Introducing Uber Poet, an Open Source Mock App Generator for Determining Faster Swift Builds
25 July 2019 / Global
Given the scope and scale of Uber’s business, our Swift applications are some of the largest in the world. Each application possesses 500,000 to 1 million lines of shipping Swift and Objective-C code and about three times more lines of code in the form of tests and auto-generated mocks.
As a result of the makeup of our iOS apps, Swift compile times are an important consideration for our engineers. Just a couple years ago, clean build times with our Swift-based rider app used to take 30 to 45 minutes, and after improvements in build configuration, the swift compiler, and build hardware, Swift builds now take about 5 to 10 minutes depending on the application. Slow build times lead to longer development times for engineers, which means slower turnaround times for new features and improvements, along with all of the other typical issues with long build times.
Before Swift 4.0, we determined building many small Swift modules (~300) built with whole module optimization (WMO) mode was the fastest overall build mode for Uber. Swift 4.0 introduced a new batch build mode, which while advertised to work faster in most cases, was about 25 percent slower to build with our ~300 module configuration.
We wanted to test if refactoring the application part of our code into a few large modules would make our overall build time faster with the new batch mode but without actually refactoring it. To test out this hypothesis, we created Uber Poet, a mock application generator to simulate our target dependency structures. To enable others to benefit from our mock application generator, we have decided to open source it.
In this article, we discuss our motivation behind the tool, its design principles, and how Swift developers can leverage the software for their own applications. After learning more about Uber Poet, we hope you will be inspired to try out the tool for yourself!
How Uber Poet works
The name Uber Poet was inspired by Android Studio Poet, which is a similar kind of app for Android we discovered after building our solution. Like Android Studio Poet, Uber Poet creates a mock application for iOS to test and benchmark your build system in various ways.
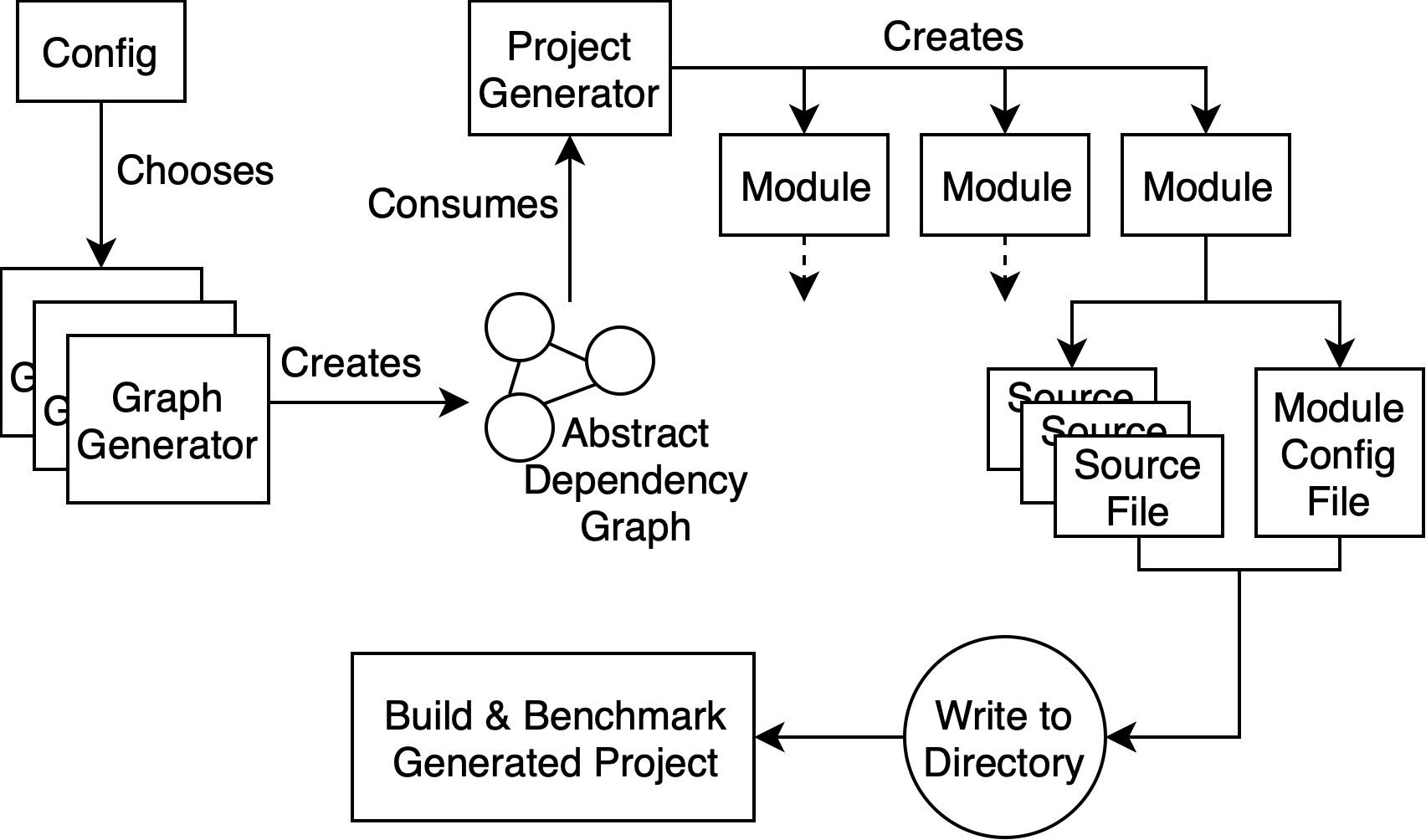
To accomplish this, Uber Poet first creates a dependency graph configured by command line options that are fed into it. The nodes of the dependency graph describe the dependencies between modules, how many lines of code each module represents, the names of modules, and which module is the root application node.
The graph generator then takes this graph and feeds it into a project generator, which then produces code for each module. The code and project metadata is then saved into a target directory. At Uber, we create Buck build files with Uber Poet. We then use Buck to generate Xcode project files with which to build the entire mock app. We can also use Buck directly to build our mock application, and Uber Poet could be extended to generate files for other build systems.
To create new dependency graphs for testing, Uber Poet enables us to create new graph generator functions. We also made a multi-suite tester in Uber Poet that tests all of our graph types along with multiple versions of Xcode and configuration options. We dump build time traces, logs, and a summary CSV file. With the build traces we can understand where bottlenecks occur for various graph types.
Graph generation types supported by Uber Poet
Uber Poet facilitates the creation of various types of graphs to depict mock apps. These graphs represent generation functions with configurable variables such as X, Y, and Z. Graph types include: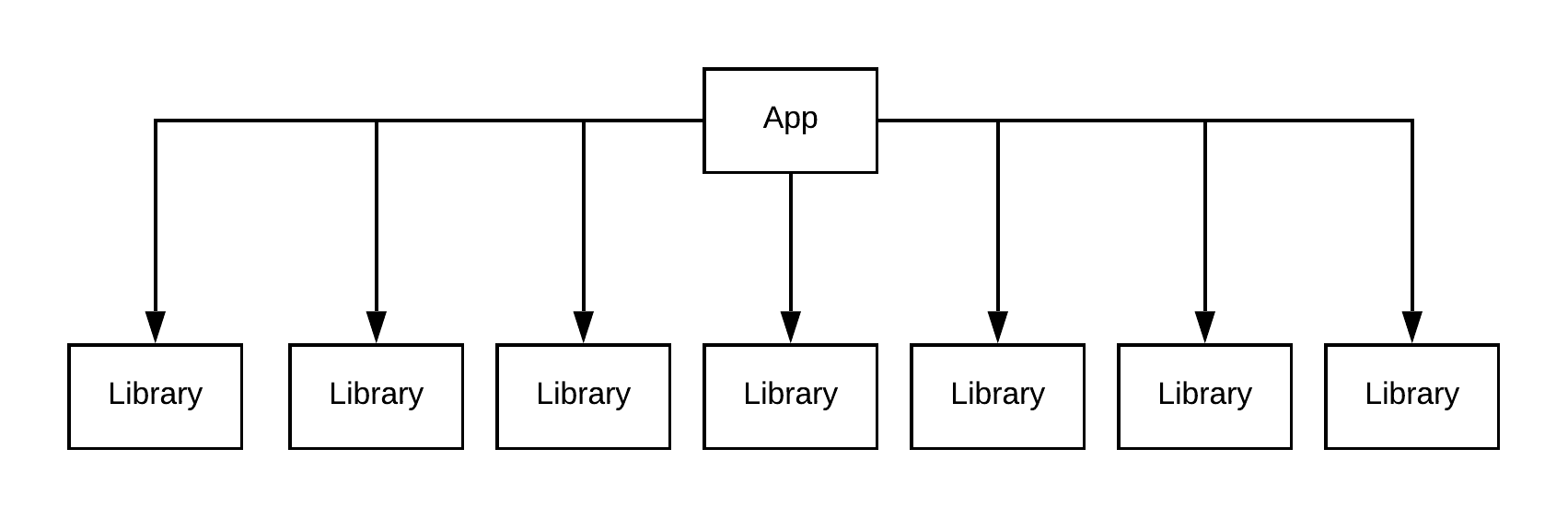
Flat graph types are X modules that don’t depend on anything. The top level app module depends on all of these modules.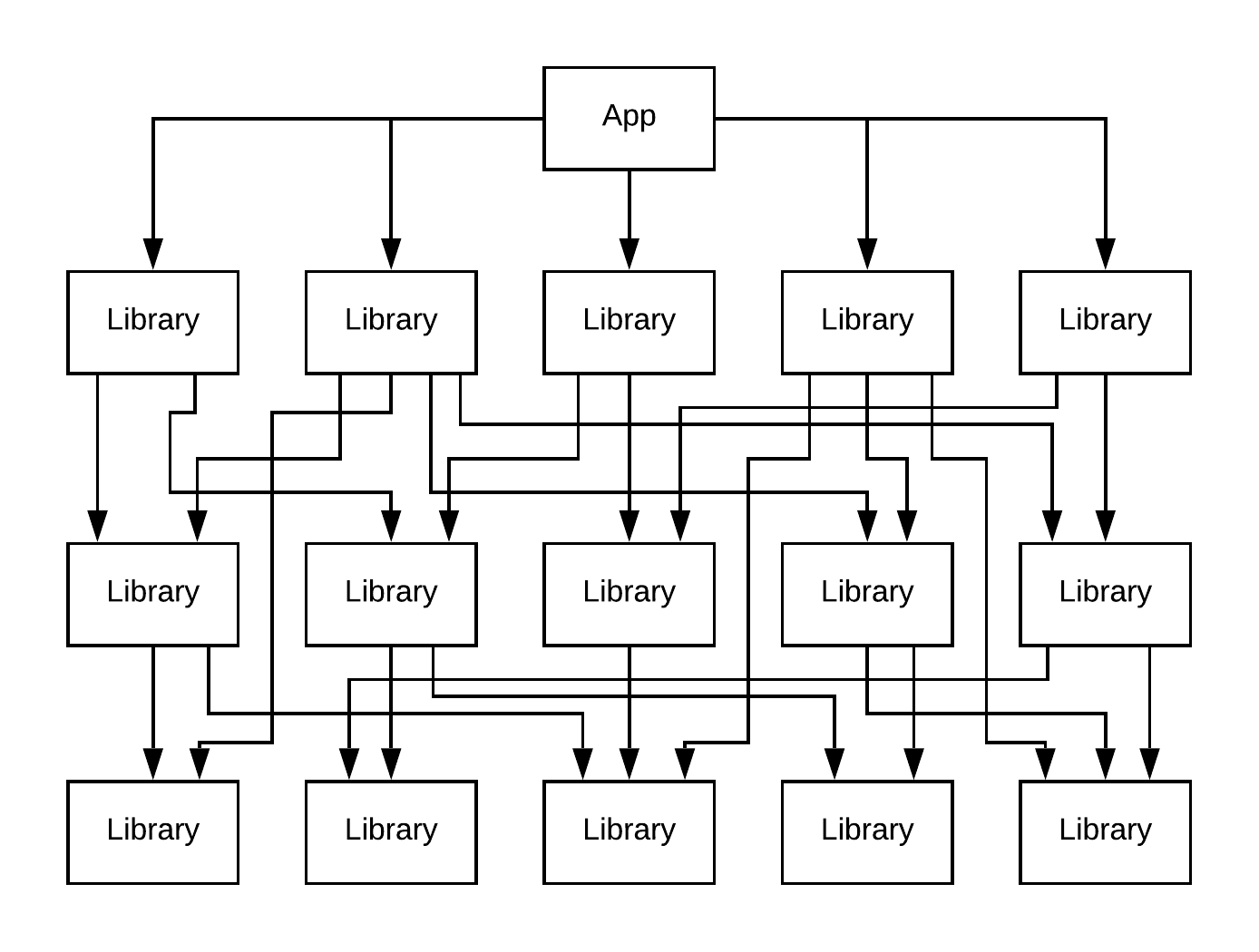 Layered graph types are X layers with a certain number of Y modules per layer. Each module depends on Z modules in the layers underneath its current layer. The top level app module depends on the top layer of this graph.
Layered graph types are X layers with a certain number of Y modules per layer. Each module depends on Z modules in the layers underneath its current layer. The top level app module depends on the top layer of this graph.
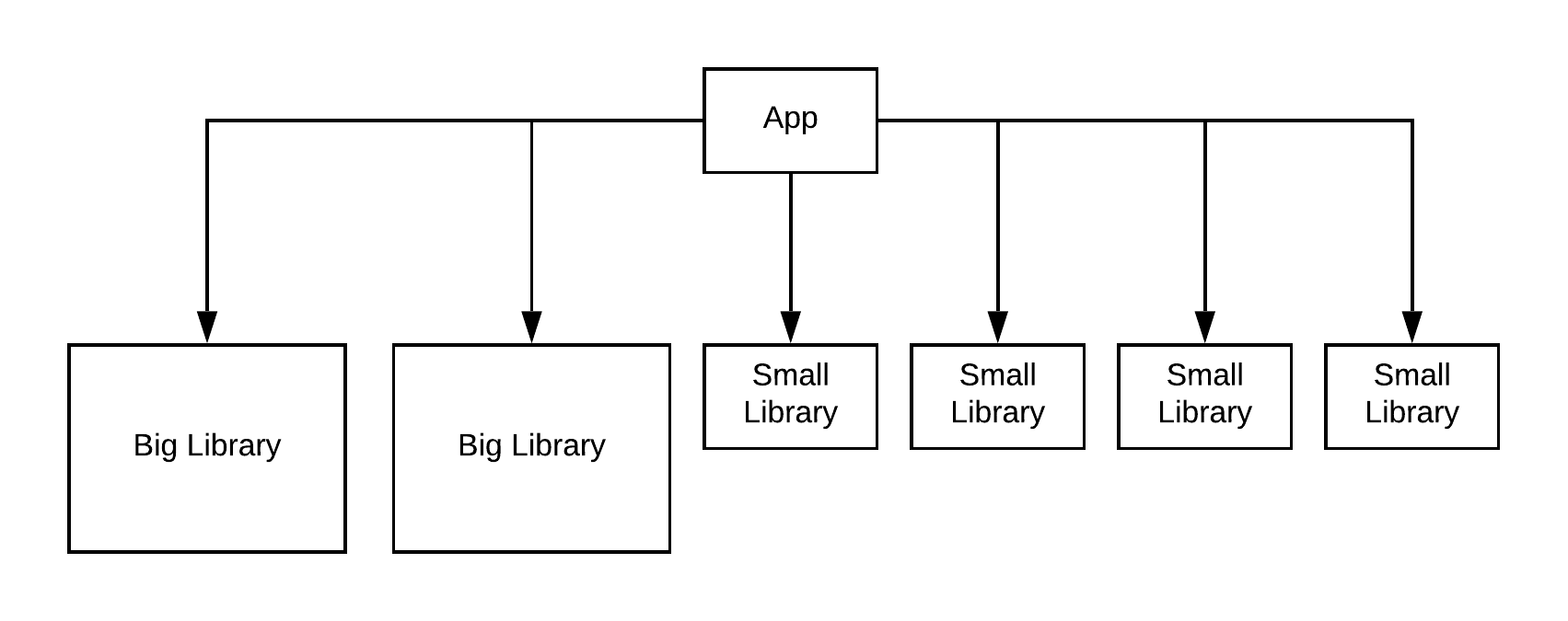
A Big Small Flat (bs_flat) graph is one set of X big ‘application’ modules and Y small ‘library’ modules. None of these library modules depend on each other. The top level app module depends on all of the big and small library modules.
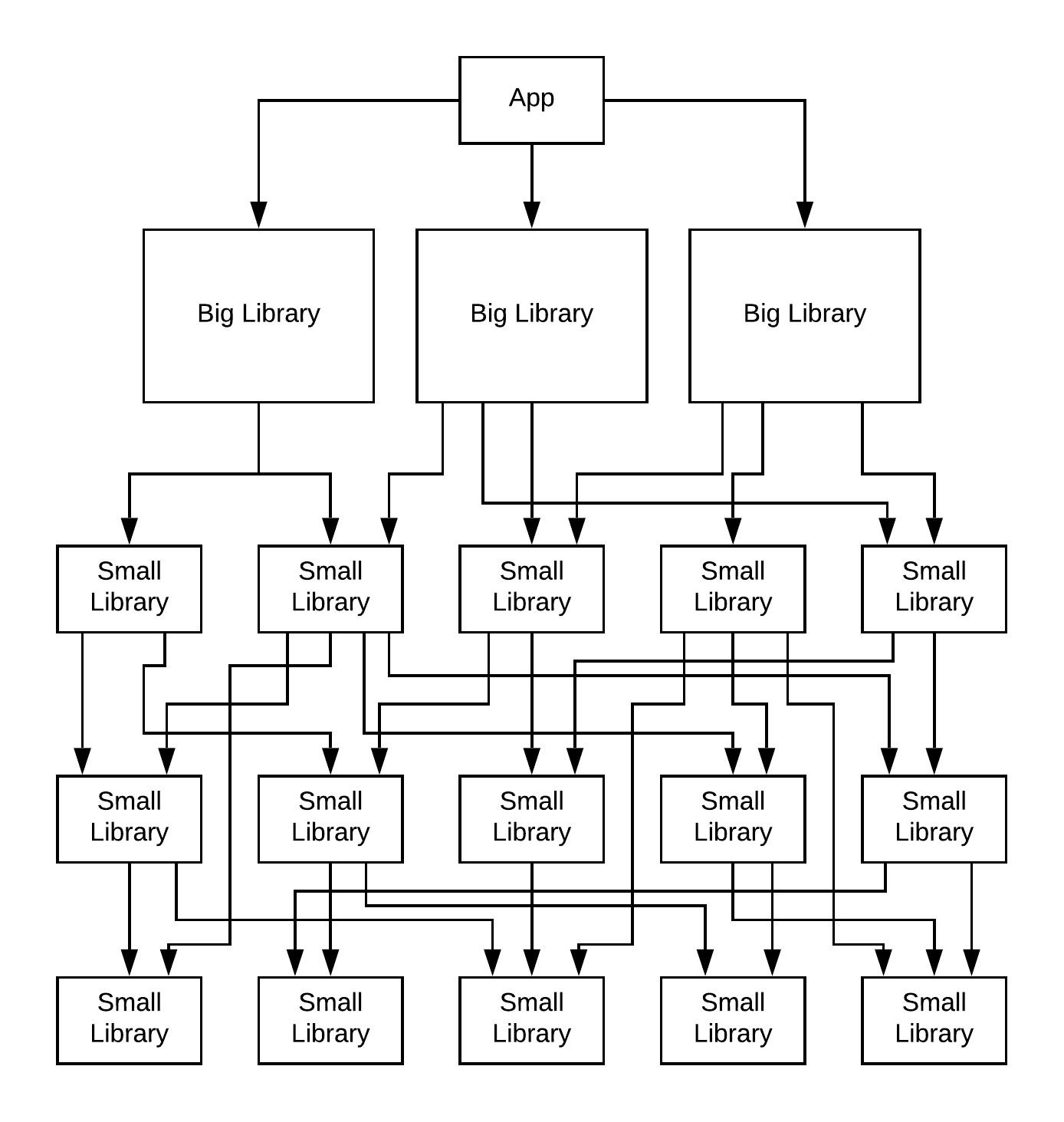
A Big Small Layered (bs_layered) graph is three layer groups stacked on top of each other in one graph. The top layer group is the app module, which depends on a flat layer of big modules. The big modules depend on the top layer of the graph generated by the layered graph function described above.
The dot file graph generator creates a graph described by a dot file. BUCK has an output mode that will generate a dot file description of your application’s module build graph.
We use those dot files to generate a mock app with the same dependency structure of our current apps. These mock apps do not exactly correspond to the same app structure of our real apps, since each module in a dot graph mock app are the same size.
Using Uber Poet
Uber Poet is a fairly simple command line application to use; to run it, all you need is a machine with macOS 10.13 or higher, Xcode, Buck, pipenv and optionally cloc. Cloc can be installed via the homebrew command: brew install cloc .
Then, we download the project from Github and run the Python scripts from the terminal app.
For example, we can create a simple mock application with genproj.py, from the Uber Poet GitHub project:
pipenv run ./genproj.py –output_directory “>$HOME/Desktop/mockapp”
–buck_module_path “/mockapp”
–gen_type flat
–lines_of_code 150000
Or benchmark all graph generation with multisuite.py:
pipenv run ./multisuite.py –log_dir “$HOME/Desktop/multisuite_build_results”
–app_gen_output_dir
“$HOME/Desktop/multisuite_build_results/app_gen”
We suggest you refer to the project README.md for the most up-to-date instructions.
Uber Poet use cases
Uber Poet is mostly useful as a benchmarking and testing tool for iOS app development at scale. Under this umbrella, you can use it to:
- Test new versions and build flags of the swift compiler in an automated fashion without having to migrate your current code base to the new version of swift.
- Project build times and binary size into the future as your application grows without having to write mock code yourself. As polynomial compiler algorithms and strategies reveal themselves, inflection points in build times might become evident at certain size points.
- Generate mock code for tests for other source code tools. For example, we used it to create a test fixture for Pear Patcher.
- Test if a new dependency tree architecture will result in significantly faster or slower build times without changing your app.
Benchmarking with Uber Poet
Armed with Uber Poet as well as our knowledge of Whole Module Optimization, batch build modes, and the tool’s graph generators, we tested which module architectures would perform the fastest.
To conduct this experiment, we ran our tests on a four core 2015 MacBook Pro. Each mock app we tested was close to 1.5 million lines of pure Swift code. All modules in the generated apps were equal in size except the bs_flat and bs_layered modes, which have modules that are 20 times bigger than the other, smaller modules. On average, we tested each build twice. Our results for each were very similar, so we decided not to run the builds a third time.
These were the unique configuration options we used for each graph type during the test:
- bs_flat: three big modules with 30 small modules with no dependencies between each other. Small module lines of code (LOC) count: 16’667 loc Big: 333’340 loc
- flat: 150 modules with no dependencies between each other. Modules were 10’000 loc each.
- layered: 150 modules in 10 layers that only depend on 5 random modules in lower layers. Modules were 10’000 loc each.
- bs_layered: Like layered with 30 modules, but one more layer added on top of it that are three large ‘application’ sized modules. Small module lines of code (LOC) count: 16’667 loc Big: 333’340 loc
- dot: ~350 equal sized modules that have the exact same dependency graph as Uber’s rider app. Unlike the rider app, the modules are of equal size. About 4285 loc per module.
Performance results
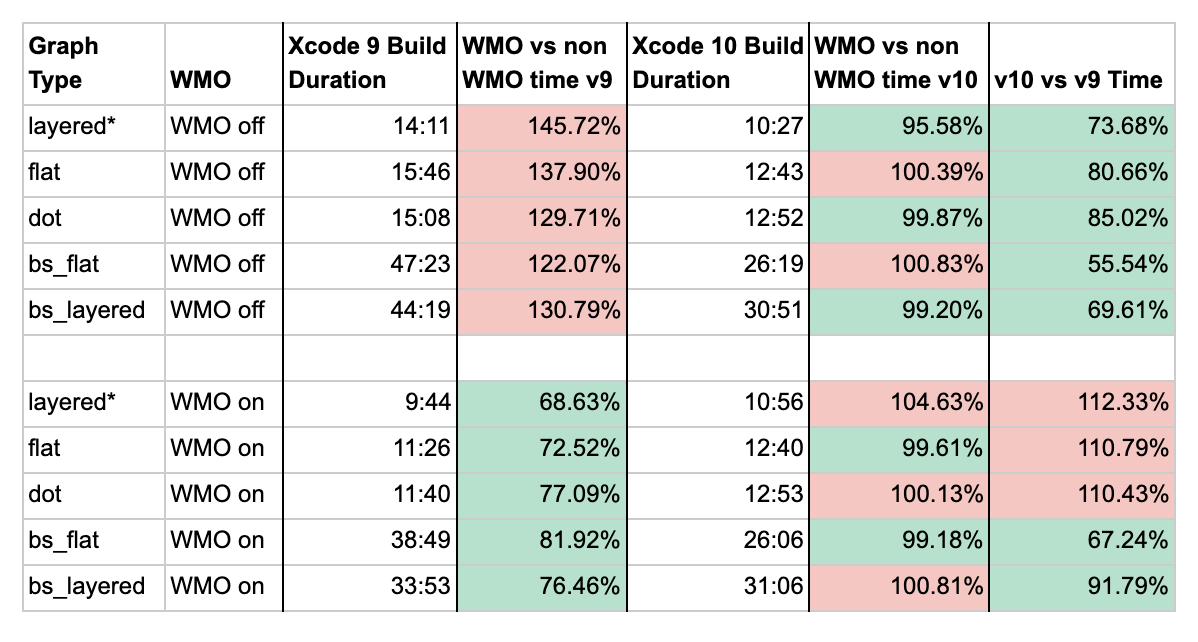
Below, we highlight the definitions of the above terms in the first row of our results:
- Graph Type: What type of graph was generated
- WMO: If all of the modules were configured as WMO modules or as standard (v9) or batch mode (v10) modules.
- Xcode 9 Build Duration: How long it took to build this configuration in Xcode 9 as an average of two builds.
- WMO vs non-WMO time v9: The ratio of time the build config took compared to it’s opposite type in Xcode 9. Ex: 120 percent in a WMO build means the WMO build took 1.2 times longer.
- Xcode 10 Build Duration: How long it took to build this configuration in Xcode 10 as an average of two builds.
- WMO vs non-WMO time v10: The ratio of time the build config took compared to its opposite type in Xcode 10. Ex: 120 percent in a WMO build means the WMO build took 1.2 times longer compared to its non-WMO equivalent.
- V10 vs v9 Time: The ratio of time that the build config took compared to the other version. Ex: 73 percent means the Xcode 10 version only took 73 percent of the time compared to the Xcode 9 version.
Keeping the line code count about equal between module architectures, we found that the big small module structure is slower than the many small modules architecture we currently use at Uber.
We also found that Swift 4.0 significantly improves build times for the big small architecture. Batch mode also builds about as fast as WMO mode in Xcode 10 compared to Xcode 9. In Xcode 9, standard mode takes about 1.4 times more time than WMO mode. During our tests, Swift 4.0 WMO build mode takes 1.1 times more time than Swift 3.0 WMO mode, which is a performance regression.
The layered graph type is faster than the flat type in this experiment because it chooses a set of five random modules in layers below it to depend on. With 150 modules, this leads to 10 to 20 percent of modules not being connected to the main dependency graph because of statistical probabilities. Disconnected modules are never built, leading to faster build times. If you manually hook up these disconnected modules to the main graph, the layered graph type takes about the same amount of time as the flat type.
While Uber Poet didn’t reveal any faster way to reconfigure our dependency tree to improve build times, it at least it saved us from doing a high effort refactor that would have given us worse build times.
Speeding up build times at Uber
In Uber’s actual app, batch mode adds about a 25 percent slow-down with our current module architecture written in Swift 4.0 if we turn it on for all modules. In a separate analysis, we compared how long a module took to individually build in WMO mode compared to batch mode in our builds. When we did this, we found a collection of about five modules in each application that decreased total build time when we turned on batch mode just for them.
Another project we have recently deployed involves leveraging Buck to pre-build various modules of our app as binary libraries. This reduces the amount of code Xcode would have to index or build in an edit, build, run, and test loop. Developers can choose which modules to build as binary modules and which modules to keep as source files via command line options. We estimate developers will choose libraries they don’t frequently edit, frozen third party libraries, and code-generated modules for things like network models and test mocks.
Moving forward
Since our hypothesis that a typical application dependency graph would be faster to build was proven wrong, we do not plan to add more simulation improvements to Uber Poet at this time. However, we encourage you to submit your own simulation improvements and other project ideas via pull request.
If you are interested in working on open source developer tooling like this on either Android or iOS, consider joining Uber’s mobile engineering team.
Posted by Mahyar McDonald
Related articles



Most popular

Presto® Express: Speeding up Query Processing with Minimal Resources

Unified Checkout: Streamlining Uber’s Payment Ecosystem

The Accounter: Scaling Operational Throughput on Uber’s Stateful Platform

Introducing the Prompt Engineering Toolkit
Products
Company