Serving Millions of Apache Pinot™ Queries with Neutrino
December 11, 2024 / Global
Introduction
Apache Pinot™ is a real-time OLAP database capable of ingesting data from real-time streams and offline data sources. Uber has used Pinot for over 6 years, and in that time we’ve seen a rapid increase in its adoption. Today, Pinot handles a wide spectrum of use cases at Uber, from real-time use cases with over 1 million writes per second, 100 QPS, and less than 500 ms latency, to use cases that require low-latency analytics on offline data.
In this blog, we share how our platform users leverage Neutrino, an internal fork of Presto®, to query their data in Pinot.
Throughout this blog, queries refer to read queries, because in Pinot we usually refer to writes as ingestion.
Background
Pinot can be queried using SQL, but it has two query engines: the V1 Engine and the more recent Multistage Engine. As of this writing, Pinot’s V1 Engine is the default engine, and the Multistage Engine has to be explicitly configured for use.
Pinot’s V1 Engine can handle higher QPS at a much lower latency when compared with the Pinot Multistage Engine. The tradeoff is that SQL features are quite limited with the V1 engine. Presto is a stateless query engine capable of reading from many different data sources via its connector architecture.
Pinot’s V1 Query Engine
Pinot’s V1 Engine is optimized for high QPS and low latency. The engine has a scatter-gather execution and it only supports queries with a single SELECT, WHERE, GROUP BY, and ORDER BY clause. In other words, it doesn’t support sub-queries, joins, or window functions. The engine has a custom planner that handles specific query shapes with custom operators. For example, a SELECT query without ORDER BY uses a SelectionOnlyOperator, whereas one with an ORDER BY uses a SelectionOrderByOperator.
Figure 1 shows a high-level design of Pinot query execution in the V1 query engine. Pinot brokers receive HTTP requests from clients, which are scattered to the servers that ingest and store the data. The results are sent back to the broker, which performs a reduce before sending it back to the client.

Pinot’s Multistage Query Engine
Pinot’s Multistage Engine was made generally available in 2023 with Pinot 1.0, and it supports distributed joins, window functions, and sub-queries. It uses Apache Calcite™ to create a logical plan, which is then used to derive the physical plan. The plan may consist of multiple stages, and data transfer between each stage may incur a shuffle. The entirety of the plan, except for the penultimate stage or two, is run on the servers.
Figure 2, taken from the Apache Pinot documentation, shows the execution model.
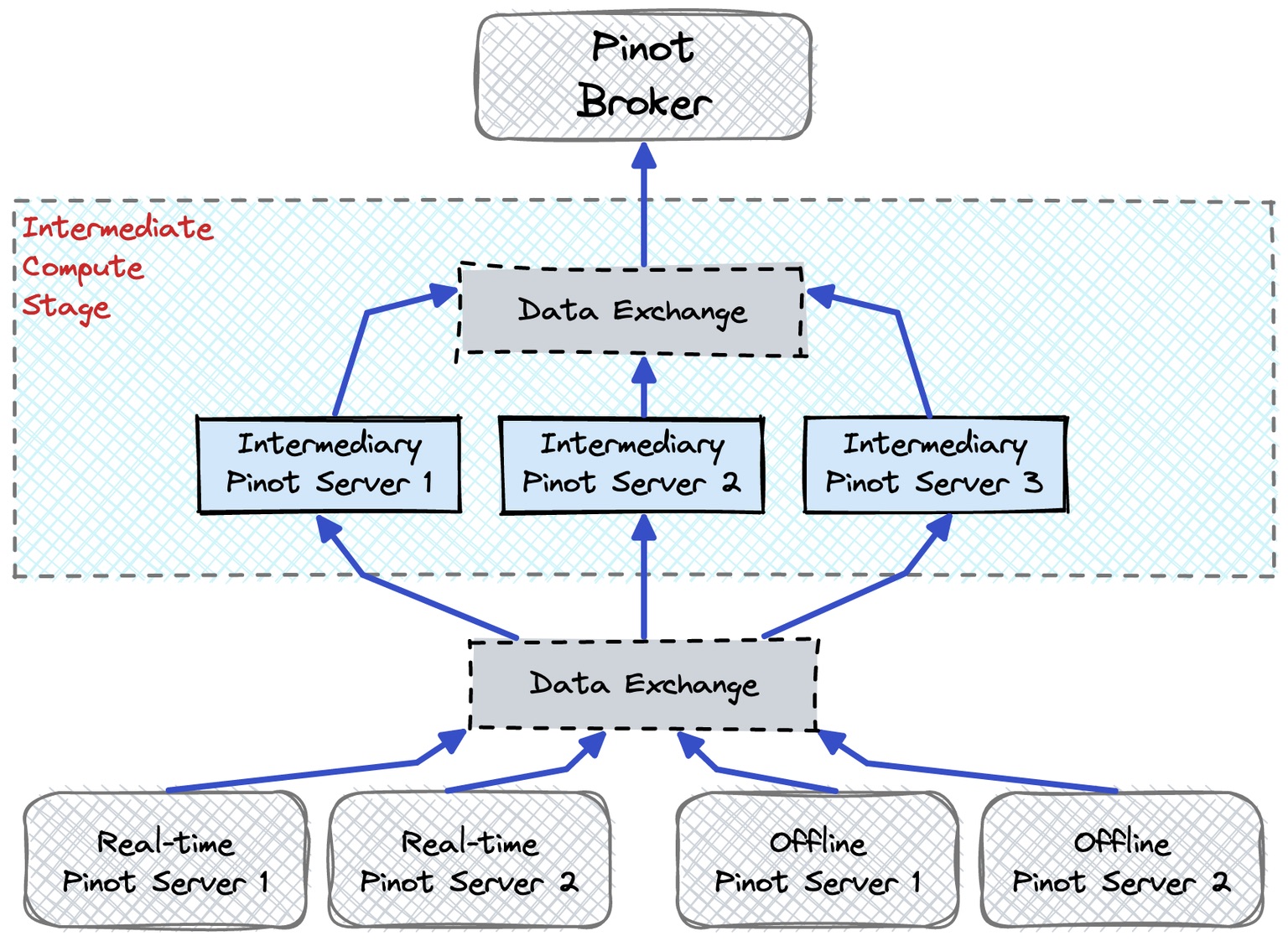
When a Multistage Engine query is submitted to the brokers, the broker uses Calcite to create and optimize a logical plan, which is converted to a physical plan that’s dispatched to the servers for execution. The servers execute their assigned stages, shuffling data between them if required. The last stage in each server sends the data back to the broker, where a final reduce runs.
Presto
Presto is a stateless query engine designed for interactive analytics use cases. It has its own SQL dialect called PrestoSQL. Presto’s connector architecture allows it to query any data source: be it a distributed storage system like object-stores/HDFS, where the table layout may be defined via something like the Apache Hive Metastore, or SQL databases like MySQL and Apache Pinot. Presto supports joins, sub-queries, and arbitrarily complex queries.
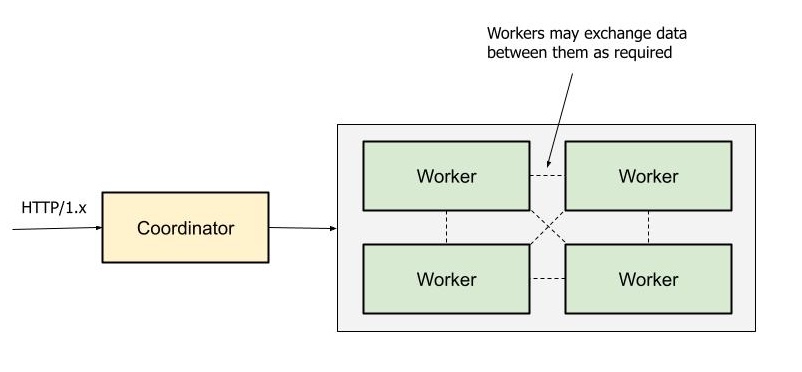
A Presto deployment consists of a coordinator, which accepts the queries and returns the results, and many stateless workers which execute the query by running all the operators.
Typically, a Presto cluster runs queries at less than 50 QPS, with latencies on the order of a few seconds to up to several minutes. Figure 3 shows Presto’s execution at a high level. Presto’s coordinator receives queries from clients via an HTTP request, compiles and plans the query, and dispatches the plan to the workers. The workers execute the query, exchanging data between them as required.
Presto allows connectors to alter the query plan and read and write to any data source. Connectors can implement the ConnectorPageSourceProvider, which Presto calls in the table scan operator to read data. They can also implement the ConnectorPageSinkProvider if they want to write the query output using a custom mechanism.
Leveraging Neutrino
Neutrino is an Uber-internal fork of Presto that’s capable of running queries at over 10,000 QPS with sub-second latencies. Neutrino currently proxies Pinot queries for roughly 95% of our use cases. But as the following sections show, it isn’t just a proxy, but also a query execution engine running logically on top of the Pinot V1 Engine.
Design
With Neutrino, we’ve optimized Presto for high QPS and low latency. Neutrino runs the coordinator and the worker in a single JVM, and the HTTP calls between the worker and the coordinator are bypassed in favor of method calls. We achieved this by making internal changes that required tweaking Presto’s execution engine in several places.
We also have an internal fork of the Presto-Pinot Connector Optimizer to support query pushdown. Presto SQL submitted by a user goes through the logical planner and a bunch of optimizers, which are common for all connectors. After all the common optimizers run, Presto runs the specific connector optimizer relevant to the query. In our case, our internal fork of the Presto-Pinot Connector Optimizer runs. At a high level, the optimizer tries to find the maximal sub-plan that can be pushed down to Pinot, and converts it into a table scan node with a generated Pinot query.
Multistage Execution via Neutrino and the Pinot V1 Engine
To better understand the design described above, consider the Neutrino query in Figure 4, which tries to mimic an Uber-themed use case.

Here we’re trying to compute the total trip amount at the line-item level over a period of time. However, the original real-time stream may have multiple entries for the same line item and trip, as amounts can change later due to various reasons (like a rider adjusting the tip amount). We can’t use Pinot upserts because it would lead to too many primary keys.
The query leverages window functions to keep the latest amount for each line item and is essentially deduping rows at query time, with the deduplication key being trip_id, line_item.
Figure 5 shows the query plan in Neutrino for this query. The table scan is executed by sending the SQL query to the Pinot broker.

Neutrino pushes down a SQL query to Pinot that Pinot’s V1 Engine can run, and executes the rest of the plan within itself using its own execution engine. This design achieves something remarkable:
- We can support complex query shapes that couldn’t be supported with Pinot’s V1 Engine like window functions and sub-queries
- We can run such queries at hundreds of QPS with very minimal hardware, without requiring any user hints for query optimization
One may wonder why we don’t use the Pinot MSE for this, as the MSE can support arbitrarily complex queries. There are a few reasons for this:
- MSE by default resorts to shuffles, which don’t scale well. Neutrino, on the other hand, executes the entire plan using a single thread.
- Our internal testing suggests MSE can’t scale to 100 QPS. However, queries like the above may need to be run at over 500 QPS.
- MSE only became generally available recently, and queries such as the one above have been running reliably in Neutrino for years.
Rate Limiting at the Routing Layer
Our internal load balancing system, dubbed Muttley, provides a way to configure the QPS for each caller. If a caller exceeds their set QPS, then Muttley starts dropping requests before they reach the target service.
We use this extensively in Neutrino to shield it from QPS spikes from our over 100 unique callers.
Query Fingerprinting and Validation Framework
We’ve added a simple mechanism to compute query fingerprints in Neutrino. Given Pinot is primarily used for powering end-user-facing applications, most of our traffic is from back-end services, which have a predetermined query fingerprint. So, the number of unique query fingerprints is multiple orders of magnitude lower than the total QPS, and is also a very effective dimension for identifying expensive queries.
Furthermore, we use Flipr, Uber’s dynamic config store, to configure a deny list of fingerprints. This is quite useful to mitigate rare scenarios where one query may impact other callers.
Dynamic Split Execution Timeouts
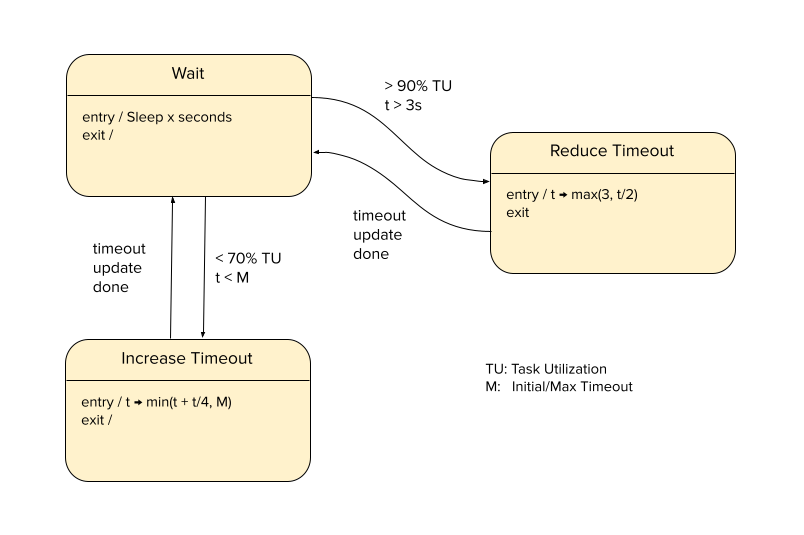
Three years back, we had a couple of incidents due to one user overwhelming our Neutrino deployment, causing impact to other high-tier callers. The issue essentially was: if a given caller running at a sufficiently high QPS experiences high latencies, it leads to a pile-up of requests and threads in Neutrino. At the time, we wanted to keep the number of internal changes in our fork as low as possible, because we wanted to keep in sync with Presto’s main branch and move our fork ahead every few months.
We wanted to solve this problem quickly and with minimal surgical intervention to Presto’s core code. To achieve this, we built a simple mechanism that dynamically adjusted Pinot’s query timeout in case of high load. Even to our surprise, this simple mechanism, combined with our routing-layer-based rate limits, has served us well over the past 3 years with no repeat of such incidents.
Historical Context
One may wonder why we didn’t directly expose PinotSQL to users and build a simple passthrough proxy. The reasons for going with the Neutrino approach are that at the time, Uber had two OLAP databases: AresDB and Pinot. Using Presto, we could hide the complexity of dealing with different query languages across these two stores. Beyond that, using Presto, we could enable multistage queries, which weren’t available in Pinot at the time (2019).
Challenges
We have faced a few challenges working with Neutrino over the years.
First, Neutrino is a complex system for users. Neutrino, as part of its design, has to do SQL-to-SQL translation. Moreover, it can only partially push down the query plan to Pinot. Naturally, the response returned by Pinot has to be trimmed at a certain limit, and since we send a SQL query to Pinot, the limit has to be enforced using the LIMIT clause.
The pushed-down plan may not always have a limit, and Neutrino may need to put a default limit of its own in such cases (or fail the query). Putting a default limit of our own changes the semantics of the query and can lead to incorrect results, while failing the query will lead to a poor experience for users. This is also demonstrated in the example in Figure 5, where we add a default limit of 10,000.
Additionally, a visual inspection of the query isn’t enough to determine how the pushed-down query looks, and changing a single UDF could lead to a complete change in the pushed-down query.
The second challenge was a lack of join support. Neutrino doesn’t support joins, and can only support queries whose unoptimized plan-tree has no node with a greater than one child node.
The Multistage Engine in Pinot enables distributed join queries, but since Neutrino can only translate to Pinot V1 Engine queries, we’re unable to take advantage of the Multistage Engine with Neutrino. This also put us in a position where our current tech stack didn’t align with the next-generation query engine in Pinot.
The third challenge was breaking tenant isolation. Neutrino proxies traffic from over 100 callers, many of which may be hitting their dedicated Pinot tenants. So, Neutrino ends up becoming a shared resource and breaks tenant-level isolation at the query level.
The last challenge was development overhead. We’ve spent significant effort over the last 2-3 years fixing a ton of query translation issues and improving support for query pushdown. However, Pinot continues to improve rapidly still, and catching up to the new SQL features in Pinot (even new Pinot UDFs) requires a corresponding change in Neutrino. This often becomes a bottleneck for users trying to leverage these new features.
Scale and Impact
Neutrino is a business-critical, tier-0 service at Uber, and serves more than half a billion Apache Pinot queries daily. Our estimates suggest that more than a third of those queries leverage Neutrino’s execution engine, i.e. they only partially push down the query and execute the rest of the plan within Neutrino.
With over 100 unique service callers querying over 1,000 tables, Neutrino and Apache Pinot easily serve 100 use cases across all our lines of business.
Next Steps
Currently, we only serve a handful of use cases via the Pinot Multistage Engine at Uber. In a subsequent blog, we’ll share how we plan to adopt Pinot SQL at Uber more broadly, and how we plan to address the challenges with our Neutrino-based approach.
Conclusion
Our experience at Uber of serving hundreds of low-latency analytics use cases has made it clear that OLAP systems should be able to support query features such as window functions and sub-queries. Apache Pinot didn’t have this support until 2023, and Neutrino has proven to be immensely useful in bridging that gap. Moreover, Neutrino’s approach of running the entire plan within a single process has proven to be scalable enough to handle 10,000 QPS reliably.
Apache®, Apache Pinot™, Apache Hive™, Apache Calcite™, Pinot, and Hive are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Oracle, Java, MySQL are registered trademarks of Oracle and/or its affiliates. Other names may be trademarks of their respective owners.
Presto® is a registered trademark of LF Projects, LLC.
Cover Photo Attribution: “Let Sparks Fly” by mightyboybrian is licensed under CC BY-NC 2.0.
Copyright Apache Pinot. Licensed to the Apache Software Foundation (ASF) under one or more contributor license agreements under the Apache License, Version 2.0.

Ankit Sultana
Ankit Sultana is a PMC Member for Apache Pinot and a Staff Engineer at Uber.

Pratik Tibrewal
Pratik Tibrewal is a Senior Software Engineer at Uber.

Christina Li
Christina is a Senior Software Engineer on the Real-Time Analytics team at Uber. Her work focuses on the Pinot query stack.

Shreyaa Sharma
Shreyaa Sharma is a Software Engineer II at Uber.

Ujwala Tulshigiri
Ujwala Tulshigiri is a Sr Engineering Manager on the Real-Time Analytics team within the Uber Data Org. She leads a team that builds a self-served, reliable, and scalable real-time analytics platform based on Apache Pinot to power various business-critical use cases and real-time dashboards at Uber.
Posted by Ankit Sultana, Pratik Tibrewal, Christina Li, Shreyaa Sharma, Ujwala Tulshigiri