Introducing the Plato Research Dialogue System: A Flexible Conversational AI Platform
16 July 2019 / Global
Intelligent conversational agents have evolved significantly over the past few decades, from keyword-spotting interactive voice response (IVR) systems to the cross-platform intelligent personal assistants that are becoming an integral part of daily life.
Along with this growth comes the need for intuitive, flexible, and comprehensive research and development platforms that can act as open testbeds to help evaluate new algorithms, quickly prototype, and reliably deploy conversational agents.
At Uber AI, we developed the Plato Research Dialogue System, a platform for building, training, and deploying conversational AI agents that allows us to conduct state of the art research in conversational AI and quickly create prototypes and demonstration systems, as well as facilitate conversational data collection. We designed Plato for both users with a limited background in conversational AI and seasoned researchers in the field by providing a clean and understandable design, integrating with existing deep learning and Bayesian optimization frameworks (for tuning the models), and reducing the need to write code.
There have been numerous efforts to develop such platforms for general research or specific use cases, including Olympus, PyDial, ParlAI, the Virtual Human Toolkit, Rasa, DeepPavlov, ConvLab, among others. When assessing whether or not to leverage these tools, we found that many entail that users be familiar with the platform-specific source code, focus on specific use cases and neither flexibly nor scalably support others, and require licenses to use.
Plato was designed to address these needs and can be used to create, train, and evaluate conversational AI agents for a variety of use cases. It supports interactions through speech, text, or structured information (in other words, dialogue acts), and each conversational agent can interact with human users, other conversational agents (in a multi-agent setting), or data. Perhaps most significantly, Plato can wrap around existing pre-trained models for every component of a conversational agent, and each component can be trained online (during the interaction) or offline (from data).
How does the Plato Research Dialogue System work?
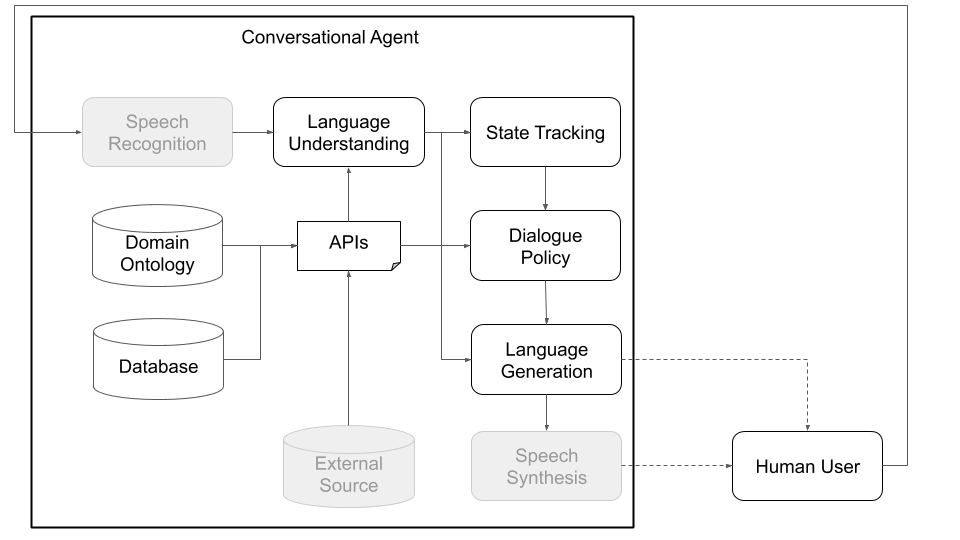
Conceptually, a conversational agent needs to go through various steps in order to process information it receives as input (e.g., “What’s the weather like today?”) and produce an appropriate output (“Windy but not too cold.”). The primary steps, which correspond to the main components of a standard architecture (see Figure 1), are:
- Speech recognition (transcribe speech to text)
- Language understanding (extract meaning from that text)
- State tracking (aggregate information about what has been said and done so far)
- API call (search a database, query an API, etc.)
- Dialogue policy (generate abstract meaning of agent’s response)
- Language generation (convert abstract meaning into text)
- Speech synthesis (convert text into speech)
Plato has been designed to be as modular and flexible as possible; it supports traditional as well as custom conversational AI architectures, and importantly, enables multi-party interactions where multiple agents, potentially with different roles, can interact with each other, train concurrently, and solve distributed problems.
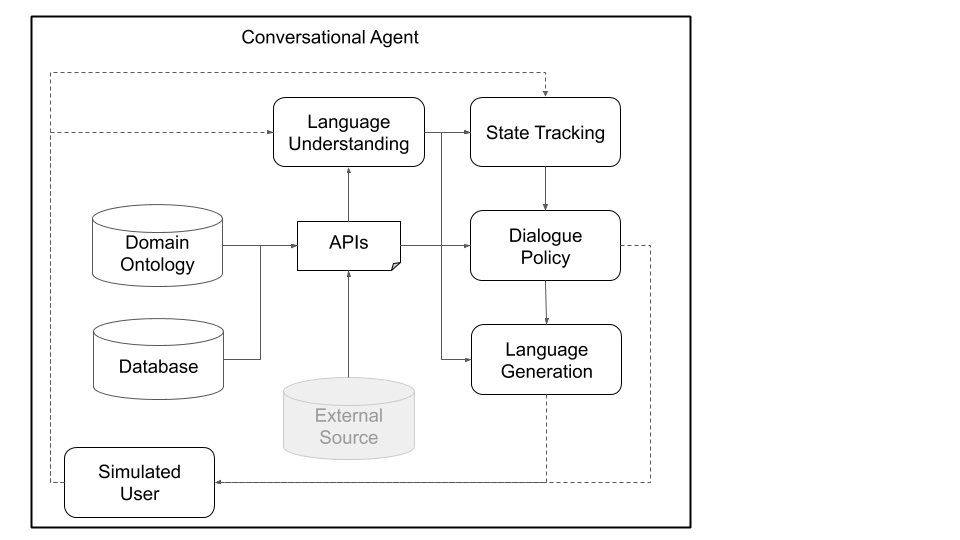
Figures 1 and 2, below, depict example Plato conversational agent architectures when interacting with human users and with simulated users. Interacting with simulated users is a common practice used in the research community to jump-start learning (i.e., learn some basic behaviors before interacting with humans). Each individual component can be trained online or offline using any machine learning library (for instance, Ludwig, TensorFlow, or PyTorch) as Plato is a universal framework. Ludwig, Uber’s open source deep learning toolbox, makes for a good choice, as it does not require writing code and is fully compatible with Plato.
In addition to single-agent interactions, Plato supports multi-agent conversations where multiple Plato agents can interact with and learn from each other. Specifically, Plato will spawn the conversational agents, make sure that inputs and outputs (what each agent hears and says) are passed to each agent appropriately, and keep track of the conversation.
This set-up can facilitate research in multi-agent learning, where agents need to learn how to generate language in order to perform a task, as well as research in sub-fields of multi-party interactions (dialogue state tracking, turn taking, etc.). The dialogue principles define what each agent can understand (an ontology of entities or meanings; for example: price, location, preferences, cuisine types, etc.) and what it can do (ask for more information, provide some information, call an API, etc.). The agents can communicate over speech, text, or structured information (dialogue acts) and each agent has its own configuration. Figure 3, below, depicts this architecture, outlining the communication between two agents and the various components:
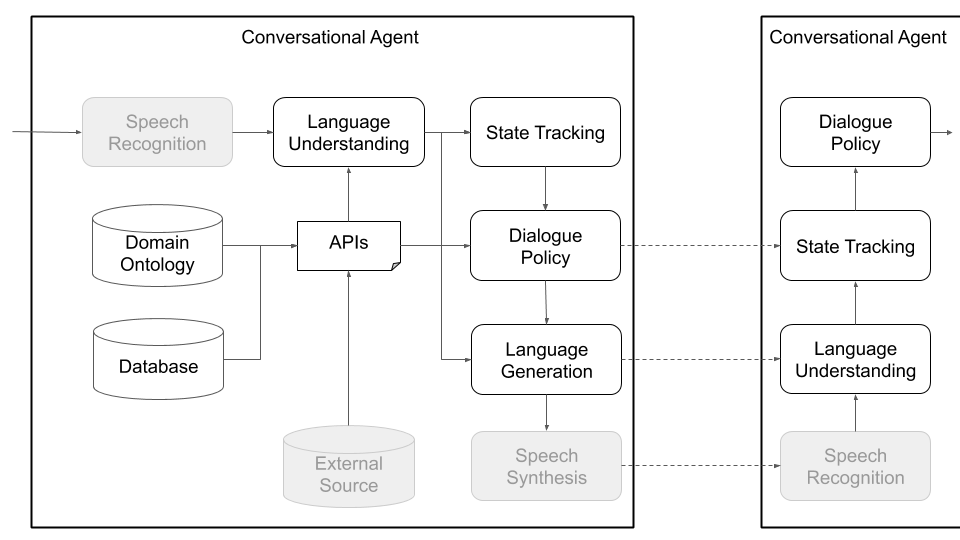
Finally, Plato supports custom architectures (e.g., splitting NLU into multiple independent components) and jointly-trained components (e.g., text-to-dialogue state, text-to-text, or any other combination) via the generic agent architecture shown in Figure 4, below:

This mode moves away from the standard conversational agent architecture and supports any kind of architecture (e.g., with joint components, text-to-text or speech-to-speech components, or any other set-up) and allows loading existing or pre-trained models into Plato.
Users can define their own architecture and/or plug their own components into Plato by simply providing a Python class name and package path to that module, as well as the model’s initialization arguments. All the user needs do is list the modules in the order they should be executed and Plato takes care of the rest, including wrapping the input/output, chaining the modules, and handling the dialogues. Plato supports both serial and parallel execution of modules.
Plato also provides support for Bayesian optimization of conversational AI architectures or individual module parameters through Bayesian Optimization of Combinatorial Structures (BOCS).
Conversational agents with Plato
No actual installation is necessary in this version of Plato (v. 0.1), as it allows users to modify parts of the code or extend existing use cases for greater flexibility. However, Plato does depend on some external libraries and these need to be installed. Follow the two steps below to complete the process:
Note: The Plato Research Dialogue System has been developed with Python 3.
- Clone the repository:
git clone
git@github.com:uber-research/plato-research-dialogue-system.git
- Install the requirements:
For MacOS:
brew install portaudio
pip install -r requirements.txt
For Ubuntu/Debian:
sudo apt-get install python3-pyaudio
pip install -r requirements.tx
For Windows:
pip install -r requirements.txt
To support speech it is necessary to install PyAudio, which has a number of dependencies that might not exist on a developer’s machine. If the steps above are unsuccessful, this poston a PyAudio installation error includes instructions on how to get these dependencies and install PyAudio.
Solutions to other common installation issues can be found at CommonIssues.md.
- Run Plato Research Dialogue System!
See below for a quick introduction to the configuration files and how to run a Plato agent.
Running Plato agents
To run a Plato conversational agent, the user must run the following command with the appropriate configuration file (see Examples/simulate_agenda.yaml for an example configuration file which contains a number of settings on the environment and the agent(s) to be created as well as their components):
python runPlatoRDS.py -config <PATH TO yaml CONFIG FILE>
Some example modes and configurations are listed below:
Running a single Plato agent
- To run a simulation using the agenda based user simulator in the Cambridge Restaurants domain:
python runPlatoRDS.py -config Examples/config/simulate_agenda.yaml
- To run a text based interaction using the agenda based simulator in the Cambridge Restaurants domain:
python runPlatoRDS.py -config Examples/config/simulate_text.yaml
- To run a speech based interaction using the agenda based simulator in the Cambridge Restaurants domain:
python runPlatoRDS.py -config Examples/config/simulate_speech.yaml
Running multiple Plato agents
One of Plato’s main features allows two agents to interact with each other. Each agent can have a different role (for instance, system and user), different objectives, and receive different reward signals. If the agents are cooperating, some of these can be shared (e.g., what constitutes a successful dialogue). (In the future, we plan to build support for Plato to enable interaction between more than two agents at a time.)
For example, to run multiple Plato agents on the benchmark Cambridge Restaurants domain, we run the following commands to train the agents’ dialogue policies and test them:
Training phase
python runPlatoRDS.py -config Examples/config/CamRest_MA_train.yaml
Testing phase
python runPlatoRDS.py -config Examples/config/CamRest_MA_test.yaml
Running generic Plato agents
Most of the discussion and examples in this article revolve around the traditional conversational agent architecture. Plato, however, does not need to adhere to that pipeline; its generic agents support any range of custom modules, from splitting natural language understanding into many components to having multiple components running in parallel to having just a single text-to-text model.
Generic agents allow users to load their custom modules as Python class objects. For each module listed in the configuration file, Plato will instantiate the class using the given path and arguments. Then, during each dialogue turn, the generic agent will sequentially call each module (in the order provided in its configuration file) and will pass the output of the current module to the next module in the list. The generic agent will return the last module’s output.
The following are two examples of running a single Plato agent or multiple Plato agents in the generic module mode:
- Single generic agent, used to implement custom architectures or to use existing, pre-trained statistical models:
python runPlatoRDS.py -config Examples/config/simulate_agenda_generic.yaml
- Multiple generic agents, same as above but for multiple agents (assuming you have trained dialogue policies using Examples/config/CamRest_MA_train.yaml):
python runPlatoRDS.py -config Examples/config/MultiAgent_test_generic.yaml
Training from data
Plato supports the training of agents’ internal components in an online (during the interaction) or offline (from data) manner, using any deep learning framework. Virtually any model can be loaded into Plato as long as Plato’s interface Input/Output is respected; for example, if a model is a custom NLU it simply needs to inherit from Plato’s NLU abstract class, implement the necessary functions and pack/unpack the data into and out of the custom model.
Plato internal experience
To facilitate online learning, debugging, and evaluation, Plato keeps track of its internal experience in a structure called the Dialogue Episode Recorder, which contains information about previous dialogue states, actions taken, current dialogue states, utterances received and utterances produced, rewards received, and a few other structs including a custom field that can be used to track anything else that cannot be contained by the aforementioned categories
At the end of a dialogue or at specified intervals, each conversational agent will call the train() function of each of its internal components, passing the dialogue experience as training data. Each component then picks the parts it needs for training.
To use learning algorithms that are implemented inside Plato, any external data, such as DSTC2 data, should be parsed into this Plato experience so that they may be loaded and used by the corresponding component under training.
Alternatively, users may parse the data and train their models outside of Plato and simply load the trained model when they want to use it for a Plato agent.
Training online
Training online is as easy as flipping the ‘Train’ flags to ‘True’ in the configuration for each component users wish to train.
To train from data, users simply need to load the experience they parsed from their dataset. As an example of offline training in Plato, we will use the DSTC2 dataset, which can be obtained from the 2nd Dialogue State Tracking Challenge website.
The runDSTC2DataParser.py script will parse the DSTC2 data and save it as a Plato experience. It will then load that experience and train a supervised policy:
python runDSTC2DataParser.py -data_path <PATH_TO_DSTC2_DATA>/dstc2_traindev/data/
The trained policies can be tested using the following configuration file:
python runPlatoRDS.py -config
Examples/config/simulate_agenda_supervised.yaml
Note: Users may load experiences from past interactions or from data into Plato and then keep training their model with reinforcement learning or other learning methods.
Training with Plato and Ludwig
Released by Uber, Ludwig is an open source deep learning framework that allows users to train models without writing any code. Users only need to parse their data into CSV files, create a Ludwig configuration file, and then simply run a command in the terminal. Ludwig configuration files, written in YAML, describe the architecture of the neural network, which features to use from the CSV file, and other parameters.
In the previous section, the runDSTC2DataParser.py actually generated some CSV files that can be used to train natural language understanding and generation, which can be found at: Data/data. As an example, we will see how to train the system-side natural language generator. For that, users need to write a yaml configuration file, similar to that shown below:
Input_features:
name: nlg_input
type: sequence
encoder: rnn
cell_type: lstm
Output_features:
name: nlg_output
type: sequence
decoder: generator
cell_type: lstm
training:
epochs: 20
learning_rate: 0.001
dropout: 0.2
and train their model:
ludwig experiment –model_definition_file Examples/config/ludwig_nlg_train.yaml –data_csv
Data/data/DSTC2_NLG_sys.csv –output_directory Models/CamRestNLG/Sys/
The next step is to load the model in Plato. Users should go to the simulate_agenda_nlg.yaml configuration file and update the path to the Ludwig model if necessary:
…
NLG:
nlg: CamRest
model_path: <PATH_TO_YOUR_LUDWIG_MODEL>/model
…
and test that the model works:
python runPlatoRDS.py -config
Examples/config/simulate_agenda_nlg.yaml
Remember that Ludwig will create a new experiment_run_i directory each time it is called, so users need to make sure the model’s path in Plato’s configuration file is up to date.
Ludwig also offers a method to train models online, so in practice users need to write very little code to build, train, and evaluate a new deep learning component in Plato.
Generating new domains for Plato agents
In order to build a conversational agent for task-oriented applications such as slot-filling, users need a database of items and an ontology describing their domain. Plato provides a script for automating this process.
Let’s say for example that a user wants to build a conversational agent for an online flower shop, with the following items in a CSV file:
item_id,type,color,price,occasion
1,rose,red,1,any
2,rose,white,2,anniversary
3,rose,yellow,2,celebration
4,lilly,white,5,any
5,orchid,pink,30,any
6,dahlia,blue,15,any
Users can simply call createSQLiteDB.py to automatically generate a DB SQL file and a JSON ontology file. Users may specify informable, requestable, and system-requestable slots in the configuration file, as depicted below:
—
GENERAL:
csv_file_name: Data/data/flowershop.csv
db_table_name: estore
db_file_path: Ontology/Ontologies/flowershop.db
ontology_file_path: Ontology/Ontologies/flowershop.json
ONTOLOGY:
informable_slots: [type, price, occasion]
requestable_slots: [price, color]
system_requestable_slots: [price, occasion]
Note: The ‘ONTOLOGY’ part is optional. If not provided, the script will assume all slots are informable, requestable, and system requestable.
and run the script:
python createSQLiteDB.py -config
Examples/config/create_flowershop_DB.yaml
A flowershop-rules.json and a flowershop-dbase.db can now be found at Domain/Domains/.
We can now simply run Plato with dummy components and interact with a simple agent as a sanity check:
python runPlatoRDS.py -config
Examples/config/flowershop_text.yaml
Generating new modules for Plato agents
There are two ways to create a new module depending on its function. If a module implements a new way of performing NLU or dialogue policy, then the user should write a class that inherits from the corresponding abstract class.
If, however, a module does not fit one of the single agent basic components, for example, it performs Named Entity Recognition or predicts dialogue acts from text, then the user must write a class that inherits from the ConversationalModule directly, which can then only be used by the generic agents.
Inheriting from abstract classes
Users need to create a new class inheriting from the corresponding Plato abstract class and implement the interface defined by the abstract class and any other functionality they wish. This class should have a unique name (e.g. ‘myNLG’) that will be used to distinguish it from other options when parsing the configuration file. At this version of Plato, users will need to manually add some conditions where the configuration files are being parsed (e.g. in the Conversational Agent, Dialogue Manager, etc.) unless the generic agent is used.
Constructing a new module
To construct a new module, the user must add their code to a new class inheriting from the conversational module. They can then load the module via a generic agent by providing the appropriate package path, class name, and arguments in the configuration.
…
MODULE_i:
package: myPackage.myModule
Class: myModule
arguments:
model_path: Models/myModule/parameters/
…
…
Users are responsible for guaranteeing that a new module can appropriately process output of preceding modules and that the new module’s output can be appropriately consumed by following modules, as provided in its generic configuration file.
Next steps
Plato, a research project from Uber AI, was used to facilitate work to be presented at SIGDial 2019 about concurrently training two conversational agents that talk to each other via self-generated language. In this work, we leverage Plato to easily train a conversational agent how to ask for restaurant information and another agent how to provide such information; over time, their conversations become more and more natural.
We believe that Plato has the capability to more seamlessly train conversational agents across deep learning frameworks, from Ludwig and TensorFlow to PyTorch, Keras, and other open source projects, leading to improved conversational AI technologies across academic and industry applications.
Learn more about using the Plato Research Dialogue System by reading through our complete documentation.
Plato Research Dialogue System source code is shared under a non-commercial license for research purposes only.
If you are excited about the research we do, consider applying for a role with Uber AI.
Special thanks to Piero Molino, Michael Pearce, and Gokhan Tur for their contributions and support.

Alexandros Papangelis
Alexandros Papangelis is a senior research scientist at Uber AI, on the Conversational AI team; his interests include statistical dialogue management, natural language processing, and human-machine social interactions. Prior to Uber, he was with Toshiba Research Europe, leading the Cambridge Research Lab team on Statistical Spoken Dialogue. Before joining Toshiba, he was a postdoctoral fellow at CMU's Articulab, working with Justine Cassell on designing and developing the next generation of socially-skilled virtual agents. He received his PhD from the University of Texas at Arlington, MSc from University College London, and BSc from the University of Athens.

Yi-Chia Wang
Yi-Chia Wang is a research scientist at Uber AI, focusing on the conversational AI. She received her Ph.D. from the Language Technologies Institute in School of Computer Science at Carnegie Mellon University. Her research interests and skills are to combine language processing technologies, machine learning methodologies, and social science theories to statistically analyze large-scale data and model human-human / human-bot behaviors. She has published more than 20 peer-reviewed papers in top-tier conferences/journals and received awards, including the CHI Honorable Mention Paper Award, the CSCW Best Paper Award, and the AIED Best Student Paper Nomination.

Mahdi Namazifar
Mahdi Namazifar is a tech lead for Uber's NLP & Conversational AI team.

Chandra Khatri
Chandra Khatri is a senior research scientist at Uber AI focused on Conversational AI. Currently, he is interested in making AI systems smarter and scalable while addressing the fundamental challenges pertaining to understanding and reasoning. Prior to Uber, he was the Lead Scientist at Alexa at Amazon and was driving the science leg of the Alexa Prize Competition, which is a university competition for advancing the state of Conversational AI. Prior to working on Alexa, he was a research scientist at eBay, where he led various deep learning and NLP initiatives within the eCommerce domain.
Posted by Alexandros Papangelis, Yi-Chia Wang, Mahdi Namazifar, Chandra Khatri
Related articles




Most popular

Making Uber’s ExperimentEvaluation Engine 100x Faster

Genie: Uber’s Gen AI On-Call Copilot

Open Source and In-House: How Uber Optimizes LLM Training

Horacio’s story: gaining mobility independence through innovative transportation solutions
Products
Company