From Predictive to Generative – How Michelangelo Accelerates Uber’s AI Journey
May 2, 2024 / GlobalIntroduction
In the past few years, the Machine learning (ML) adoption and impact at Uber have accelerated across all business lines. Today, ML plays a key role in Uber’s business, being used to make business-critical decisions like ETA, rider-driver matching, Eats homefeed ranking, and fraud detection.
As Uber’s centralized ML platform, Michelangelo has been instrumental in driving Uber’s ML evolution since it was first introduced in 2016. It offers a set of comprehensive features that cover the end-to-end ML lifecycle, empowering Uber’s ML practitioners to develop and productize high-quality ML applications at scale. Currently, approximately 400 active ML projects are managed on Michelangelo, with over 20K model training jobs monthly. There are more than 5K models in production, serving 10 million real-time predictions per second at peak.
As shown in Figure 1 below, ML developer experience is an important multiplier that enables developers to deliver real-world business impact. By leveraging Michelangelo, Uber’s ML use cases have grown from simple tree models to advanced deep learning models, and ultimately, to the latest Generative AI. In this blog, we present the evolution of Michelangelo in the past eight years with a focus on the continuous enhancement of the ML developer experience at Uber.
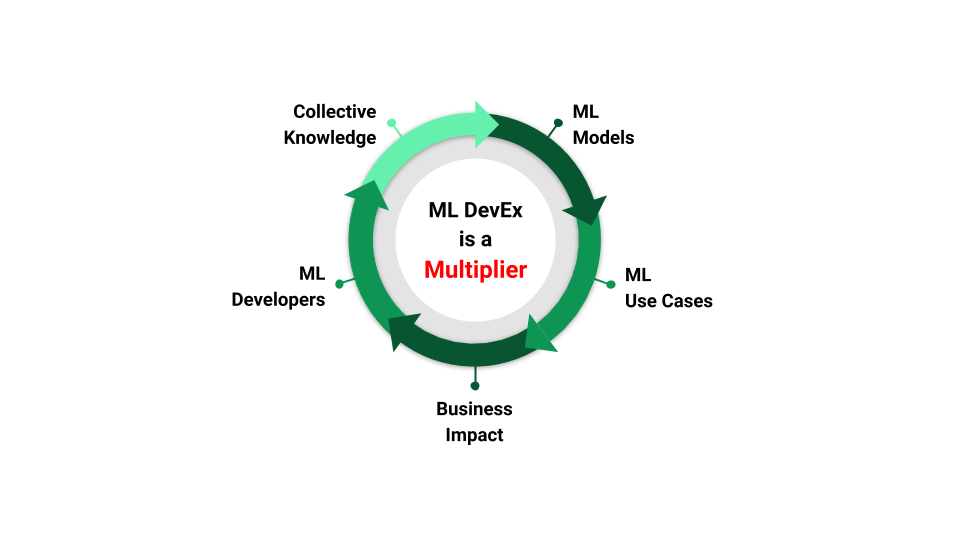
Journey of AI/ML @ Uber
Presently, Uber operates in over 10,000 cities spanning more than 70 countries, serving 25 million trips on the platform each day with 137 million monthly active users. ML has been integrated into virtually every facet of Uber’s daily operation. Virtually every interaction within the Uber apps involves ML behind the scenes. Take the rider app as an example: when users try to log in, ML is used to detect fraud signals like possible account takeovers. Within the app, in many jurisdictions, ML is deployed to suggest destination auto-completion and to rank the search results. Once the destination is chosen, ML comes into play for a multitude of functions, including ETA computation, trip price calculation, rider-driver matching with safety measures in mind, and on-trip routing. After the trip is completed, ML aids in payment fraud detection, chargeback prevention, and extends its reach to powering the customer service chatbot.
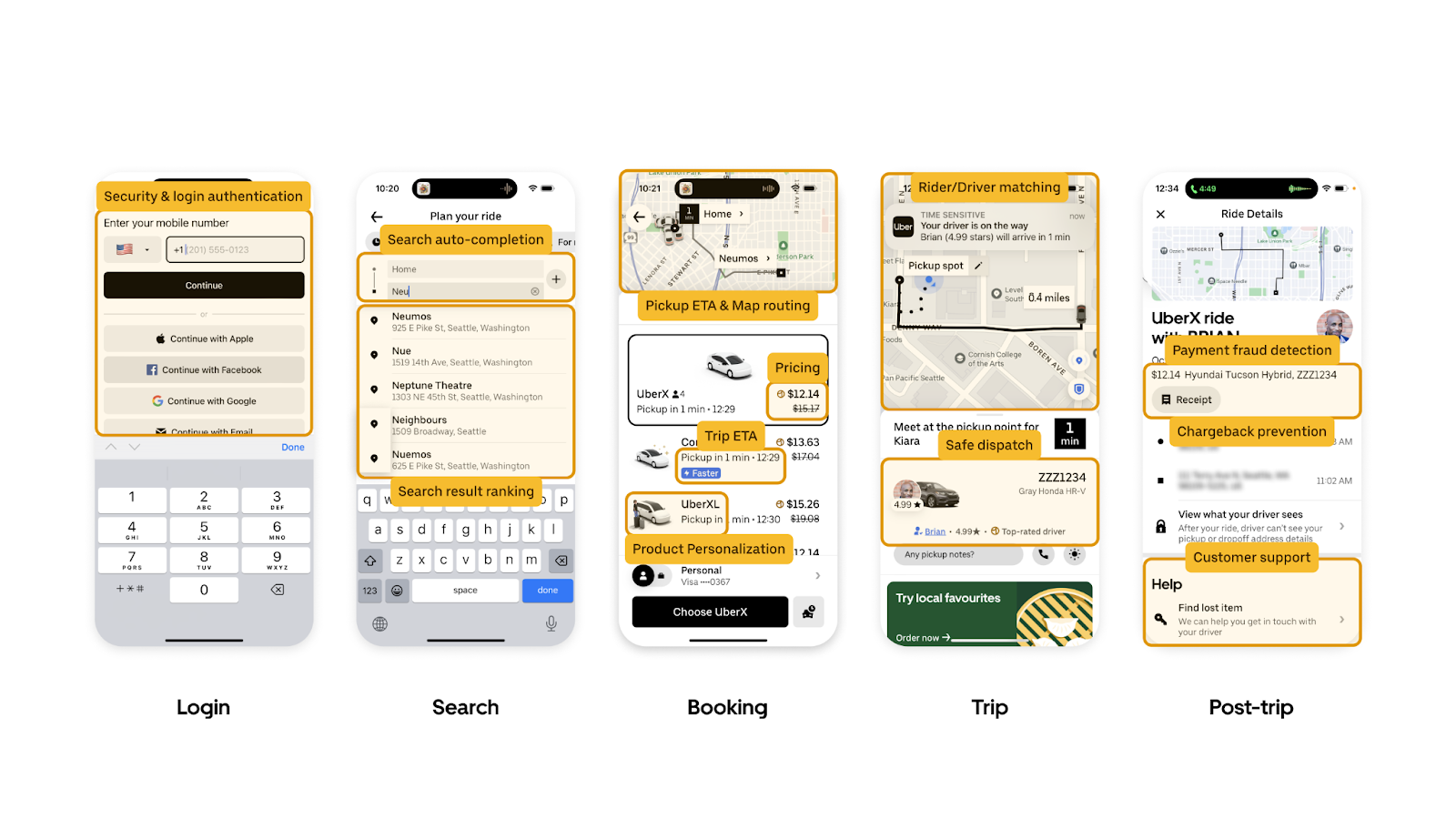
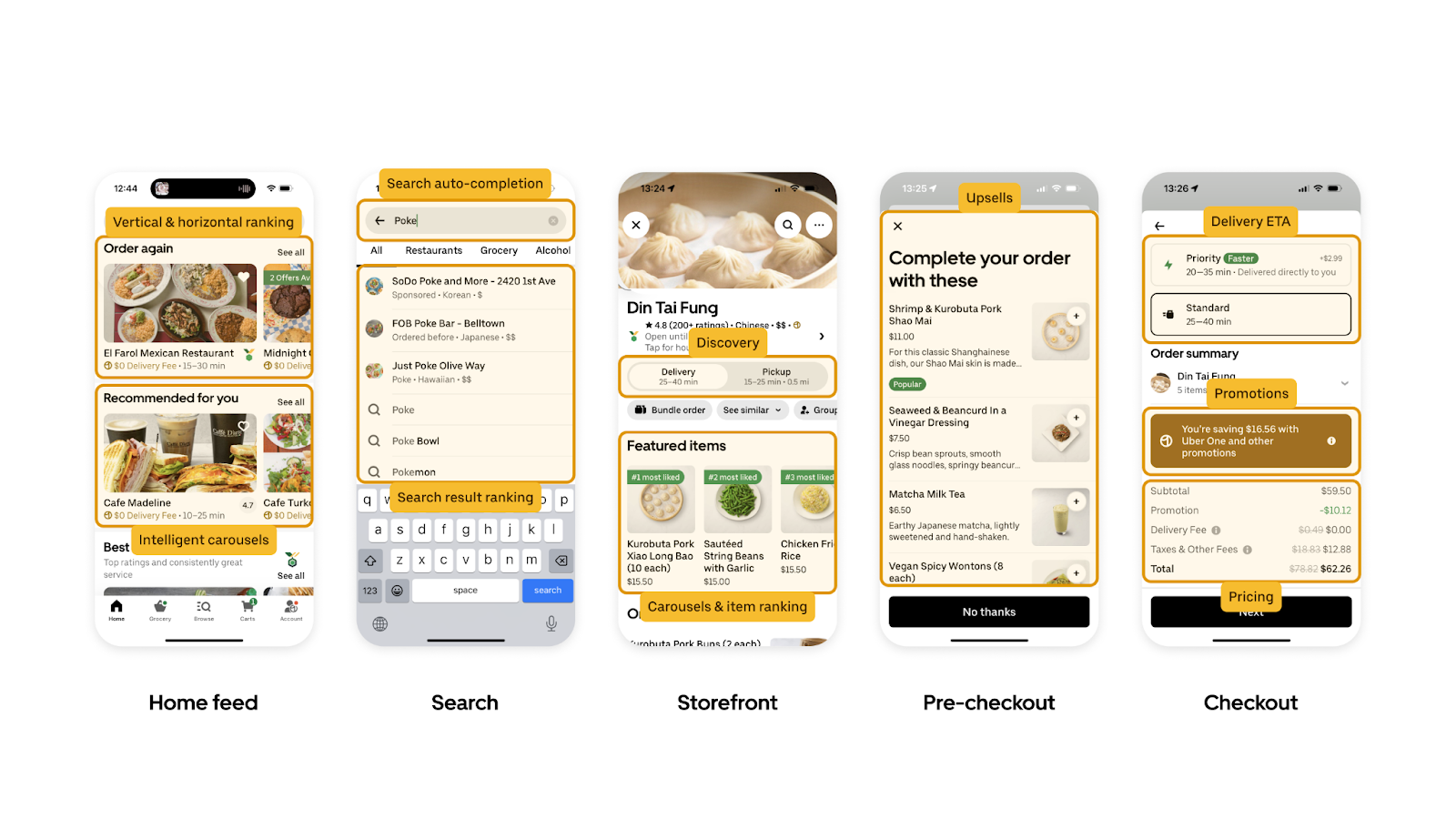
As you can see in Figure 2, real-time ML powers user flow in the rider app, and the same holds true for the Eats app (and many others), as illustrated in Figure 3 below.
Reflecting on the evolution of ML at Uber, there are three distinct phases:
- 2016 – 2019: During this initial phase, Uber primarily employed predictive machine learning for tabular data use cases. Algorithms, such as XGBoost, were used for critical tasks like ETA predictions, risk assessment, and pricing. Furthermore, Uber delved into the realm of deep learning (DL) in critical areas like 3D mapping and perception in self-driving cars, necessitating significant investments in GPU scheduling and distributed training methodologies, like Horovod®.
- 2019 – 2023: The second phase witnessed a concerted push towards the adoption of DL and collaborative model development for high-impact ML projects. The emphasis was on the model iteration as code within ML monorepo and supporting DL as a first-class citizen in Michelangelo. During this period, more than 60% of tier-1 models adopted DL in production and boosted model performance significantly.
- Starting in 2023: The third phase represents the latest development in the new wave of Generative AI, with a focus on improving Uber’s end-user experience and internal employee productivity (described in a previous blog).
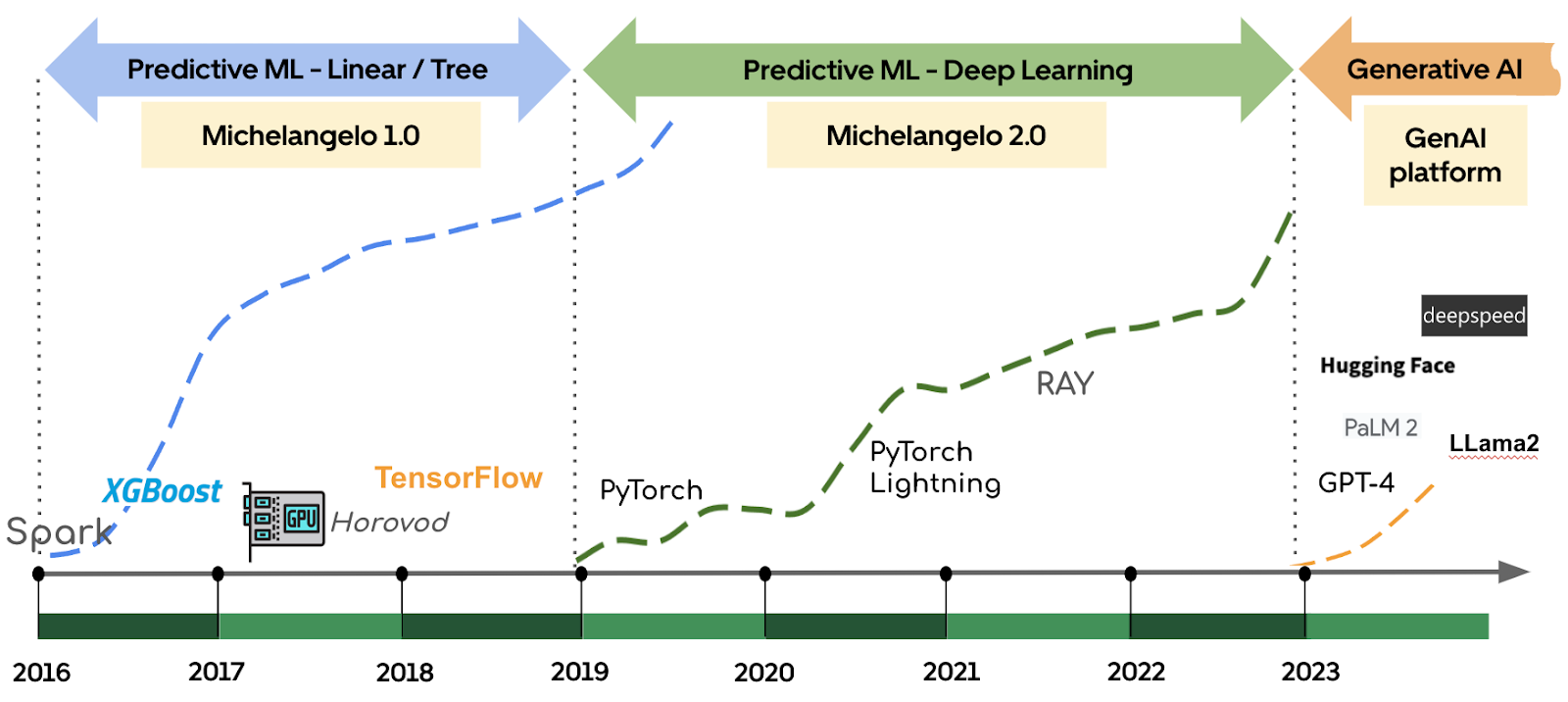
Throughout this transformative journey, Michelangelo has been playing a pivotal role in advancing ML capabilities and empowering teams to build industry-leading ML applications.
Michelangelo 1.0 (2016 – 2019)
When Uber embarked on its ML journey back in 2015, applied scientists used Jupyter Notebooks™ to develop models, while engineers built bespoke pipelines to deploy those models to production. There was no system in place to build reliable and reproducible pipelines for creating and managing training and prediction workflows at scale, and no easy way to store or compare training experiment results. More importantly, there was no established path to deploying a model into production without creating a custom serving container.
In early 2016, Michelangelo was launched to standardize the ML workflows via an end-to-end system that enabled ML developers across Uber to easily build and deploy ML models at scale. It started by addressing the challenges around scalable model training and deployment to production serving containers (Learn more). Then, a feature store named Palette was built to better manage and share feature pipelines across teams. It supported both batch and near-real-time feature computation use cases. Currently, Palette hosts more than 20,000 features that can be leveraged out-of-box for Uber teams to build robust ML models (Learn more).
Other key Michelangelo components released include, but are not limited to:
- Gallery: Michelangelo’s model and ML metadata registry that provides a comprehensive search API for all types of ML entities. (Learn more)
- Manifold: A model-agnostic visual debugging tool for ML at Uber. (Learn more)
- PyML: A framework that speeded up the cycle of prototyping, validating, and productionizing Python ML models. (Learn more)
- Extend Michelangelo’s model representation for flexibility at scale. (Learn more)
- Horovod for distributed training. (Learn more)
Michelangelo 2.0 (2019 – 2023)
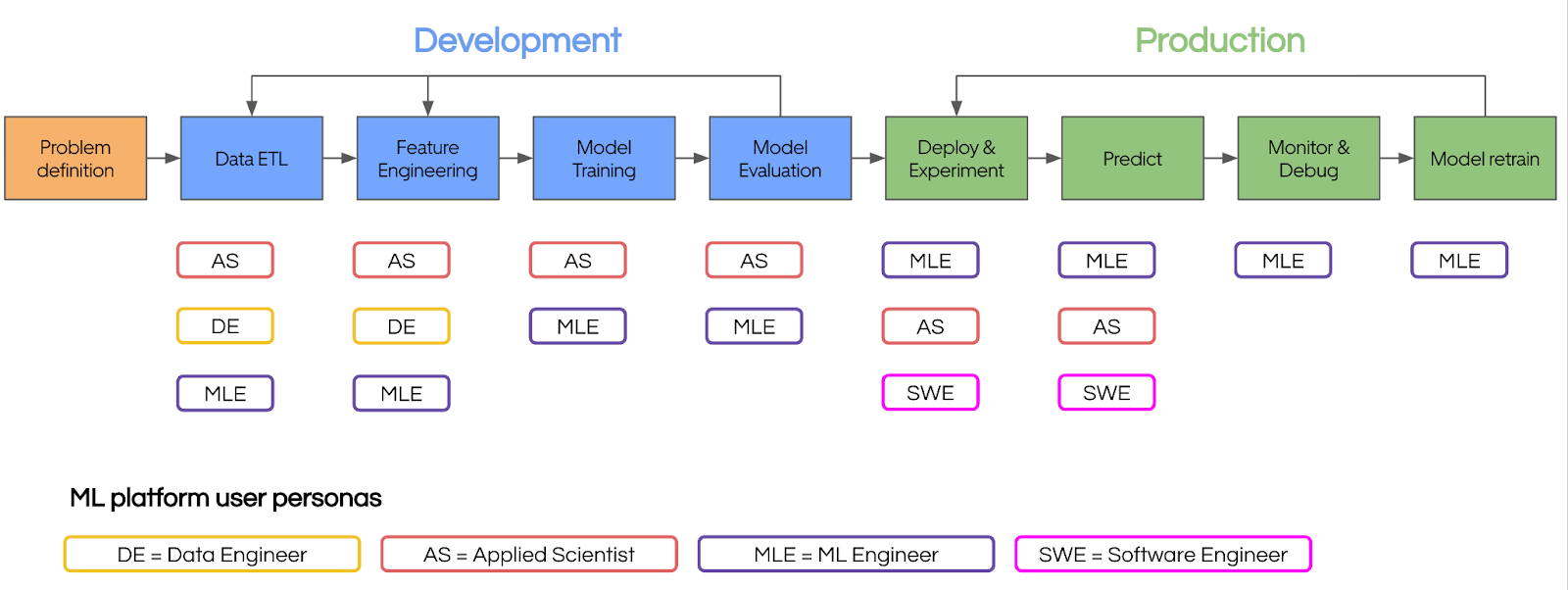
The initial goal of Michelangelo was to bootstrap and democratize ML at Uber. By the end of 2019, most lines of business at Uber had integrated ML into their products. Subsequently, Michelangelo’s focus started shifting from “enabling ML everywhere” to “doubling down on high-impact ML projects” so that developers could uplevel the model performance and quality of these projects to drive higher business value for Uber. Given the complexity and significance of these projects, there was a demand for more advanced ML techniques, particularly DL, and many different roles (e.g., data scientists and engineers) were often required to collaborate and iterate on models faster, as shown in Figure 5. This posed several challenges for Michelangelo 1.0, as listed below.
1. Lack of comprehensive ML quality definition and project tiering: Unlike micro-services which have well-defined quality standards and best practices, at that time there was not a consistent way to measure the full spectrum of model quality. For example, many teams only measured offline model performance such as AUC and RMSE, but ignored other critical metrics like online model performance, freshness of training data, and model reproducibility. This resulted in little visibility of model performance, stale models in production, and poor dataset coverage.
Also, it is important to recognize that ML projects vary significantly in terms of business impact. The lack of a distinct ML tiering system led to a uniform approach in resource allocation, support, and managing outages, regardless of a project’s impact. This resulted in high-impact projects receiving inadequate investment or not being given the priority they deserved.
2. Insufficient support for DL models: Up until 2019, ML use cases at Uber were predominantly using tree-based models, which inherently did not favor adopting advanced techniques like custom loss functions, incremental training, and embeddings. Conversely, Uber had vast data suitable for training DL models, but the infrastructure and developer experience challenges hindered the progress in this direction. Many teams like Maps ETA and Rider incentive teams had to invest months in developing their own DL toolkits before successfully training their first version of DL models.
3. Inadequacy of support for collaborative model development: In the early days, most ML projects were small-scale, and only authored and iterated by a single developer from inception to production. Hence, Michelangelo 1.0 was not optimized for highly collaborative model development, and collaboration in Michelangelo 1.0 UI and Jupyter Notebook was difficult and often done via manual copying and merging without version control or branching. In addition, there was no code review process for UI model config changes nor notebook edits, and the absence of a centralized repository for ML code and configurations led to their dispersion across various sources. These posed a significant threat to our engineering process and made large-scale model exploration across numerous ML projects arduous.
4. Fragmented ML tooling and developer experience: Since 2015, many ML tools other than Michelangelo have been built by different teams at Uber for a subset of the ML lifecycle and use cases, such as Data Science Workbench (DSW) from Data team for managed Jupyter Notebooks, ML Explorer from Marketplace team for ML workflow orchestration and automation, and uFlow/uScorer from Risk team specifically for training and inferencing models from their own team. There were also different ways to develop an ML model for different model types–e.g., Michelangelo UI for SparkML and XGBoost models, Jupyter Notebook for DL models, and PyML for custom Python-based models. Launching one ML project usually required constantly switching between such semi-isolated tools, which were built with different UI patterns and user flows, leading to fragmented user experience and reduced productivity.
To address these challenges, Michelangelo 2.0 re-architectured the fragmented ML platforms to a single coherent product with unified UI and API for the end-to-end ML lifecycle. Michelangelo 2.0 has four user-facing themes: (1) model quality and project tiering, (2) model iteration as code via Canvas, (3) DL as a first-class platform citizen, and (4) unified ML developer experience via MA Studio.
Architectural Overview
Michelangelo 2.0 is centered around four pillars. At the very bottom, we are enabling an architecture that allows for plug-and-play platform components. Some of the components are built in-house and others can be State-of-the-art commodity pieces from open source or 3rd party. On top is the development and production experience that caters to applied scientists and ML engineers. To improve model development velocity, we are streamlining the development experience and enabling technologies for collaborative, reusable development. We believe this approach will enable us to track and enforce compliance at the platform level. We are investing in production experiences like safe deployment of models and automatic model retraining, etc. to make it easy to maintain and manage models at scale. Finally, we are focusing on the quality of the models and investing in tooling that measures this quality across all stages and improves it systematically.
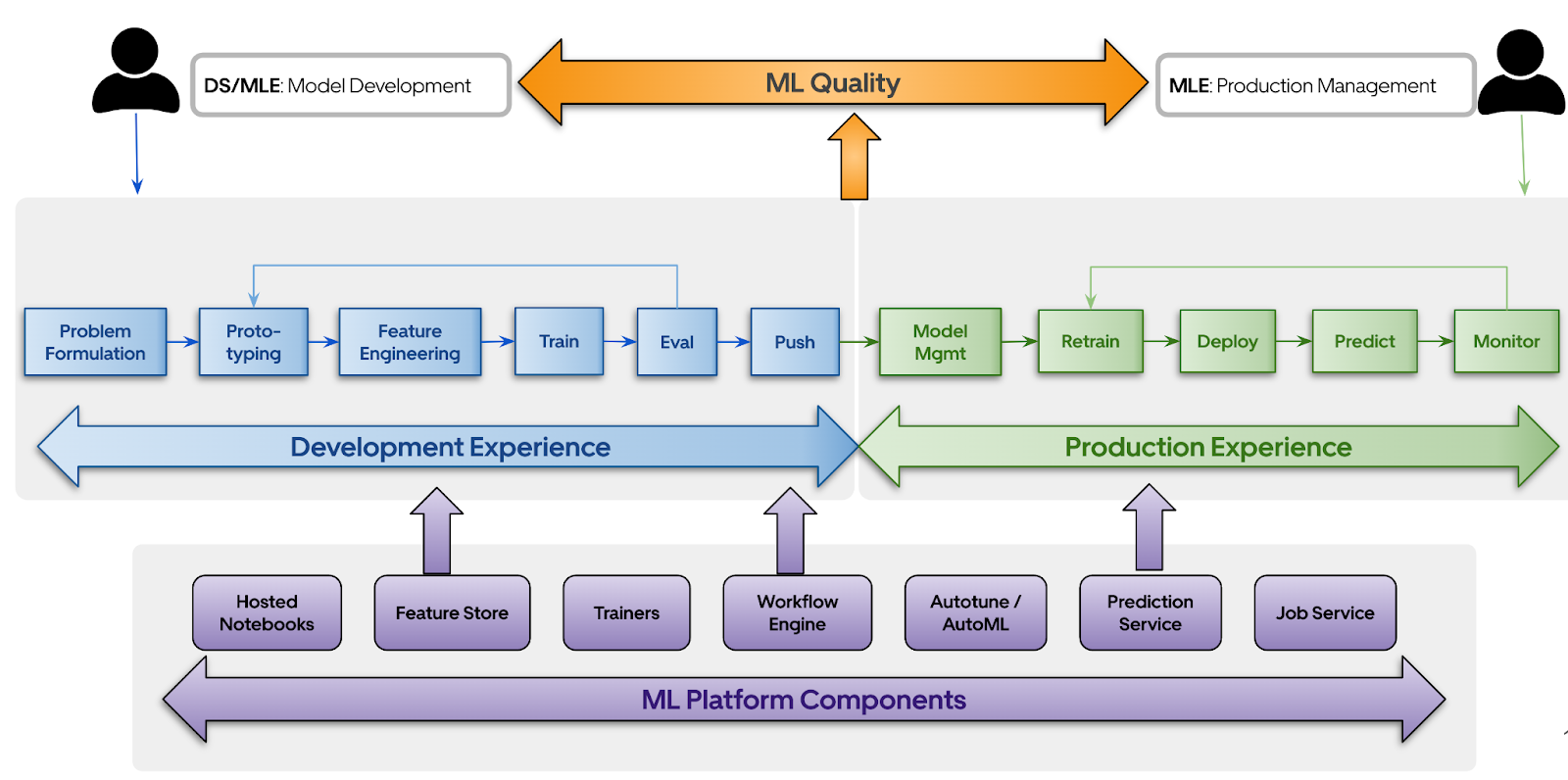
Here are a few architectural design principles for Michelangelo 2.0:
- Define project tiering, and focus on high-impact use cases to maximize Uber’s ML impact. Provide self-service to long-tail ML use cases so that they can leverage the power of the platform.
- The majority of ML use cases can leverage Michelangelo’s core workflows and UI, while Michelangelo also enables more bespoke workflows needed for advanced use cases like deep learning.
- Monolithic vs. plug-and-play. Architecture will support plug-and-play of different components, but the managed solution will only support a subset of them for the best user experience. Bring your own components for advanced use cases.
- API/code-driven vs. UI-driven. Take the API first principle and leverage UI for visualization and fast iteration. Support model iteration as code for version control and code reviews, including changes made in UI.
- Build vs. buy decision. Leverage best-of-class offerings from OSS or Cloud or building in-house. OSS solutions may be prioritized over proprietary solutions. Be cautious about the cost of capacity for Cloud solutions.
- Codify the best ML practices like safe model deployment, model retraining, and feature monitoring in the platform.
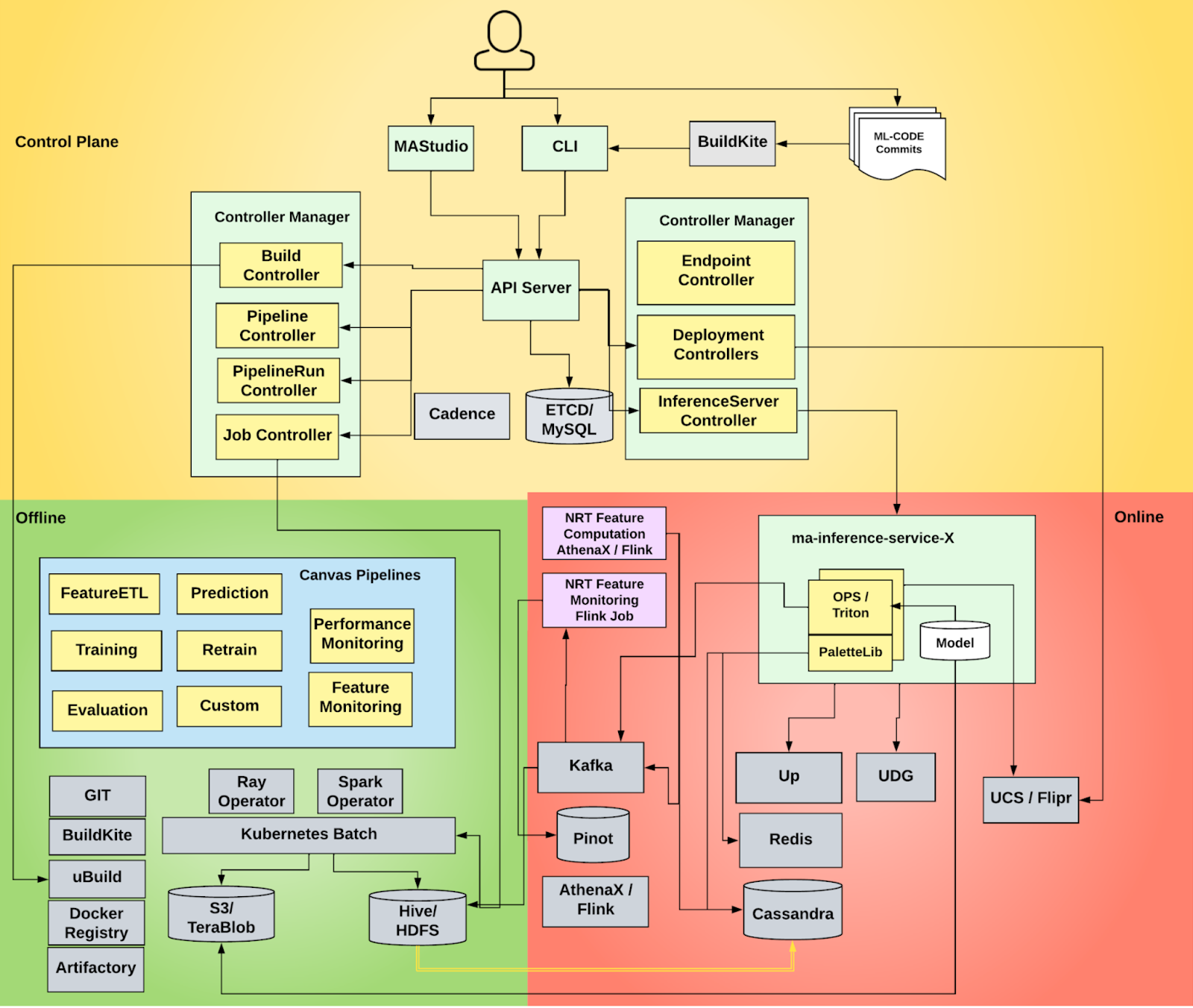
The system consists of three planes–i.e., control plane, offline and online data planes. The control plane defines user-facing APIs and manages the lifecycle of all entities in the system. The offline data plane does the heavy lifting on big data processing such as feature computation, model training and evaluation, offline batch inference, etc. The online data plane handles real-time model inference and feature serving, which are used by other microservices.
The control plane adopts the same Kubernetes™ Operator design pattern for modularization and extensibility. The Michelangelo APIs also follow the same Kubernetes API conventions and standardize the operations on ML-related entities like Project, Pipeline, PipelineRun, Model, Revision, InferenceServer, Deployment, etc. By leveraging the Kubernetes API machinery including API server, etcd, and controller manager, all Michelangelo APIs can be accessed in a consistent manner, resulting in a more user-friendly and streamlined user experience. In addition, the declarative API pattern is also crucial for Michelangelo to support mutation by both UI and code in a GIT repo, as detailed later.
The offline data plane consists of a set of ML pipelines including training, scoring, evaluation, etc., which are defined as DAG of steps. The ML pipelines support intermediate checkpoints and resume between steps to avoid duplicate executions of previous steps. Steps are executed on top of frameworks like Ray™ or Spark™. The online data plane manages RPC services and streaming processing jobs that serve online prediction, online feature access, and near-real-time feature computation.
Figure 7 shows the detailed design of the Michelangelo 2.0 system, which reduced the engineering complexity as well as simplified the external dependencies on other infrastructure components.
Model Quality and Project Tiering
The development and maintenance of a production-ready ML system are intricate, involving numerous stages in the model lifecycle and a complex supporting infrastructure. Typically, an ML model undergoes phases like feature engineering, training, evaluation, and serving. The lack of comprehensive ML quality measurement leads to limited visibility for ML developers regarding various quality dimensions at different stages of a model’s lifecycle. Moreover, this gap hinders organizational leaders from making fully informed decisions regarding the quality and impact of ML projects.
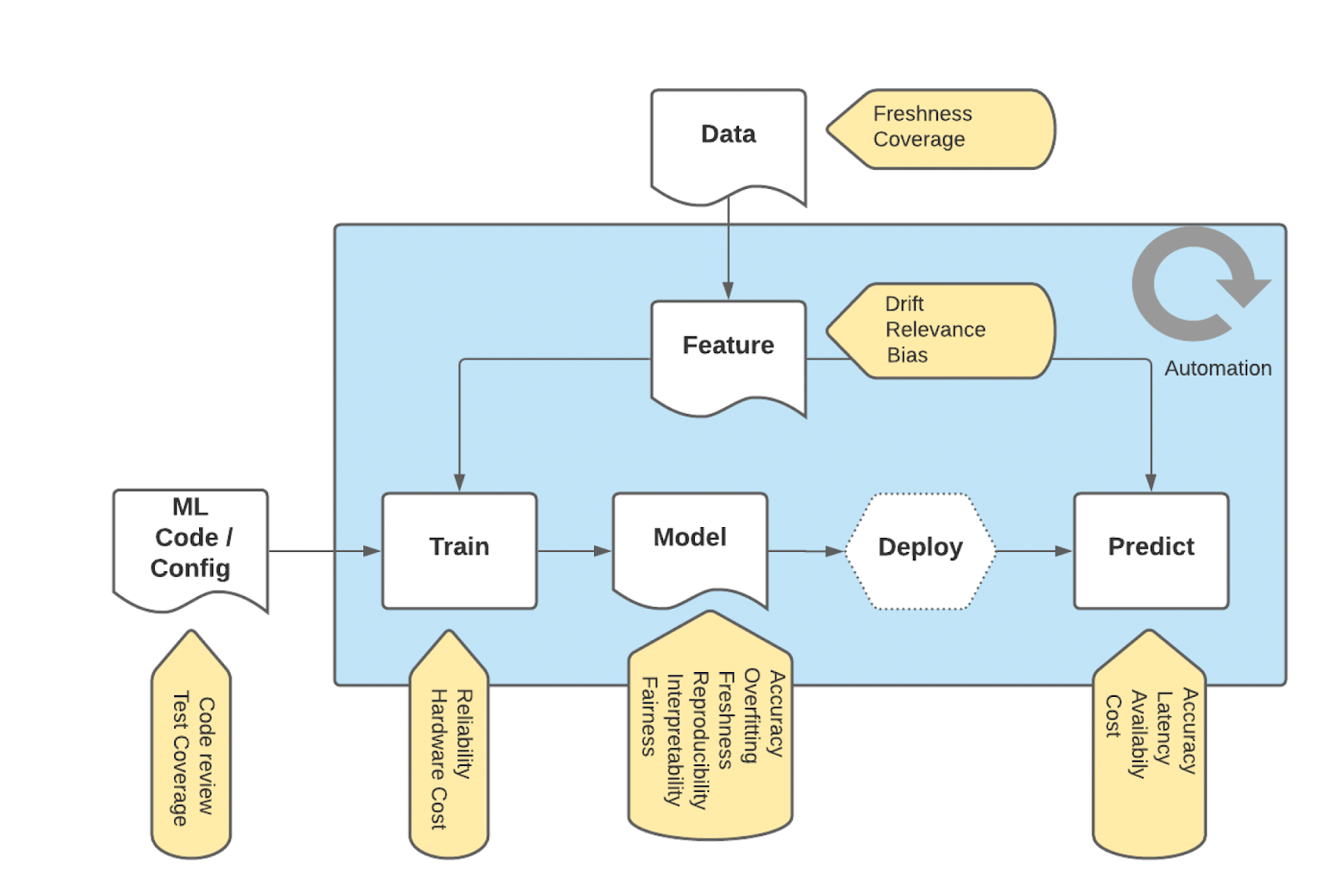
To address these gaps, we launched Model Excellence Score (MES), a framework for measuring and monitoring key dimensions and metrics at each stage of a model’s life cycle, such as training model accuracy, prediction accuracy, model freshness, and prediction feature quality, to ensure a holistic and rigorous approach to ML deployment at scale. This framework leverages the same Service Level Agreement (SLA) concept that is commonly used by site reliability engineers (SREs) and DevOps professionals to manage microservices reliability in production environments. By integrating with the SLA toolset, MES establishes a standard for measuring and ensuring ML model quality at Uber. Additionally, MES tracks and visualizes the compliance and quality of models, thereby providing a clearer and more comprehensive view of ML initiatives across the organization. See MES blog for more details.
To differentiate high-impact and long-tail use cases, we introduced a well-defined ML project tiering scheme. This scheme consisted of four tiers, with tier 1 being the highest. Tier 1 projects consist of models serving critical functions within core trip and core eater flows, such as ETA calculations, safety, and fraud detection, etc. Only models directly influencing core business operations can qualify for tier-1 status. Conversely, tier-4 projects typically encompass experimental and exploratory use cases with limited direct business impact. This tiering scheme enabled us to make informed decisions regarding resource allocation for ML project outage handling, resource investment, best practice enforcement, and compliance matters, among other considerations. It ensured that the level of attention and resources devoted to each project was commensurate with its relative priority and impact.
Model iterations as code
To enhance ML developer productivity, foster seamless team collaboration, and elevate the overall quality of ML applications in 2020, we launched Project Canvas. The project aimed to apply software engineering best practices for the ML development lifecycle enforcing version controls, harnessed the power of Docker containers, integrated CI/CD tools, and expedited model development by introducing standardized ML application frameworks. Key components of Canvas included:
- ML Application Framework (MAF): Predefined, but customizable ML workflow templates to provide a code and configuration-driven way for ML development, tailor-made for intricate ML techniques such as DL.
- ML Monorepo: A centralized repository that stores all ML development sources of truth as code, with robust version control capabilities.
- ML Dependency Management: Provides software dependency management using Bazel and docker builds. Each ML project has their own customized docker images. In addition to software dependencies, the model training and serving code will be packaged into an immutable docker image for production model retraining and serving.
- ML Development Environment: Provides consistent local developing and remote production execution environments for ML developers so that they can test and debug the models locally before running it in a remote production environment for fast model iteration.
- ML Continuous Integration / Continuous Delivery: Continuous integration against the master branch and automates the deployment to production for ML models landed to the master branch of ML monorepo via various tests and validations.
- ML Artifact Management: Provide support for artifact and lineage tracking. Artifacts are ML objects such as models, datasets and evaluation reports plus their corresponding metadata. The objects will be stored in distributed storage, and the metadata will be fully indexed and searchable.
- MA Assistant (MAA): Michelangelo’s AutoML solution for automatic model architecture search and feature exploration/pruning.
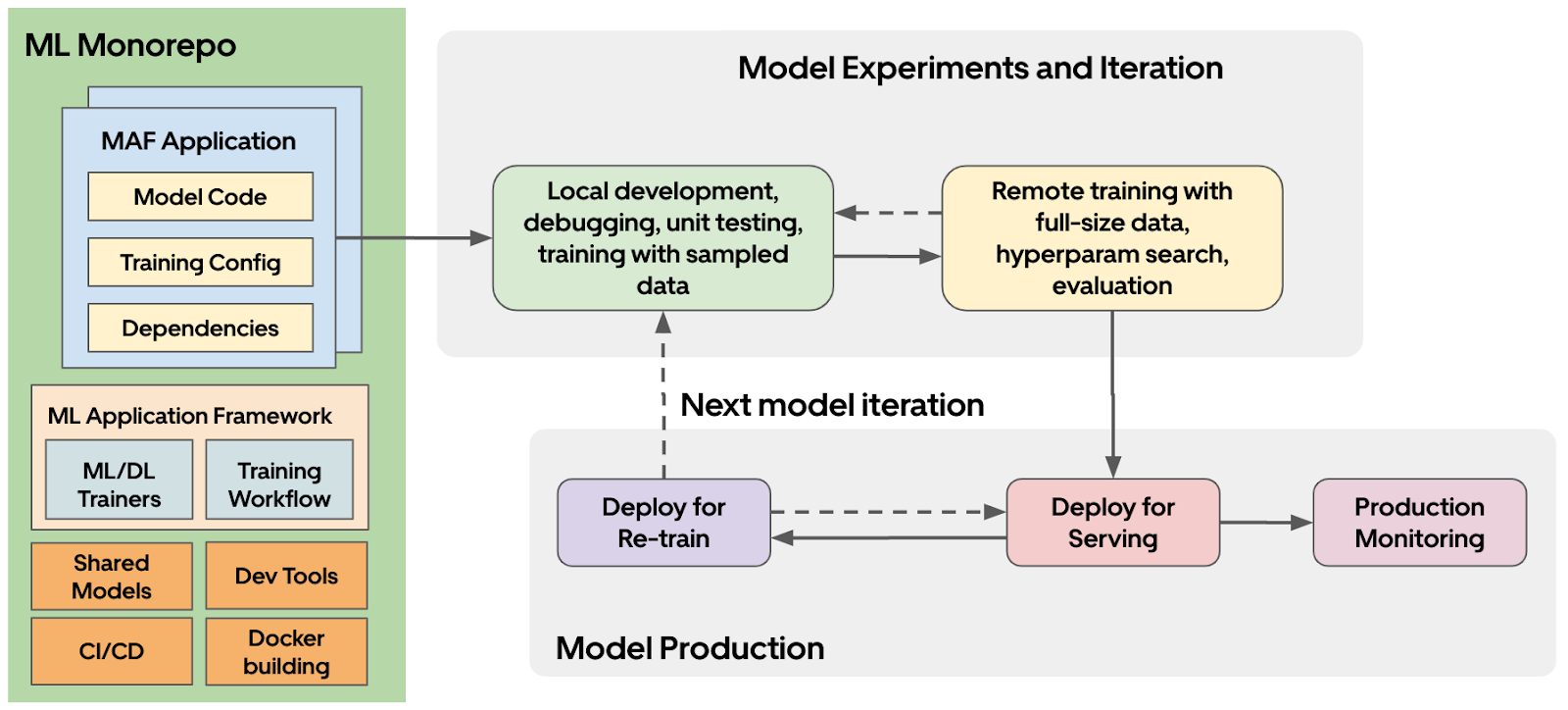
Canvas also streamlined the ML dependency management by leveraging Bazel and docker builds. Each ML project would have its custom docker images, and the model training and serving code will be packaged into an immutable docker image for production model retraining and serving. Moreover, Canvas enabled consistent local and remote development environments for ML developers to test and debug the models locally before running them in a remote production environment for fast model iteration.
Deep Learning as a first-class platform citizen
Adopting advanced techniques such as custom loss functions, incremental training, and embeddings posed significant challenges. DL is more flexible to address these challenges. Furthermore, DL often excels as datasets grow larger, as it can leverage more data to learn more complex representations.
Before 2019, most of the DL models at Uber were for self-driving cars (e.g., 3D mapping, perception), computer vision (e.g., driver face recognition), and natural language processing (e.g., customer obsession) use cases. However, there were very few deep learning models for the core business, especially for tabular data use cases. One important reason that hindered the adoption of deep learning is the lack of end-to-end deep learning support in Michelangelo 1.0. Different from tree-based models, deep learning models often require much more sophisticated ML platform support, from feature transformation and model training to model serving and GPU resource management. The rest of this section will give an overview of our investment in deep learning support in Michelangelo 2.0.
Feature transformation
Michelangelo 1.0 implemented a DSL for feature transformation such as normalization and bucketization that are used in both model training and serving paths. The transformation is bundled together with a model as a Spark PipelineModel so that it eliminates a source of training-serving skews. However, the DSL transformation is implemented as a Spark transformer and can not be run on GPU for DL models for low-latency serving. In Michelangelo 2.0, we implemented a new DL native transformation solution that allows users to transform their features using Keras or PyTorch operators and provides advanced users the flexibility to define customized feature transformation using Python code. Similar to TensorFlow transform, the transform graph is combined with the model inference graph either in TensorFlow or TorchScript for low-latency serving on GPUs.
Model training
Michelangelo 2.0 supports both TensorFlow and PyTorch frameworks for large-scale DL model training by leveraging our distributed training framework Horovod. In addition, we have made the following improvements for better scalability, fault tolerance, and efficiency.
- Distributed GPU training and tuning on Ray. (Learn more). Historically, the model training in Michelangelo was running on top of Spark. However, DL presented new challenges on Spark such as a lack of GPU executors, mini-batch shuffle, and all-reduce. Horovod on Spark wrapped the DL training using Spark estimator syntax and provided easy integration to the training pipeline. However, it also introduced many operational complexities like separate cluster jobs, lifecycle management, and failure scenarios. In Michelangelo 2.0, we have replaced Spark-based XGBoost and DL trainers with Ray-based trainers for better scalability and reliability. We also switched from an in-house hyperparameter tuning solution to RayTune.
- Elastic Horovod with auto-scaling and fault tolerance. (Learn more). Elastic Horovod allows distributed training that scales the number of workers dynamically throughout the training process. Jobs can now continue training with minimal interruption when machines come and go from the job.
- Resource efficient incremental training. One advantage of DL is the ability to incrementally train a model with additional datasets without training from scratch. This significantly improves the resource efficiency for production retrains as well as increases the dataset coverage for better model accuracy.
- Declarative DL training pipeline in Canvas. DL models require custom model code and loss functions etc. In Canvas, we designed the training pipelines to be declarative as well as extensible for users to plug-in their custom model code such as estimators, optimizers, and loss functions as shown in Figure 9.

Model serving
Most of Uber’s tier-1 ML projects that were adopting DL are very sensitive to serving latency, such as maps ETA and Eats homefeed ranking. In addition, the model serving has to support both TensorFlow and PyTorch DL frameworks but abstract out the framework-level details away from our users. Historically, Neuropod has been the default DL serving engine in Michelangelo. However, it lacks continuous community support and is being deprecated. In Michelangelo 2.0, we integrated Triton as a next-generation model serving engine in our Online Prediction Service (OPS) as a new Spark transformer. Triton is an open-source inference server developed by Nvidia and supports multiple frameworks including TensorFlow, PyTorch, Python, and XGBoost, it is highly optimized for GPUs for low-latency serving.
GPU resource management
Both DL training and serving require large-scale GPU resources. Uber today manages more than five thousand GPUs across both on-premise data centers and Cloud providers like OCI and GCP. Those GPUs spread across multiple regions and many zones and clusters. The Compute clusters are in the process of migrating from Peloton / Mesos to Kubernetes. To maximize resource utilization, Uber has invested in elastic CPU and GPU resource sharing across different teams so that each team can opportunistically use the other team’s idle resources. On top of the Compute clusters, we built a job federation layer across multiple Kubernetes clusters to hide the region, and zone and cluster details for better job portability and easy Cloud migration. The job federation layer leverages the same design pattern as Kubernetes operators and is implemented as a job CRD controller in Michelangelo’s unified API framework as shown in Figure 7. Currently, the job controller supports both Spark and Ray jobs.
With the end-to-end support for DL in Michelangelo 2.0, Uber has made a significant improvement in DL adoption across different business lines. In the last few years, the DL adoption in tier-1 projects has increased from almost zero to more than 60%. For example, the DeepETA model has more than one hundred million parameters and was trained over one billion trips.
MA Studio – One unified Web UI tool for everything ML @ Uber
To address the challenges in the ML developer experience mentioned above, Michelangelo (MA) Studio was developed to unify existing Michelangelo offerings and newly built platform capabilities into one single user journey, to provide a seamless user experience, with a completely redesigned UI and UX. MA Studio provides a simplified user flow covering every step of the ML journey from feature/data prep, model training, deployment, all the way to production performance monitoring, and model CI/CD, all in one place, to improve ML developer productivity.
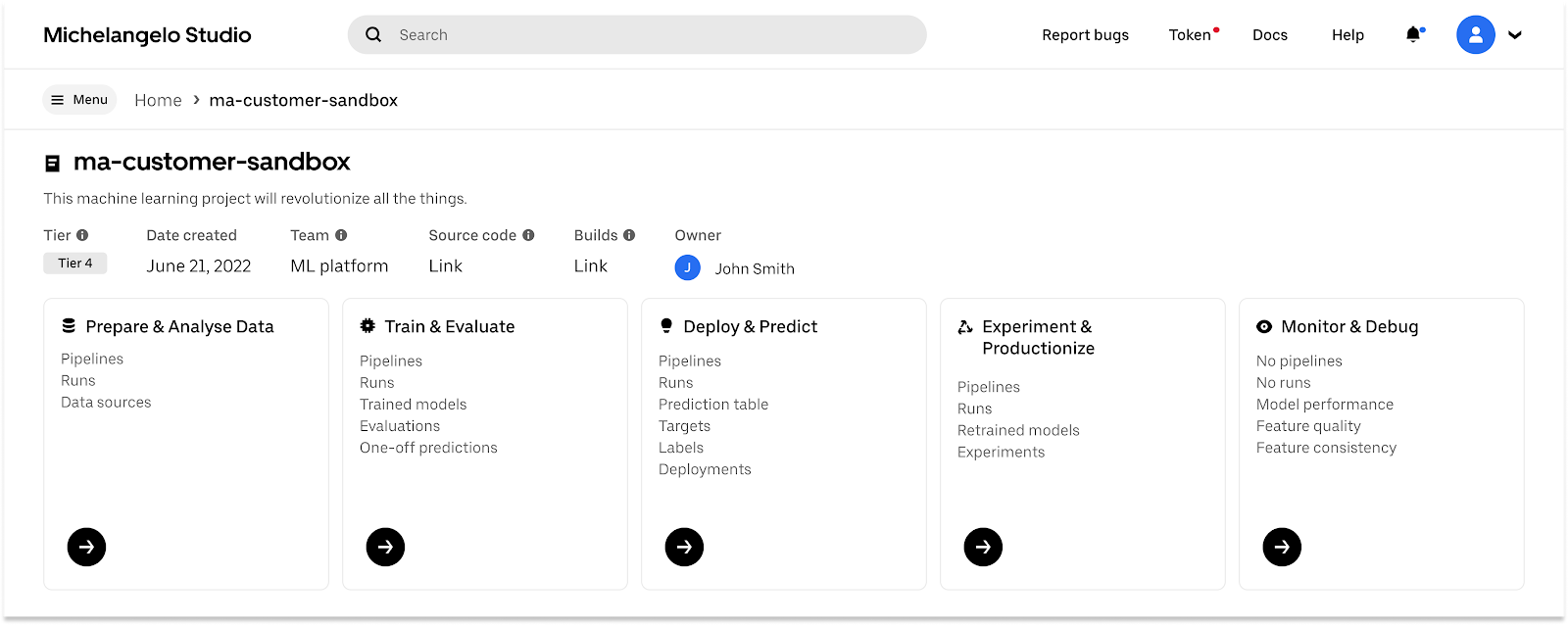
MA Studio boasts an array of additional advantages:
- Version control and code review: All ML-related code and configurations are version controlled, and all changes go through the code review process, including models created from UI.
- Modernized model deployment stack: Safe and incremental zonal rollout, automatic rollback triggers, and production runtime validation.
- Built-in and unified ML observability toolkit: Model performance monitoring, feature monitoring, online/offline feature consistency check, and MES.
- Unified ML entity lifecycle management: Users benefit from an intuitive UI and well-structured user flows for managing all ML entities, from models and pipelines to datasets and reports.
- Enhanced debugging capabilities: MA Studio amplifies debugging capabilities and accelerates recovery for ML pipeline failures.
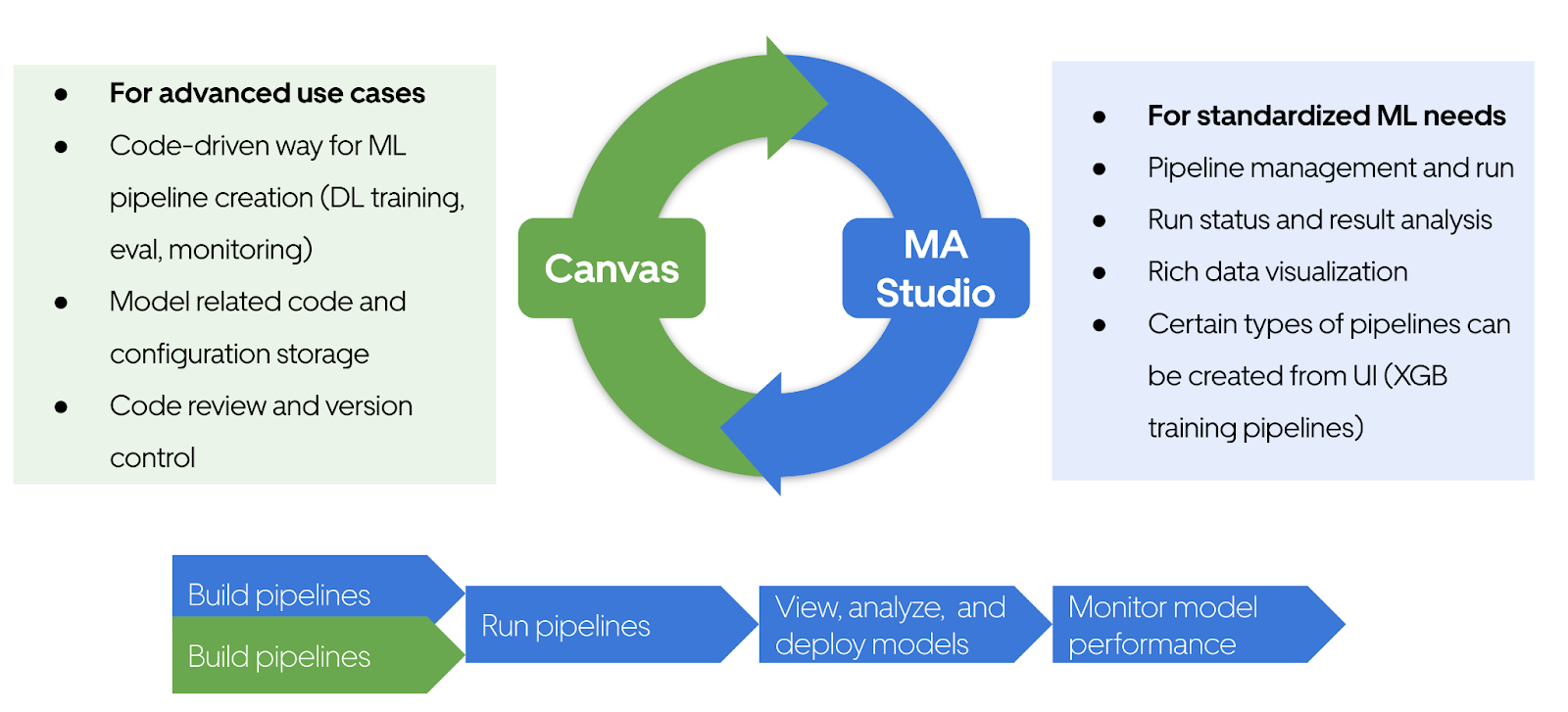
For any ML need at Uber, you only need two tools: Canvas and MA Studio. MA Studio’s user-friendly UI covers standard ML workflows, facilitating tasks like XGB model training and the standard model retrain process without any necessity to write any code. When dealing with more sophisticated scenarios, such as DL training or customized retraining flows, Canvas is the go-to tool. Regardless of whether you’ve constructed the pipelines through Canvas or the UI, you can seamlessly execute and manage these pipelines, deploy trained models, and monitor and debug model performance—all from the MA Studio UI. Significantly, all model code and pertinent configurations are now subject to version control, and any alterations undergo a meticulous code review process, which drastically improves the quality of ML applications in production at Uber.
Generative AI (2023 – now)
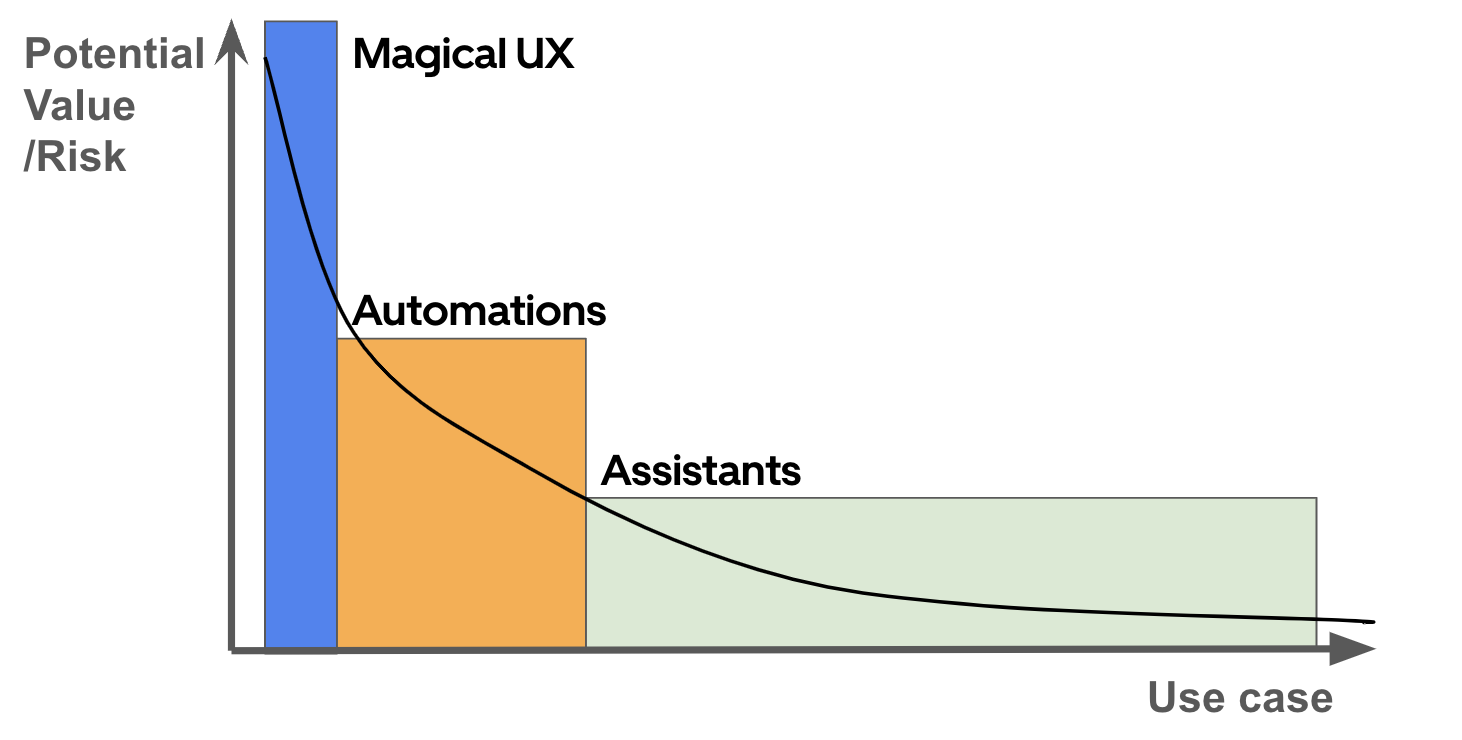
Recent advancements in generative AI, particularly in the realm of large language models (LLMs), possess the capacity to radically transform our interactions with machines via natural language. Several teams at Uber are actively investigating the use of LLMs to boost internal productivity with assistants, streamline business operations with automation, and improve the end-user product with magical user experience while addressing issues associated with the use of LLMs. Figure 12 shows the potential values of those three categories of generative AI use cases at Uber. Learn more.
For developing generative AI applications, teams need access to both external LLMs through third-party APIs and/or internally hosted open-source LLMs. This is because external models have superior performance in tasks requiring general knowledge and intricate reasoning, while by leveraging the wealth of proprietary data, we can fine-tune open-source models to achieve high levels of accuracy and performance on Uber-centric tasks, at a fraction of the cost and lower latency. These fine-tuned open-source models are hosted in-house.
Hence, we developed the Gen AI Gateway to provide a unified interface for teams to access both external LLMs and in-house hosted LLMs in a manner adhering to security standards and safeguarding privacy. Some of the Gen AI Gateway capabilities include:
- Logging and auditing: Ensuring comprehensive tracking and accountability.
- Cost guardrails and attribution: Managing expenses while attributing usage, and also alerting on over usage.
- Safety & Policy Guardrails: Ensuring LLM usage complies with our internal guidelines.
- Personal identifiable information (PII) Redaction: Identifying and categorizing personal data, and redacting it before sending the input to external LLMs.
To accelerate the development of generative AI applications at Uber, we have extended Michelangelo to support the full LLMOps capabilities such as fine-tuning data preparation, prompt engineering, LLM fine-tuning and evaluation, LLM deployment and serving, and production performance monitoring. Some of the key components include:
- The Model Catalog features a collection of pre-built and ready-to-use LLMs, accessible via third-party APIs (e.g., GPT4, Google PaLM) or in-house hosted open-source LLMs on Michelangelo (e.g., Llama2). Users can explore extensive information about these LLMs within the catalog and initiate various workflows. This includes fine-tuning models in MA Studio or deploying models to online serving environments. The catalog offers a wide selection of pre-trained models, enhancing the platform’s versatility.
- LLM Evaluation Framework enables users to compare LLMs across different approaches (e.g., in-house vs. 3P with prompts vs 3P fine-tuned), and also evaluate improvements with iterations of prompts and models.
- Prompt Engineering Toolkit allows users to create and test prompts, validate the output, and save prompt templates in a centralized repository, with full version control and code review process.
To enable cost-effective LLM fine-tuning and low-latency LLM serving, we’ve implemented several significant enhancements to Michelangelo training and serving stack:
- Integrating with Hugging Face: We implemented a Ray-based trainer for LLMs, utilizing the open source LLMs available on the Hugging Face Hub and associated libraries like PEFT. Fine-tuned LLMs and associated metadata are stored in Uber’s model repository, which is accessible from the model inference infrastructure.
- Enabling Model Parallelism: Michelangelo previously did not support model parallelism for training DL models. This limitation constrained the size of trainable models to the available GPU memory, allowing, for instance, a theoretical maximum of 4 billion parameters on a 16 GB GPU. In the updated LLM training framework, we’ve integrated Deepspeed to enable model parallelism. This breakthrough eliminates the GPU memory limitation and allows for training larger DL models.
- Elastic GPU Resource Management: We’ve provisioned Ray clusters on GPUs with the Michelangelo job controller. This provision empowers the training of LLM models on the most powerful GPUs available on-premises. Furthermore, this integration sets the stage for future extensions using cloud GPUs, enhancing scalability and flexibility.
Leveraging these platform capabilities offered by Michelangelo, teams at Uber are fervently developing LLM-powered applications. We look forward to sharing our advancements in the productionization of LLMs soon.
Conclusion
ML has evolved into a fundamental driver across critical business areas at Uber. This blog delves into the eight years transformative journey of Uber’s ML platform, Michelangelo, emphasizing significant enhancements in the ML developer experience. This journey unfolded in three distinct phases: the foundational phase of predictive ML for tabular data from 2016 to 2019, a progressive shift to deep learning between 2019 and 2023, and the recent venture into generative AI starting in 2023.
There have been critical lessons learned for building a large-scale, end-to-end ML platform at such a complexity level, supporting ML use cases at Uber’s scale. Key takeaways include:
- Instituting a centralized ML platform, as opposed to having individual product teams build their own ML infrastructure, can significantly enhance ML development efficiency within a medium- or large-sized company. And the ideal ML organizational structure comprises a centralized ML platform team, complemented by dedicated data scientists and ML engineers embedded within each product team.
- Providing both UI-based and code/configuration-driven user flows in a unified manner is crucial for delivering a seamless ML dev experience, especially for large organizations where ML developers’ preferences of dev tools largely vary across different cohorts.
- The strategy of offering a high-level abstraction layer with predefined workflow templates and configurations for most users, while allowing advanced power users to directly access low-level infrastructure components to build customized pipelines and templates has proven effective.
- Designing the platform architecture in a modular manner so that each component can be built with a plug-and-play approach, which allows rapid adoption of state-of-the-art technologies from open source, third-party vendors, or in-house development.
- While Deep Learning proves powerful in solving complex ML problems, the challenge lies in supporting large-scale DL infrastructure and maintaining the performance of these models. Use DL only when its advantages align with the specific requirements. Uber’s experience has shown that in several cases, XGBoost outperforms DL in both performance and cost.
- Not all ML projects are created equal. Having a clear ML tiering system can effectively guide the allocation of resources and support.
Michelangelo’s mission is to provide Uber’s ML developers with best-in-class ML capabilities and tools so that they can rapidly build, deploy, and iterate high-quality ML applications at scale. As the AI platform team, we provide in-depth ML expertise, drive standardization and innovation of ML technologies, build trust and collaborate with our partner teams, and cultivate a vibrant ML culture, so that ML is embraced and leveraged to its fullest potential. We are unwavering in our commitment to this mission, and we are incredibly enthusiastic about the promising future ahead of us.
If you are interested in joining us on this exciting venture, please check our job website for openings. Additionally, we look forward to collaborating with other teams in the AI/ML space to build a strong ML community and collectively accelerate the advancement of AI/ML technologies.
Apache®, Apache Spark, Spark, and the star logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Horovod and Kubenetes are either registered trademarks or trademarks of the Linux Foundation® in the United States and/or other countries. No endorsement by the Linux Foundation® is implied by the use of these marks.
Ray is either a registered trademark or trademark of Anyscale, Inc in the United States and/or other countries.

Kai Wang
Kai Wang is the Lead Product Manager of the AI Platform team at Uber, based in the San Francisco Bay Area. Kai manages a broad set of product areas, including data prep, model training and evaluation, deployment and prediction, monitoring and debugging, and ML workflow orchestration. Kai’s recent focus is on extending Michelangelo to enable end-to-end LLMOps and GenAI applications at Uber.

Min Cai
Min Cai is a Distinguished Engineer at Uber working on the AI/ML platform, Michelangelo. He received his Ph.D. degree in Computer Science from Univ. of Southern California. He has published over 20 journal and conference papers and holds 6 US patents.

Joseph Wang
Joseph Wang serves as a Principal Software Engineer on the AI Platform team at Uber, based in San Francisco. His notable achievements encompass designing the Feature Store, expanding the capacity of the real-time prediction service, developing a robust model platform, and improving the performance of key models. Presently, Wang is focusing his expertise on advancing the domain of generative AI.

Eric Chen
Eric Chen is a founding member of Michelangelo. Eric is a Sr. Engineering Manager within the AI Platform team at Uber, based in the San Francisco Bay Area. He manages the end-to-end tool chains provided by the platform. Eric's recent focus is on building the developer tool chains on LLM, embeddings, and data analytics.
Posted by Kai Wang, Min Cai, Joseph Wang, Eric Chen
Related articles




Most popular

Adopting Arm at Scale: Bootstrapping Infrastructure

Adopting Arm at Scale: Transitioning to a Multi-Architecture Environment

A beginner’s guide to Uber vouchers for riders
