
For a company of our size and scale, robust, accurate, and compliant accounting and analytics are a necessity, ensuring accurate and granular visibility into our financials, across multiple lines of business.
Most standard, off-the-shelf finance engineering solutions cannot support the scale and scope of the transactions on our ever-growing platform. The ride-sharing business alone has over 4 billion trips per year worldwide, which translates to more than 40 billion journal entries (financial microtransactions). Each of these entries has to be produced in accordance with Generally Accepted Accounting Principles (GAAP), and managed in an idempotent, consistent, accurate, and reproducible manner.
To meet these specific requirements, we built an in-house Uber’s Finance Computation Platform (FCP) —a solution designed to accommodate our scale, while providing strong guarantees on accuracy and explainability. The same solution also serves in obtaining insights on business operations.
There were many challenges in building our financial computation platform, from our architectural choices to the types of controls for accuracy and explainability.
Motivation and Technical Challenges
As the scale of our operations grew across multiple services and businesses, guaranteeing accuracy and explainability of financials at scale became cumbersome and costly.
Given that in 2019 our customers take over 15 million trips every day and across a wide variety of services (Eats, Rides, Freight, etc.), we had to deal with a variety of data, unordered activity, and skewed load to produce an accurate, explainable, and standardized representation. Financial auditors often require recreating the state of business activity and financial computation, quarters or even a full year after the fact, during which time we’ve implemented many changes to our policies. Making an already-daunting task even more difficult, we also had to take into account our platform’s multi-country, multi-taxation, multi-business, and multi-product models. These offered a significant variety of use cases and business logic, requiring a robust system to offer ease of change.
Typical Financial Computation
To perform accounting operations and record the necessary financial numbers in the general ledger (GL), we needed to tap into each product’s sales, collections, and payments systems.
One of the simplest and easiest ways to do so is by creating Extract Transform Load (ETL) pipelines to populate warehouse tables for sales, collections, etc and writing Structure Query Language (SQL) queries on top of warehouse tables to generate ledger. This type of typical financial system configuration, depicted below in Figure 1, features various data stores and warehouses to ingest and store financial information for processing.

As an example, an online media company that sells video content might use a typical financial computation, like the one depicted in Figure 1. To record gross revenue in this system, a user would run a query against the sales system data to determine how much revenue it made from sales, then simply save this query and its resulting snapshot for later audits.
While typical financial computation work for many companies, the size, scope, and dynamic nature of our business made this approach incompatible with our requirements. Specifically, we decided that a typical system would be insufficient because:
- Complex Queries: With growth of business and the number of domains, data models change significantly, which increases the complexity of the queries and makes it hard to maintain.
- Need for Snapshotting and an Audit Trail: A substantive financial audit may require proof of record for each and every entry present in the system for up to a year. Hence, it could request snapshotting and an audit trail to source. Mutations on source can cause financial updates, which may not tie back in a typical system, due to lack of data versioning.
Taking our dynamic nature and global scale into account, our financial computations would be far too complex for human-made SQL queries alone to handle. Hence, we created our own Finance Computation Platform (FCP).
The Financial Life Cycle of a Trip
Each trip on our platform goes through a series of synchronous and asynchronous steps across systems (Sales, Payment, FCP-Finance Computation Platform, and PSP-Payment Service Provider), many of which involve and contribute to financial activity. The Finance Computation Platform (FCP) acts as an observer for all sale and payment activities to record their corresponding accounting impacts.
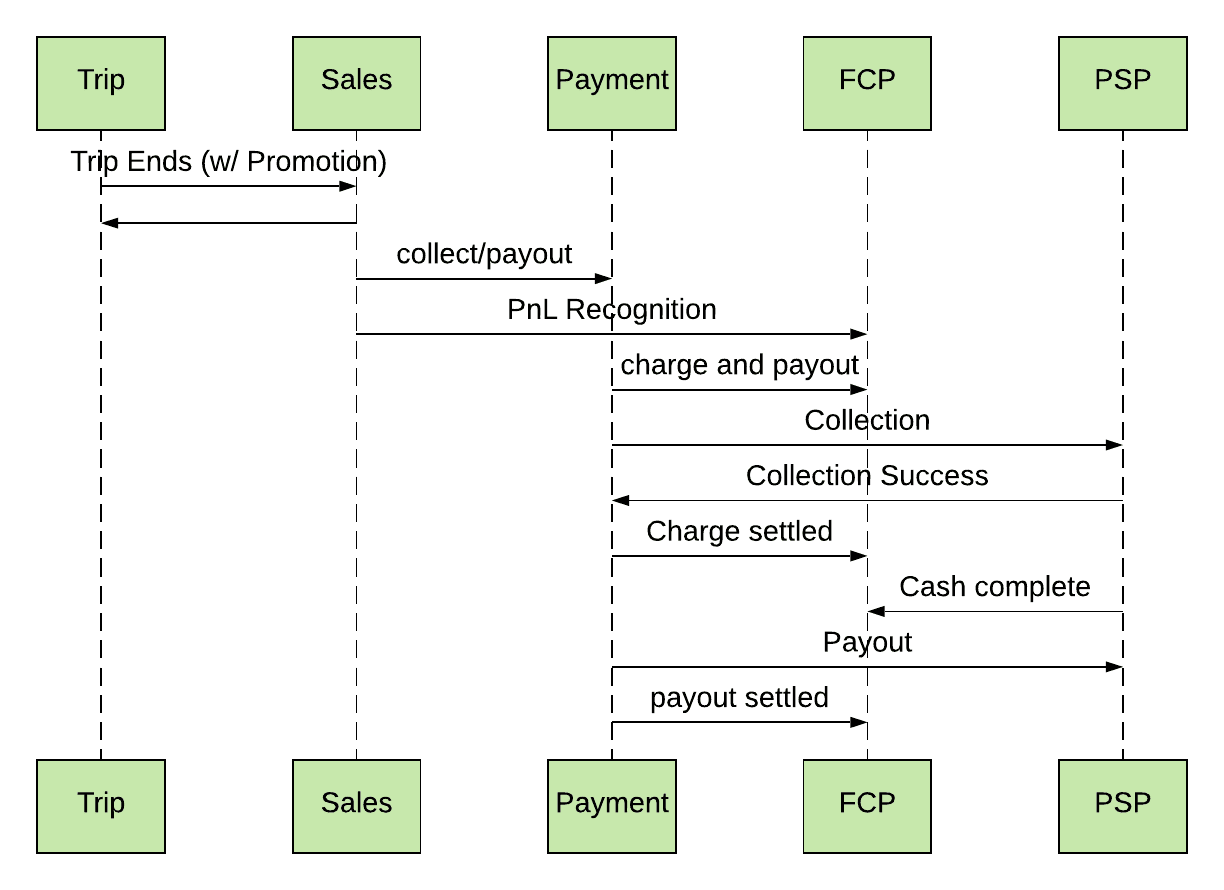
Before diving into our design considerations for this system, we would like to walk through a typical financial life cycle of a trip. To illustrate the procedures outlined in Figure 2, imagine the following scenario: first, a rider receives a promotional code for an Uber trip. They then request a trip using this code. A driver-partner picks them up, drives them to their indicated drop-off spot, and ends the trip. On trip completion, our Financial Computation Platform goes into action, recording the financial impact of the trip by factoring in its earnings, expenses incurred from the promotion, and cost towards various fees and charges to the driver-partner. Then the payment system collects from the rider and pays to the driver-partner. The Finance Computation Platform (FCP) captures these activities as receivables and payables to track cash performance. This data is essential to compute the microeconomics with a granular, trip-level statement of profit and loss.
In addition to powering these granular transactions, our system helps us better understand our broader organizational plans through aggregated views for profit and loss statements at granularity of day, product, or city and operational metrics for line-of-business-specific earnings. Our platform measures business health across various dimensions, such as line of business, date range, and location, providing visibility into growth and gaps so that we can take proactive measures to improve specific businesses or regions.
The data we collect throughout the life cycle of each trip can make a major impact on our business’s day-to-day and long-term success. We designed our Finance Computation Platform’s architecture with certain key principles in mind. The end result is a system that is precise yet comprehensive, robust yet flexible, and fast yet reliable.
Key Tenets of the Finance Computation Platform (FCP)
Data guarantees are critical for any financial system, and so we built our platform with some guiding principles:
- Immutable: Editing a Transaction is disabled, and any corrections are taken as additional transactions
- Idempotent and strong Consistency: System guarantees to always produce the same transaction for a given event
- Auditable: Maintains audit trail of every financial transaction, with full explainability for each action associated with its root
- Complete: Guarantees completeness of financial books through measuring business events dropped by the system and ensuring there are no gaps in financials
- Accurate: Precision is ensured by constant monitoring of miscalculations at various stages of financial lifecycle and flagging any gaps
- Secure: Access control mechanisms on underlying Uber infrastructure helps ensure restricted access to Financial Data
Design Choices
Before building Uber’s Finance Computation Platform’s architecture, we evaluated a number of design options for optimal performance and scalability. We ultimately decided on an event-driven architecture with Schemaless as OLTP (Online Transaction Processing) storage and Apache Hadoop® (Apache Hadoop® Distributed File System) as storage for OLAP (Online Analytic Processing) to power reporting and analytics needs.
Event Processing Architecture
We considered 2 options for our event processing: request-driven and event-driven.
Request-Driven Architecture
At many organizations, financial systems build services that expose Application Programming Interfaces (APIs) to offer accounting treatments for computing one or more financial transactions on a business activity request. This leaves the onus on business domains to invoke APIs with defined request objects. This approach gives flexibility for the platform to only focus on platform features and tooling, without worrying about how the caller service formulates requests.
Event-Driven Architecture
With event-driven architecture, each business domain publishes events to a messaging pipeline, and the financial system acts as a consumer, utilizing the message and providing financial treatment. This approach safeguards against skewed load patterns and abstracts the business domain from financial knowledge.
We chose an event-driven architecture with modularization for:
- Flexibility: Event queue acts as an indirect interface between the business domain and the Finance Computation Platform (FCP), and allows the business domain to focus on business functionality while the Finance Computation Platform (FCP) deals with financial modeling
- Fault Tolerance: Queue infrastructure inherently allows retry to recover from intermittent errors
- Consistency across Uber services: Leverage business event streams already available from services
- Scalability: Event queue allows systems to scale independently and account for uneven load patterns and protection from rogue producers
Uber’s Finance Computation Platform (FCP)
With the above considerations we designed our Finance Computation Platform (FCP).

The Finance Computation Platform (FCP) interacts with a variety of systems. In an Application envelope, Business Ingesters ingest events from our front-line services (such as sales and payments) followed by enrichment to a standardized representation. Financial Engine consumes enriched events and applies Business Rules for Financial treatment, producing financial transactions. Transactions are written to Schemaless and replicated to Apache Hadoop®(HDFS), providing support for reporting and reconciliations with data from sales, payments, and other source systems. Any data inconsistencies identified as part of Batch Reconciliations are alerted or fed back for ingestion to ensure completeness. To assert collection success, collection transactions need to tally with Payment service provider (PSP) files. Hence, PSP processors process PSP files followed by enrichment and financial treatment for collection reconciliation. Transactions are also published to a messaging queue (Kafka) for near real-time consumption for freshness in Aggregator, which groups financials to produce batched incremental reports across fixed dimensions. Several workflows are established to measure accuracy and compute metrics, reporting, and other operational needs. The Economics component powers viewing of our financial data across multiple dimensions, such as region, time, line of business, etc.
Using Schemaless as our Datastore
Each trip results in multiple business events. A highly scalable datastore is obviously a must for 10s of millions of trips every day. Financial data plays a key role in driving business decisions. Unavailable or inconsistent data can lead to financial loss and result in subpar customer experiences. To best support our needs and make our datastore optimally functional, we needed a system with high availability and strong consistency.
We chose Schemaless, Uber’s homegrown datastore, to house our transaction data, because it provides managed clusters and high throughput, availability, and consistency. Moreover, it’s a battle-tested, in-house product, developed specifically for our scale.
Using Apache Hadoop®-based Data Solutions for our Batch Operations
Several reports and data quality checks require scanning large amounts of data, which can burden the datastore with an irregular read load. Hence, we chose to replicate financial transactions in Apache Hadoop® (HDFS) to power our offline financial analysis, business health monitoring, and multi-dimensional reporting.
Service Event Streams
A variety of services power our business. These services process sales (rideshare trips, Eats orders, etc.), payments (credit cards, wallets, bank accounts, organizations, etc.), incentives (promotions, loyalty benefits, etc.) and other types of transactions, such as user rewards.
Our services already follow an event-driven architecture that powers asynchronous features and functionalities, making this architecture an obvious choice for our Finance Computation Platform (FCP). It leverages already-established streams of information with an exception for PSP data, which is available in file dumps.
Enrichment
When first captured, source information is unstructured and devoid of some financially relevant information. Financial Computation Platform enriches the heterogeneous event data in order to give us a standardized data representation. This module interacts with various services for additional information, and caches for reuse across multiple sources.
Application Envelope
Each source event enrichment and processing runs in separate Application Envelopes, allowing to scale the processing layer per source, since different sources operate at such a wide range of different scales.
Financial Engine
Financial Engine is where the core accounting functionalities are served. It maintains a rule repository to host various configurable business rules that have been modeled by Financial experts. The Financial Engine consumes enriched financial events, applies modelled financial treatment, and produces financial transactions that are stored in Schemaless ensuring idempotency. Each financial transaction hosts journal entries that represent profit and loss against microtransactions at trip-level granularity. Financial transactions are also published to Kafka streams for real-time consumption by a few downstreams and source-to-ETL pipelines (batch processing).
Data Checkpoints
Financial Transactions produced by the Financial Engine are immutable and strongly consistent. Hence, only new transactions are created in the system that allows for checkpointing the data periodically. This enables downstream to operate on a consistent and checkpointed time series, simplifying a large set of operations associated with reporting and reconciliations.
Aggregator
Our engine records financial transactions at a granular level. While this kind of comprehensive data collection is important, it’s impossible to scan and collect the massive quantities of data held in the financial engine’s transactional datastore. To accomplish this, we created an aggregator system to collect and report on this transactional information from the financial engine. As its name suggests, the aggregator leverages the financial engine’s data to produce simplified, aggregated reports on various dimensions (like a single city), which our financial books can then actually use. This system is capable of near-real-time aggregation on a fixed set of dimensions, and plays a critical role in ensuring that we close our financial books without delay.
Data Correctness
Data completeness and accuracy are critical to guarantee quality and success during financial audits. Multiple batch-based reconciliations are put in place to ensure data completeness and perform set comparisons across systems and sources.
Financial accuracy is achieved by tallying numbers across systems of a trip’s lifecycle. Batch-based health check data pipelines and workflows are developed to measure business health, isolate, and reason for gaps. It is important to note that these needs often increase along with growth in domains, and so solutions have to be robust, extensible and easy to configure and operate. Hive/Spark-based solutions fit our needs by decoupling these processes from our financial engine.
Workflows
Various day-to-day operations (powering metric computations, reportings, batch functions, etc.) are modelled as ETL pipelines in our systems. These automate multiple operations and allow for loads of inferences on data, enabling forecasting and planning.
Presentation Layer
Economics portal is our presentation layer, which generates summaries of insights from the Finance Computation Platform’s detailed reports on our overall financials across different lines of business, products, regions, and other categories. The Economics Portal’s operational and non-operational metrics help our finance and accounting professionals make better decisions around budgeting, forecasting, and financial planning across these various lines. The web component of this layer is written in fusion.js.
Moving Forward
Our Finance Computation Platform’s event-driven architecture allows this system to scale independently. We crafted each component of the FCP’s architecture with our key tenets in mind. Our focus has always been to provide accuracy, completeness and auditability at our business’ immense scale.
Our journey doesn’t end here. While we’ve built our core platform and services, we still aim to solve further finance problems and optimize our operations in the near future. As our business grows, we have to constantly invest and innovate in improving the pace of development, self-service controls, better explainability and data inferences, and a reduced storage footprint.
If building financial technology systems to power large-scale businesses like Uber interests you, consider applying for a role on our team.
Acknowledgement
This work would not have been possible without significant contributions from many engineers and leadership in the Finance Engineering team at Uber. I would also like to thank seniors at Uber for providing feedback and support with reviews and suggestions.

Shashank Agarwal
Shashank Agarwal is a Senior Staff Software Engineer and has been with Uber for more than 5 years. Shashank Agarwal played a pivotal role in initiating the project's vision, providing invaluable guidance to the team on crucial design decisions. He has led multiple architectural contributions within Fintech at Uber. Currently, he is leading the efforts to standardize Fares at Uber and increase operational efficiency. He has more than 16 years of experience in Software Development, and outside of Uber he has built messaging platforms as well as mobile and desktop applications.
Posted by Shashank Agarwal
Related articles





Most popular

MySQL At Uber

Adopting Arm at Scale: Bootstrapping Infrastructure

Adopting Arm at Scale: Transitioning to a Multi-Architecture Environment
