
Background
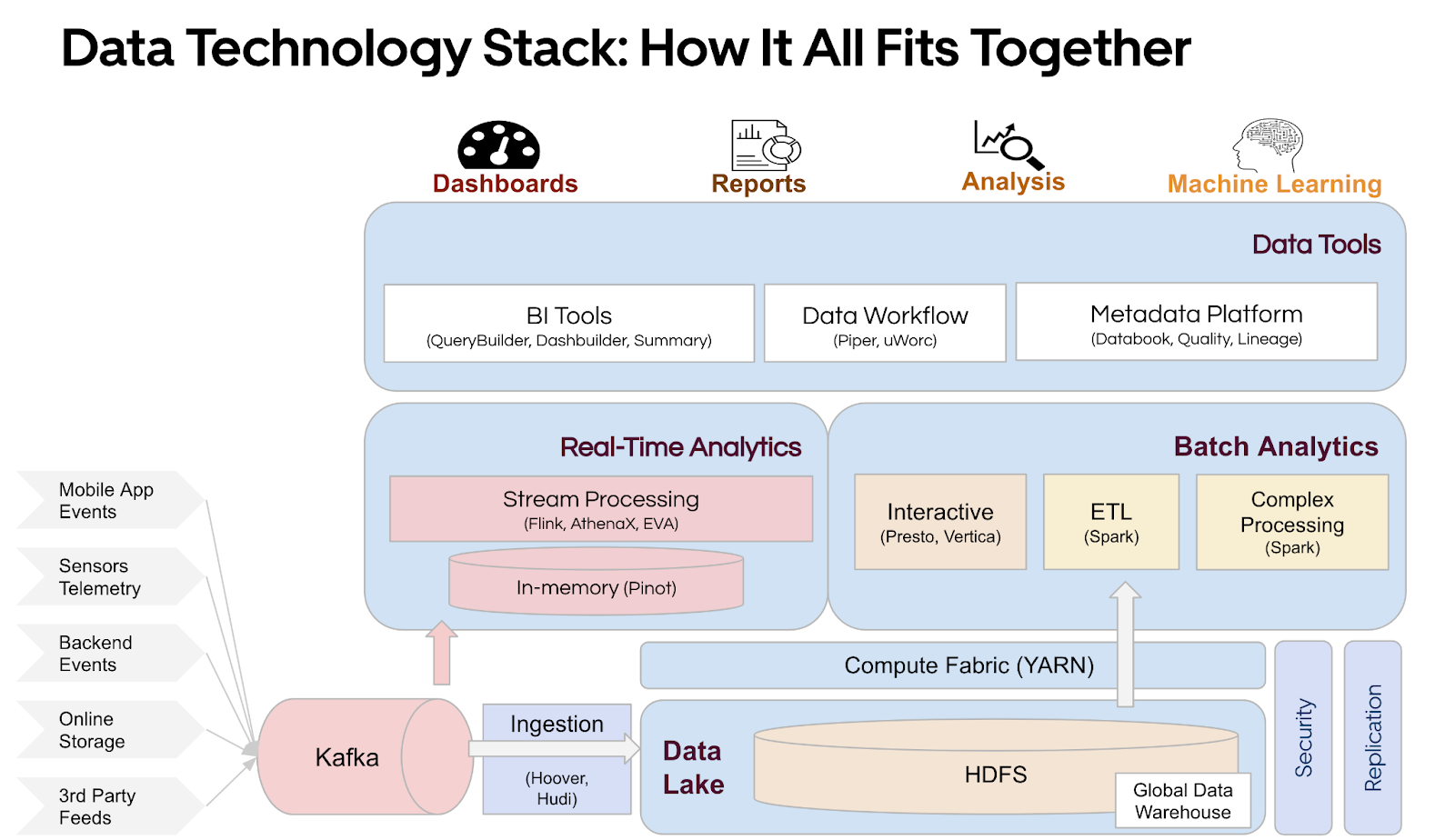
Uber’s data ecosystem comprises a complex and diverse big data landscape, operating at exabyte-scale and composed of a wide variety of tools to cater to each need such as ingestion layer (Apache Kafka®) and real-time compute (Apache Flink®), real-time analytics (Apache Pinot™), batch compute and aggregation layer (Spark ETL, Presto ETL, uWorc), batch analytics (Query Builder), ML studio (For building ML models), visualization (Tableau, Google Studio), different types of data stores (DocStore, MySQL™, Apache Hive™, Apache Hudi, TerraBlob), etc.
In 2023, the Uber Data platform migrated all batch workloads to Apache Spark™-based computation. Around 20,000+ critical pipelines and datasets are used to power the batch workloads and more than 3,000+ engineers are responsible for creating pipelines and owning datasets.
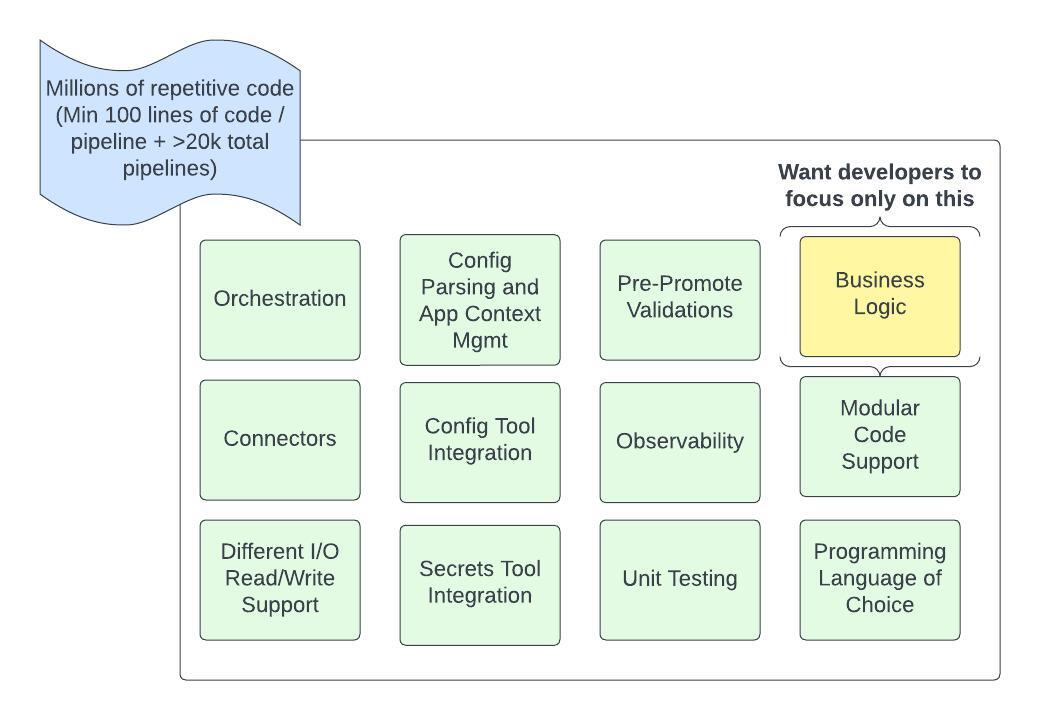
Why an ETL Framework
Uber has standardized the backend development flow where 5,000+ services are being built and managed by thousands of backend engineers. JFX is the application framework built on top of Java Spring Boot service and UberFx is the framework built for GO language-based service to assist developers in improving productivity. These frameworks make it easy for developers to write composable, testable apps using dependency injection. It removes boilerplate, global state, and package-level init functions. This also eliminates the need for service owners to install and manage individual libraries manually and provides multiple components as a package out of the box during service bootstrapping.
Similar complexities exist in the data world, but the data development cycle is not standardized, unlike backend or mobile development. Also, the concept of test-driven development in ETL is non-existent. More than 90% of the pipelines do not have any unit test cases available during development and the testing usually happens in the staging layer.
We wanted to implement a framework model similar to the one used in the backend into the data development lifecycle. This would allow developers to focus solely on writing business logic while eliminating the need for repetitive code common in pipeline writing. Additionally, we aim to provide a unit testing framework that requires minimal configuration, allowing for better pipeline test coverage.
The below diagram depicts the components that are expected to be packaged as part of an ETL tool:
Industry Trends
The industry is also moving towards writing ETL jobs similarly to any other software development practice, with features such as modular ETL, test-driven development, data quality checks, observability, version control, etc. One such tool that is popular among the data community is DBT. However, introducing a new ETL tool other than Spark for this problem would be challenging due to the complex Uber data ecosystem, scale of the data, developer language preference, and an increased developer learning curve. The challenge is to add new features that meet industry standards without disrupting the existing Uber developer experience.
To address these challenges, the Sparkle framework was developed. This framework was written on top of native Apache Spark™, simplifying Spark pipeline development and testing, while still making the best use of Spark’s capabilities. The framework supports writing configuration-based modular ETL jobs and incorporates test-driven ETL development, which aligns with current industry trends.
Sparkle provides boilerplate code and various source and sink integrations out of the box so that the ETL developer can just focus on writing the business logic expressed in either SQL or Java/Scala/Python-based procedural blocks.
Architecture


Introduction to Modular ETL
The core concept behind Sparkle architecture is the ability for users to express business logic as a sequence of modules. Each module in a Sparkle framework is a unit of transformation that can be expressed either as SQL, procedural code, or data extracted from any external data source.
The below snippet depicts the sample module configuration defined in Sparkle base YAML:

All the modules are defined as sequences under workflow config. In the sqlFile module (source: sqlFile), the SQLs are expressed as Jinja templates, and the properties loaded in the application context are accessible either as template variables in the SQLs or accessed as Environment variables in the procedural module (source: classTransformation). The module output gets stored as a Spark temp table using the variable outputTableName, which gets referred to in subsequent modules. Configs defined under UDFs are used to register any Spark or Hive UDFs in the Spark context.
The below snippet depicts the Jinja template-based sample SQL file:

The below snippet depicts the sample procedural transformation block in Java:

As the final step, the defined module outputs, which are stored as Spark Temp-table, can be persisted to different target sinks by defining the required write configs via Env YAML.
The below snippet depicts the sample Env YAML:

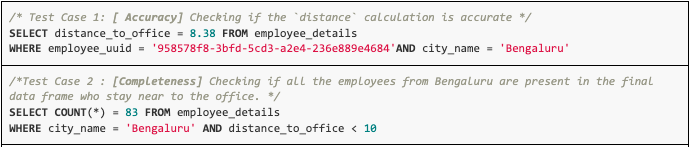
After the creation of the pipeline, Sparkle provides an option for users to test the pipeline locally both at the level of each module and of the entire pipeline. Users can test their pipeline by providing the required mock data as table inputs, any test-specific configs, and the necessary assertions defined as SQL queries.
The below snippet depicts the sample SQL assertions used in unit testing:
Before vs After Sparkle Flow
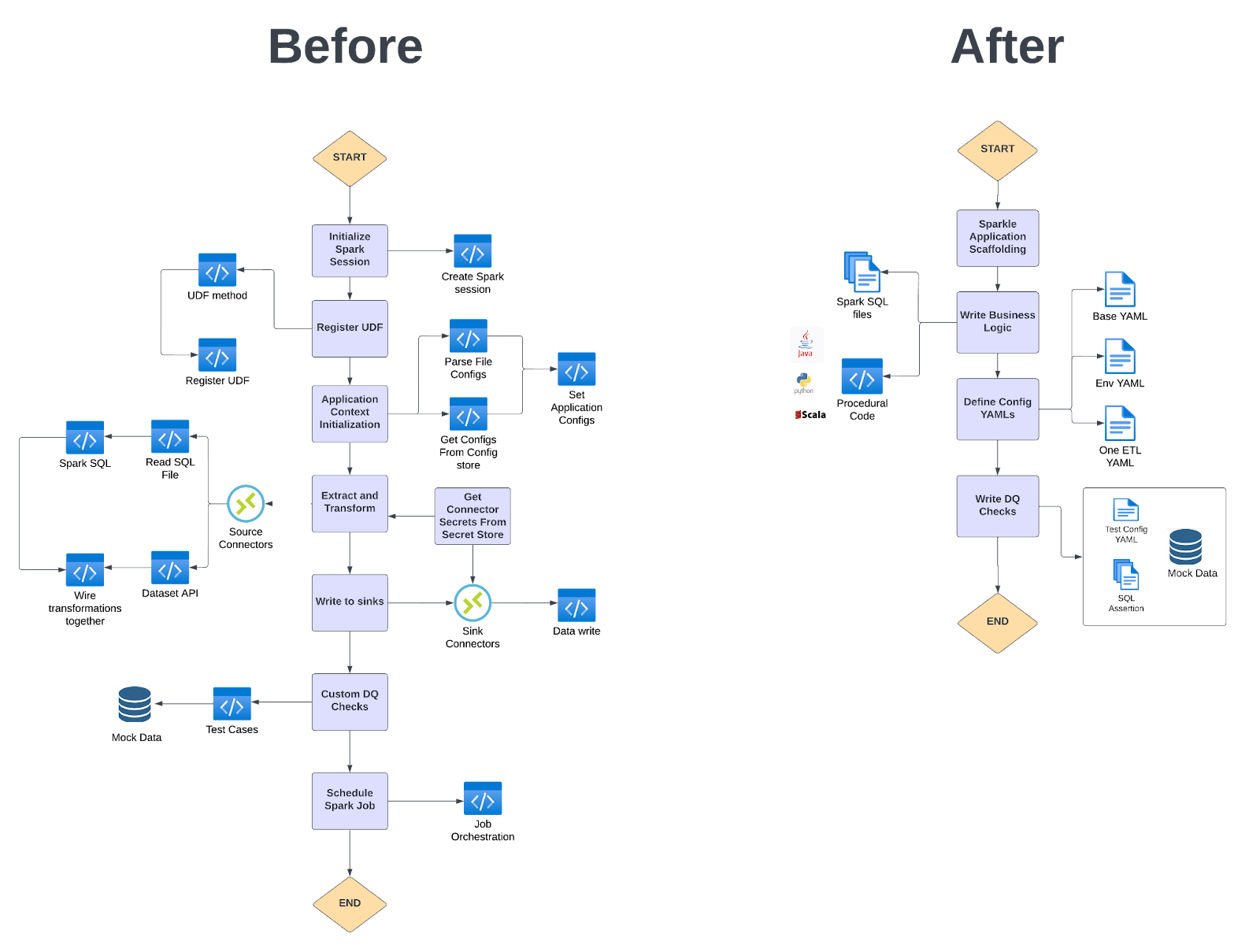
The above diagram depicts a flow comparison for the user writing ETL before and after using Sparkle. We can notice that all the sub-steps in each step would be defined and re-defined in each new pipeline in the BEFORE flow. At the same time, users only write the business logic in the AFTER flow and every other step is managed via configuration.
Benefits and Impact
Following are some benefits and impacts realized after adopting the Sparkle framework.
- Code Reusability
- Support for custom implementation of readers, writers, connectors, and lookup support
- User-provided environment configuration, native integration with dynamic config, and secret management tools
- Developer productivity improvement by at least 30%
- Easy way to write a mix of SQL and procedural-based ETL by helping developers focus only on writing business logic
- Simplify the complexity of writing Spark jobs with a minimal understanding of Spark internals
- Standardized ETL creation @ Uber
- A single framework that can be used across different languages like Java, Scala, and Python
- Improved Data Quality with 100% test coverage
- Support to create multiple test suites to test each transformation module
- Support to create multiple test suites to test pipelines end-to-end in local mode
- Optimized Performance with a minimum of 5x improvement
- By migrating the existing Hive-based ETL to Sparkle-based ETL, there was a performance improvement of a minimum of 5x in each pipeline in execution time and resource utilization. Hive to Spark migration brings inherent performance benefits. Additional performance gains were achieved due to:
- Previously multiple Hive SQLs in a single ETL job were executed by the DAG defined by ETL developers via an orchestrator tool. This often resulted in unoptimized execution. In contrast, Sparkle uses the Spark SQL query planner and automatic DAG generation for the multiple Spark SQLs defined for a single ETL job. This ensures that optimal resources are used for computation.
- Each hive SQL gets executed in a separate hive context and intermediate SQL outputs get persisted in a hive table. Whereas Sparkle executes all the SQL in a single SparkContext and registers each of this intermediate SQL output as Spark temp tables and it has support for enabling cache to reuse DAGs on multiple target writes. Due to the in-memory stage compute and reused DAG, executions resulted in better performance as compared to the previous approach.
Way Forward
In the future, we aim to improve the developer experience in ETL creation by integrating Sparkle with uWorc, extending support for various sources and sinks including Cassandra, DocStore, and custom cloud connectors, providing Hudi incremental read support for Hudi-based sources, and migrating legacy frameworks to Sparkle-based pipelines for batch ETL standardization at Uber.
Acknowledgments
Many thanks to the team members of Uber Data Intelligence and the Uber GDW team for the contribution of the many Sparkle features.
Apache®, Apache Kafka®, Apache Flink®, Apache Pinot™, Apache Spark™, and the Apache Hive™ logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
MySQL™ are registered trademarks of Oracle and/or its affiliates. No endorsement by Oracle is implied by the use of these marks.
“Steel Wool Sparks on the Beach” by Photo Extremist is licensed under CC BY-ND 2.0. To view a copy of this license, visit https://creativecommons.org/licenses/by-nd/2.0/?ref=openverse. No Changes were made.

Dinesh Jagannathan
Dinesh Jagannathan is a Staff Engineer on the Data Intelligence team. He is focused on building scalable data products to improve data quality, standardizing best practices, and improving developer productivity.

Sharath Bhat
Sharath is a Senior Software Engineer in the Data Intelligence team. He is focused on designing big data systems and building ETL frameworks; boosting developer productivity, enhancing data quality, and evangelizing best practices

Suman Voleti
Suman Voleti is a Staff Engineer in the Global Data Warehouse team. He is focused on building ETL frameworks to standardize the creation of batch pipelines with better performance, data quality, and observability.

Praveen Raj
Praveen Raj is a Software Engineer in the Data Intelligence team. He loves working on foundational problems in the data world and creating simple reusable tools/frameworks as solutions. Works on designing big data datasets and their ingestion systems and ETL frameworks.
Posted by Dinesh Jagannathan, Sharath Bhat, Suman Voleti, Praveen Raj