
Presto at Uber
Uber uses open-source Presto to query nearly every data source, both in motion and at rest. Presto’s versatility empowers us to make intelligent, data-driven business decisions. We operate around 20 Presto clusters spanning over 10,000 nodes across two regions. We have about 12,000 weekly active users running approximately 500,000 queries daily, which read about 100 PB from HDFS. Today, Presto is used to query various data sources like Apache Hive, Apache Pinot, AresDb, MySQL, Elasticsearch, and Apache Kafka, through its extensible data source connectors.

Our selection of cluster types can accommodate any request, whether for interactive or batch purposes. Interactive workloads cater to dashboards/desktop users waiting for the results, and batch workloads are scheduled jobs that run on a predefined schedule. Each of our clusters is classified based on their machine type. Most of our clusters comprise bigger machines, which are equipped with more than 300 GB of heap memory, while other clusters have smaller machines that are equipped with less than 200 GB of heap memory, and we have modified the concurrency of each cluster depending on its size and type of the machines that make it up.
On a weekly basis, memory fragmentation optimization activity is carried out across all production clusters. Even though we were constantly improving fragmentation, we still suffered from constant Full Garbage collections (very long pauses) and sporadically a few out-of-memory errors. Just to give a sense of the problem, let me show you Presto Full GC, cumulative count:
Overview – G1GC Garbage Collector
G1GC is a garbage collector that tries to balance throughput and latency. G1 is a generational garbage collector, which differs from the newer concurrent garbage collectors (Shenandoah, ZGC, etc.). Generational means that the memory is divided into short and long-lived objects.
The first important thing to differentiate here is that there are two types of memory: stack and heap. Stack allocations are cheap because we just need to bump up a pointer, so whenever we call a function we decrement the Stack pointer (stack grows towards the bottom), once we are done with that function we just increment the pointer, and voilà, allocation and deallocation in a single statement each. On the other hand, heap allocation/deallocation is a little bit more expensive. For G1GC, allocation is similar to stack where we only need to bump up a pointer, but deallocation requires GC to run.
In Java, since all objects are allocated on the heap, then what do we allocate on the stack? There it goes, the “pointer” referencing the object on the heap. Then for the heap space, G1 divides it into small sections called “regions.”
G1 tries to achieve at least 2,048 regions on the heap.

What’s the size of each region? It depends on your heap size, but it can go from 1-32 MB. The JVM decides which size ensures that we have 2,048 regions (or more).
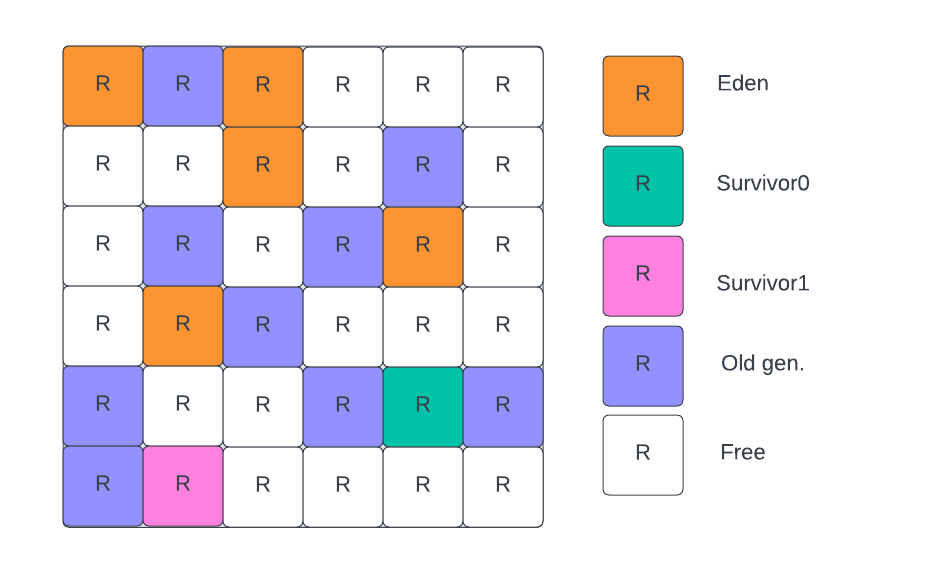
Each region can be the young generation, the old generation, or the free.

Finally, the young generation is also divided into Eden and survivors. Eden is where any new allocation happens. For survivors, it would create two different arenas. Why? Young Gen’s approach to clear memory is copying objects between regions, so it needs an empty survivor to copy memory.
So the full process is whenever we do a new Object(), it gets allocated on the Eden. GC runs and the object is not dead, so it gets copied to Survivor0. The next time GC runs again and the object is still not dead yet, it gets promoted to Survivor1. So it continues to copy back and forth between survivors until it eventually gets promoted to the old generation.
To recap, the young generation uses a copying mechanism to release memory. So when do we allocate to the old generation? There are two scenarios:
- G1 has an age threshold. Every time a young gen object gets copied, we increase the age. Once we hit the threshold, it gets copied to the old gen.
- Each region is 1-32 MB in size. Any object that is 50% or more of the size of the region gets allocated directly to the old generation. G1 calls this a humongous object.
How does G1 clear the old generation? It uses an algorithm called “concurrent mark and sweep.” It is a graph traversal starting from the root objects (thread stacks, global variables, etc.) and goes through every object still referenced. It is essential to mention that G1 uses STAB (snapshot at the beginning), so any new object after it starts would be considered alive regardless of its real liveness. Once it finishes, G1 knows which objects are still alive, and the ones that are not can be cleaned on the following mixed collection.
What? A mixed collection? Indeed. A mixed collection is a young generation collection that would include old generation regions in the process. So it copies the objects that are still alive in another old generation region. This process is critical to reduce memory fragmentation.
Who determines the size of each component (Eden, survivor, old gen, etc.)? The heap is always shrinking and expanding to fulfill its job, although there are certain limits. For instance, the young generation can only be 5-60% of the total heap.
Today’s discussion doesn’t require going into more advanced G1GC topics, so let’s begin with what we have done at Uber.
G1GC at Uber
When Java became more used at Uber, we were using OpenJDK 8. Most of the time, the only tuning option we had to touch was -XX:InitiatingHeapOccupancyPercent=X. This threshold is the one that controls if G1 should start a concurrent mark and sweep cycle.
It has a default value of 45%, which usually causes an increase in CPU, because any service using some cache would eventually exceed that threshold, and it would keep triggering it endlessly. For instance, service A stores all the users in memory, and that causes the Old generation to be ~60% of the total heap. Then the 45% threshold would always be met.
Then how do we tune it?
- Enable GC logs and GC metrics
- Look for the peak old-generation utilization after mixed collections
- Select a value slightly higher than that peak–usually 5-10% higher
However, remember that Presto servers are now running on JDK 11. How do we tune them? This was our first attempt at tuning this version. Why is it different? Java introduced dynamic IHOP (InitiatingHeapOccupancyPercent). Then we no longer have a default value of 45%, and instead we have a value that can change all of the time, and it is only available in the GC logs.
Tuning JDK 11
How does dynamic IHOP get calculated? It uses the current size of the young generation plus a free threshold (basic idea, it uses a slightly more complex formula). This free threshold default value is 10% of the total heap and is used as a buffer to allow GC to complete (remember concurrent mark and sweep runs along your application).
The process we follow is listed below (we waited 1-2 weeks between each step to have enough data to verify our experiments). We tried the following on one cluster first to avoid affecting all our users.
Add more GC metrics
We were missing young- and old-gen utilization, so we couldn’t easily know historical data about our utilizations.
Decrease max young generation size from 60% to 20%
We saw the young generation expanding a few times (50% of the total heap). This caused long GC pauses and concurrent marking to take longer to run again. Concurrent marking can’t run if we are still doing mixed collections.
The result?
- Better GC pauses.
- Still bad concurrent marking. This happened because by decreasing the max size by 40%, we gave that to the old generation, so concurrent marking was still starting late.
Increase Free space from 10% to 35% & decrease Heap waste from 5% to 1%
Let’s first talk about heap waster percentage. This tuning option by default is 5% which tells G1 that it must only release any garbage when it exceeds 5% of the total heap. Why? To avoid long GC pauses during mixed collections. When we do concurrent marking, G1 orders the old generation’s regions based on their utilization, and it first chooses the ones that have more free space, because they are faster to copy to a new region.
For our 300G clusters, that translates to 15G that will never be cleaned. We decided to decrease that to 3G (-XX:G1HeapWastePercent=1) based on past experiences.
For free space, we analyzed several GC logs and noticed that utilization stayed at 20-35% after mixed collections. Then 20% max young gen plus 35% free space would give us a threshold of 45% (100-(35+20)%). With this config, we are giving at least a 10% buffer (35 to 45%) to have some garbage to clean.
The result?
- 1% seemed too much, and we started seeing long pauses of >1s. This change was helpful because, with the GC logs, we could identify that long pauses started to happen once mixed collections tried to go from 2% -> 1% garbage.
- 35% performed well. Full GCs were reduced (~80% for this cluster).
Increase Free space from 35% to 40% & increase Heap waste from 1% to 2%
The result was:
- 2% heap waste gave us an additional 9G and had little impact on latencies (~50-100ms vs. 1-1.5s with 1%).
- 40% performed slightly better than 35%, but we didn’t gain much (85-90% vs. 80%). We decided not to go even further to avoid thrashing.
Try the same tuning options on a different cluster
We tested the same config in a new cluster and verified the behavior before trying on all of them to see the impact. We decided to grab the cluster with the most Full GCs in the past few weeks. After 24 hours of the deployment, we could already see the impact:
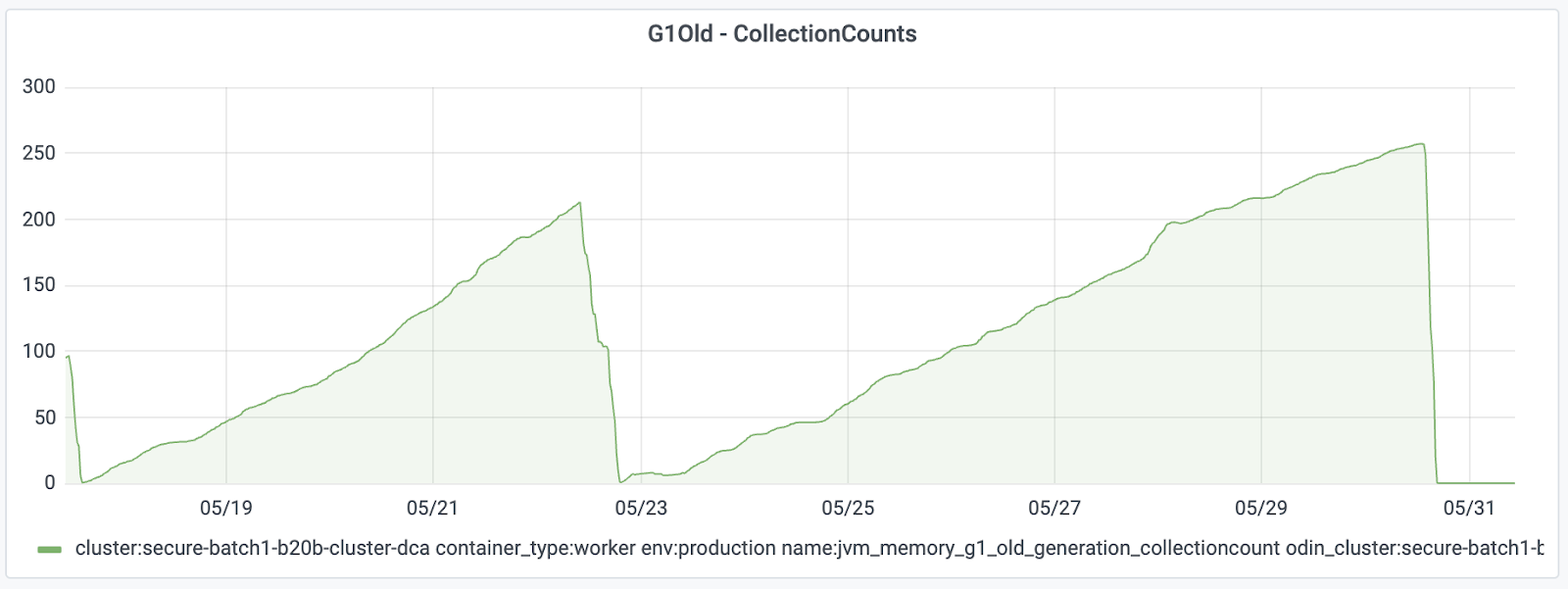
Before, after just a few hours, we used to start seeing Full GCs, but after these changes, we didn’t get any.
Conclusion
After several weeks of testing with the tuning flags presented above, we decided to use the same flags for all clusters. After the flags were added/updated, all the clusters performed optimally with minimal to no internal OOM errors. Due to this change, the reliability of Presto clusters increased, thereby reducing reruns of the queries that were earlier failing with OOM errors, which improved the overall performance of Presto clusters. The flags that we used in the final tuning are:
-XX:+UnlockExperimentalVMOptions
-XX:G1MaxNewSizePercent=20
-XX:G1ReservePercent=40
-XX:G1HeapWastePercent=2
These flags are specific to the Presto use case in Uber, which was finalized after multiple tuning iterations. We expect flags to differ for each organization based on the individual workloads, and they must be tuned on a case-by-case basis. With these flags enabled, we will see more frequent Garbage collection, but they allow us to have a more reliable Presto cluster and reduce the on-call burden for the owners.
For all of our clusters, we observed the following impact:


What’s Next?
Most of the Garbage collection tuning we have done has been on product-facing applications, and we haven’t paid close attention to our storage applications. Therefore, we plan to continue tuning for the other solutions Uber provides. It would be an interesting learning experience because storage applications use large heaps, which differs from what we used to tune normally. We’ll share it with the community once we have more data.
GC tuning done on Presto is an example of how improving garbage collection can improve a system’s overall performance and reliability. Our next focus will be further fine-tuning GCs for Presto clusters, especially with less powerful machines where we are still experiencing some Full GCs, and improving the system’s overall reliability.
All the optimizations listed are specific to the Presto deployment in Uber and can’t be directly ported to other services. The flags listed are just for demonstration purposes to understand what flags we ended up using in our tuning. Also, we will come up with some of the best practices and guidelines that can be used by all of Uber’s storage applications, depending on their general usage, which will act as a good starting point. This will empower us to improve all of our storage applications, improving overall reliability and performance.

Cristian Velazquez
Cristian Velazquez is a Staff Software Engineer on the Maps Production Engineering team at Uber. He works on multiple efficiency initiatives across multiple organizations. He has done several tuning across multiple services and multiple Java versions.

Vineeth Karayil Sekharan
Vineeth Karayil Sekharan is a Senior Software Engineer on Uber’s Data Analytics team. He works on managing Presto and is involved in initiatives like JDK version upgrades and Platform Modernization for Presto.
Posted by Cristian Velazquez, Vineeth Karayil Sekharan
Related articles


Most popular

Uber’s Journey to Ray on Kubernetes: Ray Setup

Case study: how Wellington County enhances mobility options for rural townships

Uber’s Journey to Ray on Kubernetes: Resource Management
