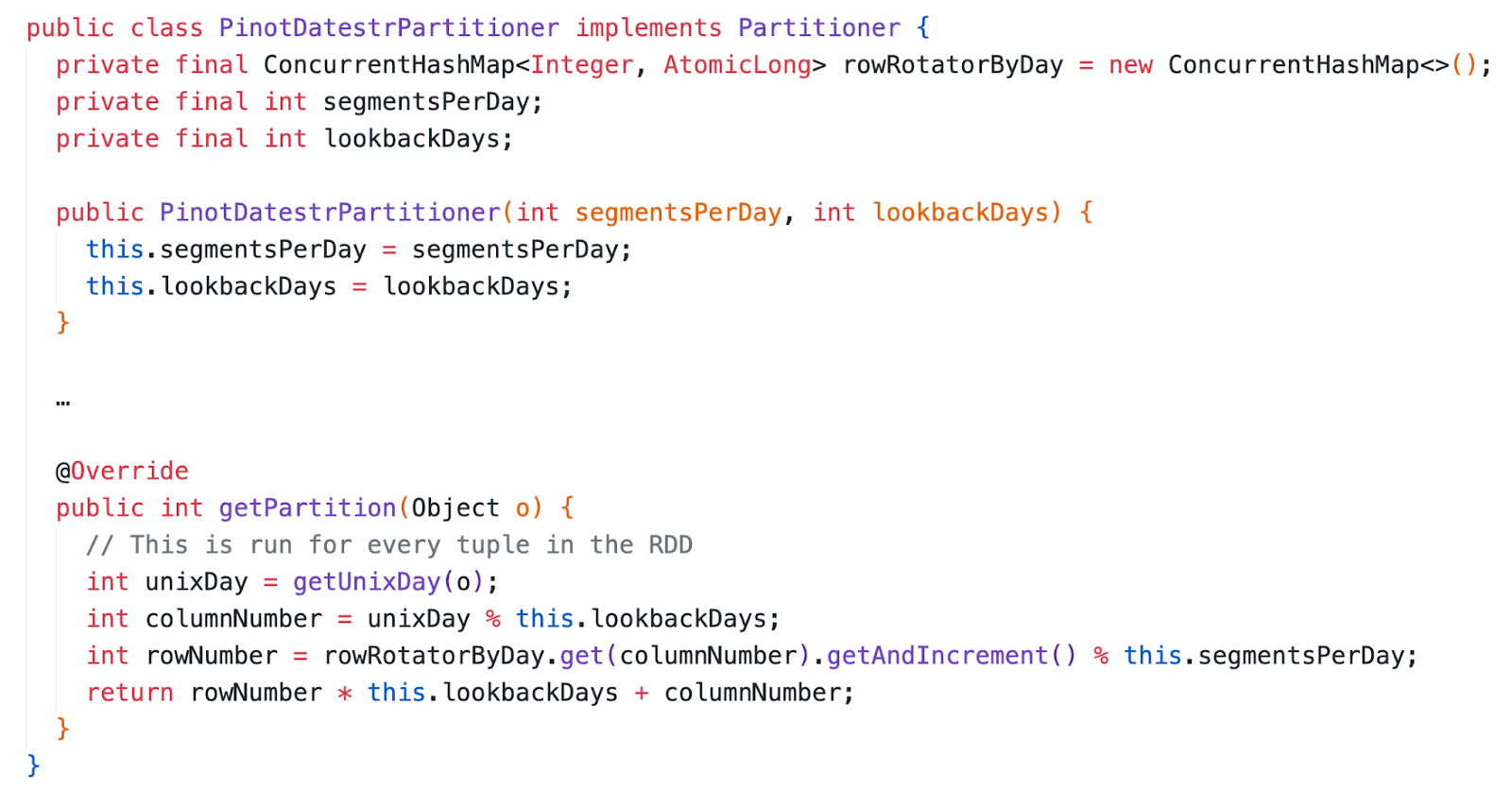
The partitioning is done on the time-column configured by the user. Before calling the partitioner we figure out the “lookbackDays” value, which is the number of days between the smallest and the largest Unix Day in the RDD.
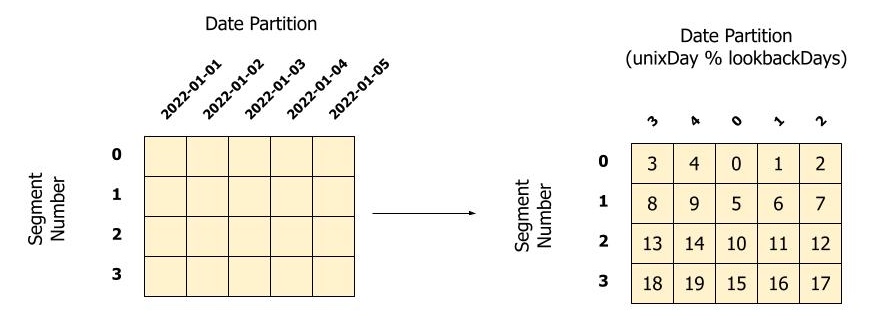
The algorithm can best be understood visually. Say we have lookbackDays = 5 and segmentsPerDay = 4. Saying that a row belongs to a given day and a given segment is equivalent to assigning it to a cell of a lookbackDays x segmentsPerDay grid. This is depicted below. The rows represent segment number, and the columns represent “unixDays % lookbackDays” (i.e., number of days since 1970-01-01).
As can be seen, we end up with a matrix with row and column numbers from [0, 5) and [0, 4) respectively. The example below assumes that 2022-01-03 has a unixDay that is divisible by 5.
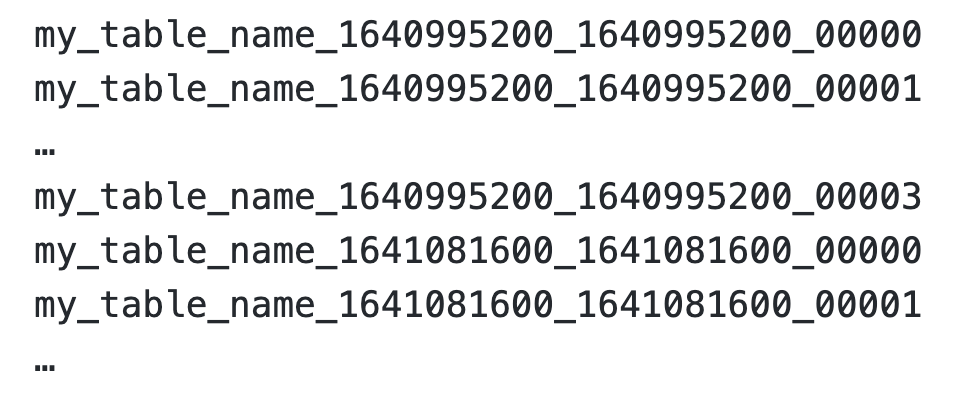
Our pipeline has validations to prevent multiple time-column values for the same Unix day. This is because we want Pinot to apply retention for all segments of a day at the same time, so we can provide the append table semantics consistently. We use the segment name format: “<table-name>_<time-column-value>_<time-column-value>_<sequence-id>”. Here the sequence-ID is an integer between [0, Number of Segments). So for the example above, we will have segments with names as follows:
Finally, we allow users to increase or decrease their number of segments, and the ingestion job can handle deleting extra segments in the Pinot controller as required.
Column Partitioning for Append Tables
We support column partitioning for append tables as well. Everything remains the same as described for append tables above, except for the partitioner, which is augmented as follows:
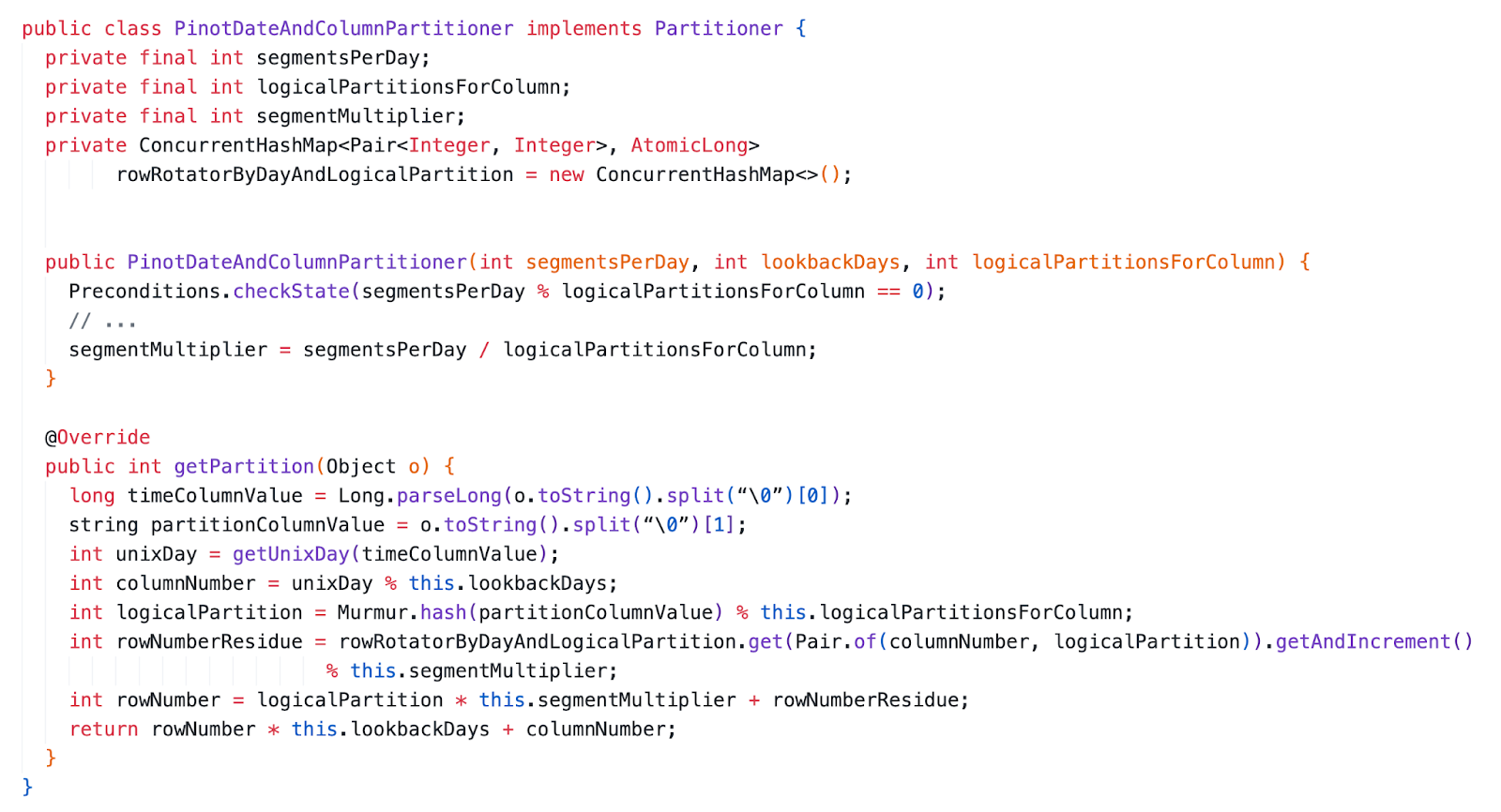
We again reduce it to a problem of assigning a tuple to a Grid. The column number is determined using the Unix Day value and the row number is determined using the hash value of the partitioning column. Additionally, we allow users to keep the number of segments parameter a multiple of the number of logical partitions of the partitioning column, to allow them to tune the segment size without changing the number of partitions.
Advantages of Column Partitioning
In some cases, we have seen column partitioning reduce data volume by as much as 4x. This is because certain datasets really benefit from dictionary encoding when you partition by a key that colocates similar data in the same Spark partition. Column partitioning can also help with segment pruning, which can often really improve query performance.
Spark Data Exports
So far we talked about ingesting data into Pinot from offline sources, but Pinot can also be used to export data from its real-time upsert tables to offline sinks like Hive/Object Stores.
PInot is primarily designed for low-latency analytical queries, which fetch relatively small amounts of data. Uber’s internal usage of Pinot is not different from this paradigm, so we have a 10K limit on the maximum number of rows that can be read from Pinot in a single query. We also keep a close eye on query latency, since our query gateway and query clients are designed around the assumption of short execution time.
That being said, there are scenarios where our users need to extract large amounts of data from their Pinot tables. Even though Pinot tables are not generally considered to be the source of truth, there are setups with advanced ingestion functionality such as “upsert” or “dedup” that make the Pinot table “cleanest” snapshot of the source data. Also, Pinot retention is typically longer than the real-time source (Kafka topic), which makes it handy if you want to extract data for longer time slices.
For such use cases, we utilize Spark and the Spark-Pinot connector to do batch/bulk reads from Pinot.
Spark Pinot Connector
Apache Spark exposes a standard datasource interface for external service providers to implement. Services can implement this interface and gain interoperability with other built-in or extended formats.
Pinot’s open-source codebase contains packages that implement the “read interface” for Spark 2 and Spark 3. Pinot builds also contain two ready-to-use jars, pinot-spark-connector.jar and pinot-spark-3-connector.jar for corresponding Spark versions. Those artifacts can be included into your Spark application as “external-jars” and will provide the ability to use Pinot as a data source. A simple PySpark application that dumps the last days data of a Pinot table to Hive would look like this:

The connector accepts a variety of options that control things like controller address and table name, or advanced configs such as read parallelism and timeout.
Read Model of the Spark Pinot Connector
Spark reader uses Pinot brokers in order to fetch a server-to-segment mapping, however the queries are executed directly on Pinot servers to avoid resource contention. The connector pushes down filters to Pinot in order to minimize unnecessary data movement, however it doesn’t support aggregation push down. This means if an aggregation query is issued, all needed data needs to be downloaded to Spark executors before the aggregation is done on Spark side. This makes the reader suitable for data exports, but not ideal for general analytics, which should be noted.
gRPC Streaming
One noteworthy feature of the connector which we make use of at Uber is the gRPC streaming support.
Pinot servers have two interfaces for fetching data. One is a plain HTTP server and the other one is a gRPC endpoint. The plain HTTP endpoint is the more feature-complete and commonly used one, however the gRPC streaming endpoint has a distinct advantage. When executing a query, the plain HTTP endpoint loads the full resultset into heap before returning it to the caller. However the gRPC endpoint supports “chunking” and only needs to load the next chunk into heap while waiting for the caller to consume the available chunk. This alleviates the memory pressure on Pinot servers, especially for large reads.
Spark reader provides an option to use the gRPC endpoint when fetching data from Pinot. Moreover, when this option is enabled, the connector also uses streaming on Spark side in order to achieve true end-to-end streaming. This means when exporting a table from Pinot to Hive, the pipeline may have already written some chunks to Hive even before the Pinot server has fully processed the local segment.
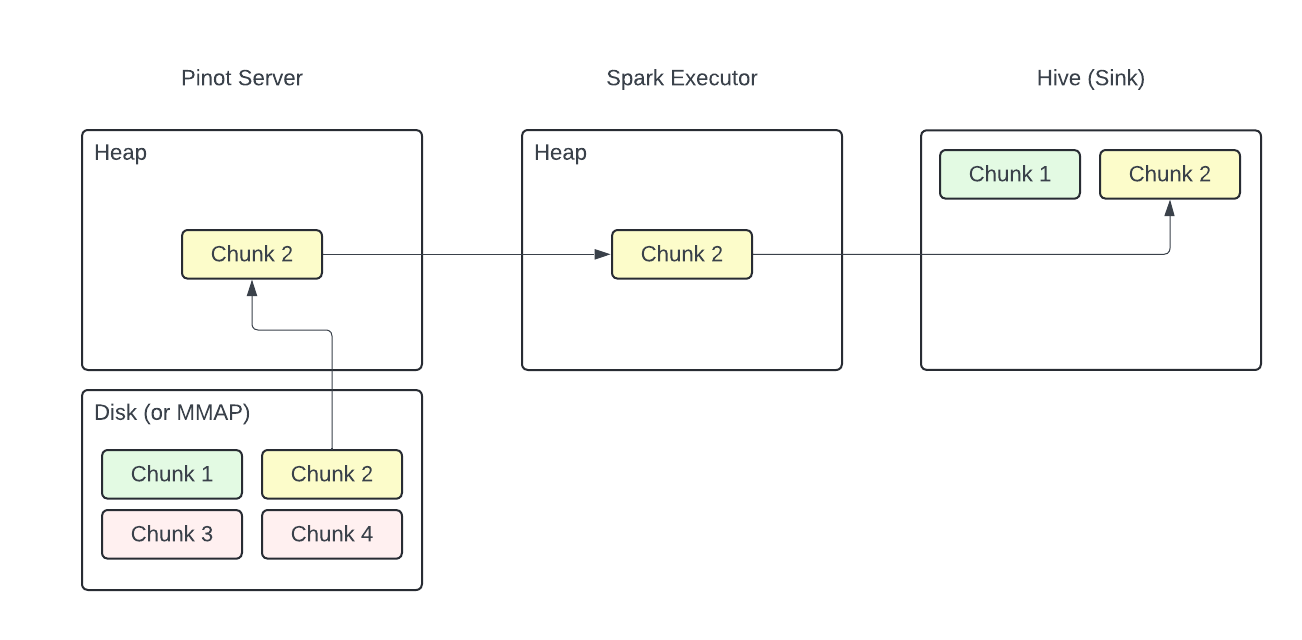
Streaming is critical for export operations that transfer large amounts of data. Non-streaming mode limits per segment export sizes to available memory and either the Pinot server or the Spark executors can quickly run out of resources, failing the pipeline.
Usage at Uber
At Uber, we build a customized version of the connector jar that automatically discovers controller address based on tenant information and injects recommended configurations such as gRPC streaming. As with any Spark application, developers can choose to write their pipelines in Java, Scala, or Python and include the provided jar to enable Pinot read support with little effort. These applications typically cover scenarios like backup or exports.
Expectedly, batch read workflows bring additional load on Pinot servers, which can be detrimental to system performance if not configured correctly. For this reason, we avoid enabling such workloads on shared environments and have some guidelines for users to limit the read parallelism and monitor overall load when onboarding new such pipelines.
In summary, the Spark connector provides a powerful tool for extracting large volumes of data out of Pinot. However it should be noted that it’s not a general analytics solution. It needs to be configured correctly and its impact on cluster performance should be evaluated carefully before productionisation.
Next Steps
Our current ingestion system allows users to write data at a pre-configured cadence, and some of our users have shown interest in on-demand ingestion support. We also have some power users who want to be able to write to Pinot from their own Spark pipelines.
We will continue to explore and build out more integrations to enable even more use cases.
Conclusion
Building an easy-to-use, self-serve platform for ingesting data from batch data sources to Pinot has unlocked a whole new set of use cases at Uber that couldn’t be supported before. Uber has a mature data lake ecosystem with Presto and Spark as its core query engines. Pinot augments this ecosystem, providing users a way to run low-latency analytics use cases on data from their offline sources with ease.
We feel that Pinot’s ability to seamlessly integrate with batch sources, along with its out-of-the-box support for multi-tenancy are severely underrated.
Apache®, Apache Pinot™, Apache Kafka®, Apache SparkTM, Apache AvroTM, Apache Hive™, Pinot™, Kafka®, SparkTM, AvroTM, and Hive™ are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Oracle, Java, MySQL, and NetSuite are registered trademarks of Oracle and/or its affiliates. Other names may be trademarks of their respective owners.
Cover Photo Attribution: “Vineyard 002” by Caliterra is licensed under CC BY-SA 2.0.

Ankit Sultana
Ankit Sultana is a Staff Software Engineer on the Real Time Analytics (RTA) team at Uber, and the technical lead for the RTA query stack.

Caner Balci
Caner is a Software Engineer at Uber’s Real-Time Analytics Team.
Posted by Ankit Sultana, Caner Balci
Related articles



Most popular

The Accounter: Scaling Operational Throughput on Uber’s Stateful Platform

Introducing the Prompt Engineering Toolkit

Serving Millions of Apache Pinot™ Queries with Neutrino

Your guide to NJ TRANSIT’s Access Link Riders’ Choice Pilot 2.0
Products
Company