DataMesh: How Uber laid the foundations for the data lake cloud migration
September 10, 2024 / Global
Introduction
Uber’s batch data platform is used by over 10,000 active internal users, ranging from data scientists, city operations, and business analysts to engineers. It hosts around 1.5 exabytes of Apache HadoopⓇ Distributed File System (HDFS) storage across two on-prem regions, serving over 500,000 Presto queries and over 370,000 Apache SparkTM apps daily.
As discussed in our previous post, Modernizing Uber’s Batch Data Infrastructure with Google Cloud Platform, Uber is migrating the batch data platform to the cloud (GCP). Our strategy is to utilize the cloud’s object storage (GCS) for the data lake while transitioning the rest of our data infrastructure to cloud-based Infrastructure as a Service (IaaS).
In the previous blog, Enabling Security for Hadoop Data Lake on Google Cloud Storage, we explored the security considerations of the migration and strategies for bridging the gap between HDFS and GCS security models.
In this blog, we delve into the details of how Uber laid the foundations for the batch data cloud migration by incorporating key data mesh principles.
Motivation
Cloud providers have various limits on storage and IAM policies that pose challenges while migrating batch data to the cloud. Our major considerations while planning the cloud migration were:
- Optimal Data Mapping: Map HDFS files and directories to storage buckets in a Goldilocks manner–not map too much data to too few buckets, thus running into per-project or per-bucket quotas, and not spread the data out to too many buckets to run into the overhead of maintaining too many buckets.
- Access Control: Place access controls at the appropriate level in the storage hierarchy without running into hard limits from the cloud providers, while also not overly elevating privileges for existing users.
Additionally, we also saw the cloud migration as an opportunity to make improvements to our data lake:
- Security group consolidation: Address the issue of proliferation of security groups with overlaps and consolidate users into fewer groups such that per-user access stays the same.
- Decentralized data ownership: Cleanly map Hive DBs and tables belonging to an organization into a bucket belonging to that org, thus leveraging cloud primitives to formalize data mesh principles of data ownership and easier cost attribution.
Today, the “Data team” acts as an intermediary admin and manages access controls for ingested raw datasets. Say someone requests access to a raw table: the Data Ingestion L1 team first asks approval from the owner of this raw table, then grants access to the requestor once approved. With decentralized ownership, this intermediary role can be avoided and the owner can take charge of data access, just like model tables.
- Data governance: Take this opportunity to further improve data governance by mapping data based on its intended usage and lifetime. For example, place well-modeled datasets meant for broad consumption into a bucket with appropriate access control, while placing raw datasets into a bucket which can have reduced access. Place less-business-critical data into separate buckets with appropriate TTL, restricted access, and object lifecycle management policies.
- Automated environment setup: We also wanted to automate setting up our infrastructure, starting with the cloud assets. This enables us to set up and tear down environments easily, thus helping with testing, staging, and production. Additionally this facilitates quickly bootstrapping new data analytics use cases and bringing up the stack in multiple regions for DR.
The cloud migration presented an unique opportunity to address this by incorporating ideas from data mesh principles.
Data Mesh and Corresponding Cloud Concepts
We introduced generic concepts modeled around the data mesh principles, to abstract the cloud constructs and easily adapt it to any chosen cloud provider.
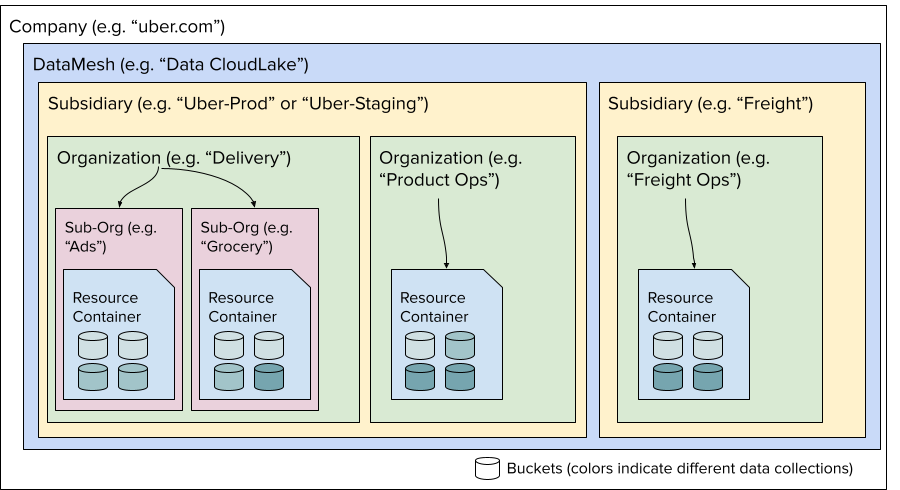
- Domain: A hierarchical unit of organizing all the resources in an organization or team. In data mesh terms, domains can be both at the organization level or at a sub-organization/team level.
- Domain Resources: Cloud providers have resource containers, which are a unit of access control, resource grouping, and cost accounting.
- Data Collection: A logical container for data (DB/tables/files) belonging to the same category (e.g., raw data, tables for internal consumption or modeled tables for external broad access). This may be captured as labels in the corresponding cloud resources.
- Domain Storage: The storage buckets which are a unit of access control, cost accounting, geographic location, storage class (hot, warm, cold), data lifecycle policies (TTL, legal holds, etc.), and data replication (to either standby store or archival store).
- Data Product: A curated, discoverable, and usable representation of data, which includes the Hive tables, BI dashboards, workflow pipelines, etc.

The below figure depicts how the data can be organized to align with the organizational hierarchy via the above constructs modeled around the data mesh principles.
DataMesh Service
We built “DataMesh,” a cloud resources management service that organizes data resources in an organization-centric hierarchical manner. The service allows administration of changes to these resources in a safe and compliant manner, and periodically reconciles the state in the cloud with the desired goal state.
By abstracting away the complexities of managing the underlying infrastructure, the DataMesh service empowers the organizations to take charge and maximize the value of their data, and easily share the data with other teams via well-known interface points.
Architecture
The DataMesh service forms the foundation of Batch DataLake’s cloud control plane. It bootstraps the cloud resources like GCP projects and storage buckets for each organization (domain), sets up bucket IAM and OLM policies, collects the cloud metrics, and pushes them into Uber’s internal framework for monitoring and alerting.
The DataMesh service pulls the organization hierarchy (teams and sub-teams) from Uber’s central ownership repository (uOwn), determines the table ownership, and maps the data to the corresponding organization’s cloud resources. The service also extracts table metadata from uMetadata (an internal repository of the schema, lineage, and business criticality of data) to label the cloud resources (like buckets) with relevant information.
All of this management is automated via reconciliation workflows, which are triggered either by events or time-based schedules. The reconciliation logic ensures that the data is mapped based on its ownership to the right cloud resources and the appropriate security, governance, and lifecycle policies are applied to the cloud resources.

Dashboard/UI
The DataMesh dashboard/UI provides domain administrators with a comprehensive view of their domain’s underlying cloud infrastructure like buckets, quotas, metrics, etc., and their data products (currently focused on Hive databases and tables). While initially designed for domain administrators, we plan to expand the dashboard to include features that are relevant to users to discover data and for the domain admins to manage the infra in a self-service manner.
Simplifying the migration and future-proofing the system
One of our migration goals was to make the migration less painful for our users. There are over 100,000 user workflows and millions of lines of user code in the Uber’s Batch Data platform.
Many of the workflows and the underlying Spark applications have hard-coded HDFS paths in the code and configs. Asking users to update their code would have slowed down the overall migration process. Instead, we built an automated path translation logic to map the on-prem paths to cloud-based paths.
The DataMesh service captures the on-prem path to bucket path mapping as a part of the migration in a “Path Translation Service” (PTS). The PTS is looked up at runtime by the storage clients to automatically rewrite the on-prem paths to its corresponding cloud destination. Watch out for a future blog post detailing how we handled the hard-coded paths that we encountered in our jobs and pipelines as many companies accumulate these over time!
To future-proof the system and make it cloud-agnostic, one of our principles was to NOT leak the bucket paths in the user code or pipelines going forward. The data may need to be moved across buckets due to various reasons (e.g., ownership changes, compliance requirements, changing data access patterns, new cloud provider features, etc.).
We created a new “logical file system” to abstract the bucket paths, and have consistent naming across cloud providers.
Challenges
Ownership changes
The DataMesh service organizes both cloud resources and data assets based on their ownership. For newly created assets (tables), if the ownership is not explicitly provided at creation time, the service uses various heuristics like the bucket location of the data, the organization of the asset creator, etc., to determine the ownership.
However the ownership of the assets can change due to users explicitly re-assigning the asset’s ownership or team reorgs, necessitating remapping the assets or moving the data to the target org’s cloud resources.
We have implemented an automated process that continuously monitors ownership changes and performs remapping in the background.
To minimize the data movement, the service re-labels the assets and/or moves GCP projects to the parent folder of target org whenever possible. For cross-bucket transfers, we leverage the GCP Storage Transfer Service, which optimizes for metadata-only copies when source and destination storage classes match.
Cloud provider limits and quotas
GCS imposes various limits and quotas. Our service considers these constraints while mapping the data into the GCP Projects and buckets for optimal distribution.
For example, to avoid hitting GCS read/write IOPS throttling, heavily-used tables (identified through metrics) are placed in separate buckets. This not only improves performance, but also provides readily available GCS metrics for those tables in the GCS dashboard for easier troubleshooting.
Resource usage attribution and cost control
On-premises, we leverage HDFS directory quotas and custom monitoring to manage the data usage. However, GCS lacks native mechanisms for setting object storage quotas. To bridge the gap, we built a system for organization admins to monitor usage (cost, bytes, operations, egress, etc.) at the org, bucket, and table levels, and optionally set storage quotas. This ensures storage costs align with organizational targets. The system continuously monitors GCS resource usage and takes action like sending notifications and blocking access when limits are exceeded.
Next steps
We want to continue to build up on the principles of datamesh and empower data owners and users by creating a “data domains” platform where:
Data is self-governed: Users logically organize data, metadata and related artifacts (code/pipeline, notebooks, etc.) into domains that align with the ownership boundaries.
Infrastructure management is simplified: Enable capability to manage the cloud infrastructure for data processing in a self-serve manner. Automatically optimize the infrastructure to drive efficiency and cost savings.
Data Governance becomes intuitive: Leverage capabilities available in different Uber services and tools like Databook, build the missing features and integrate it into a single pane of glass view for managing all aspects of data in the cloud.
Conclusion
Uber’s cloud migration of its exabyte-scale batch data platform involves multiple teams, and challenges stemming from a legacy on-premises stack.
By building the DataMesh service, we were able to deliver the following key wins:
- Simplified Cloud Resource Management: Abstracted away the complexities of cloud infrastructure, automating resource provisioning, configuration, and management.
- Optimized Data Placement: Optimally mapped data to buckets, navigating various GCS quota limits and ensuring performance parity with HDFS.
- Ownership: Organized data based on ownership, streamlining cost attribution, simplifying quota management, and fostering decentralized data ownership.
By embracing Data Mesh principles, we not only aim to streamline the migration, but also establish a foundation for a more agile, secure, and cost-effective data ecosystem.
We hope that by sharing our experiences and learnings, we can inspire and guide other organizations embarking on similar cloud migrations. We’re excited to continue innovating in this space, and look forward to sharing more insights, execution progress and the lessons learned in the future blog posts.
Acknowledgments
We are really grateful for the invaluable contributions of the DataMesh team members Charles Huang, Bugra Cavdar, and Yue Peng. Their dedication has been instrumental in the success of this initiative. We would also like to thank Mithun “Matt” Mathew for his insightful review and feedback for this blog.
Apache®, Apache HadoopⓇ, Apache Parquet™, Apache Hudi™, Apache Spark™, Apache Hadoop YARN™ are registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Oracle, Java, MySQL, and NetSuite are registered trademarks of Oracle and/or its affiliates. Other names may be trademarks of their respective owners.
The Grafana Labs Marks are trademarks of Grafana Labs, and are used with Grafana Labs’ permission. We are not affiliated with, endorsed or sponsored by Grafana Labs or its affiliates.Cover Photo Attribution: “Biosphere Environmental Museum” by vmokry is licensed under CC0 1.0.

Arun Mahadeva Iyer
Arun Mahadeva Iyer is a Sr. Staff Engineer in the Uber’s Data Platform team. He is currently working on re-architecting Uber's Data Platform on the Cloud.

Abhi Khune
Abhi Khune is a Principal Engineer on Uber’s Data Platform team. For the past 6 months, Abhi has been leading the technical strategy to modernize Uber’s Data Platform to a Cloud-based architecture.

Sahana Bhat
Sahana Bhat is a Sr. Software Engineer in the Uber’s Data Platform team in Bangalore. She has worked on building the DataMesh service and is currently driving the migration of batch data workloads to Cloud.
Posted by Arun Mahadeva Iyer, Abhi Khune, Sahana Bhat
Related articles



Most popular

How medical schools support the next generation of doctors with Uber

Uber’s Journey to Ray on Kubernetes: Ray Setup

How Uber Uses Ray® to Optimize the Rides Business
