How Uber Serves Over 40 Million Reads Per Second from Online Storage Using an Integrated Cache
February 15, 2024 / Global
Introduction
Docstore is Uber’s in-house, distributed database built on top of MySQL®. Storing tens of PBs of data and serving tens of millions of requests/second, it is one of the largest database engines at Uber used by microservices from all business verticals. Since its inception in 2020, Docstore users and use cases are growing, and so are the request volume and data footprint.
The growing number of demands from business verticals and offerings introduces complex microservices and dependency call graphs. As a result, applications demand low latency, higher performance, and scalability from the database, while simultaneously generating higher workloads.
Challenges
Most of the microservices at Uber use databases backed by disk-based storage in order to persist data. However, every database faces challenges serving applications that require low-latency read access and high scalability.
This came to a boiling point when one use case required much higher read throughput than any of our existing users. Docstore could have accommodated their needs, as it is backed by NVMe SSDs, which provide low latency and high throughput. However, using Docstore in the above scenario would have been cost prohibitive and would have required many scaling and operational challenges.
Before diving into the challenges, let’s understand the high-level architecture of Docstore.
Docstore Architecture
Docstore is mainly divided into three layers: a stateless query engine layer, a stateful storage engine layer, and a control plane. For the scope of this blog, we will talk about its query and storage engine layers.
The stateless query engine layer is responsible for query planning, routing, sharding, schema management, node health monitoring, request parsing, validation, and AuthN/AuthZ.
The storage engine layer is responsible for consensus via Raft, replication, transactions, concurrency control, and load management. A partition is typically composed of MySQL nodes backed by NVMe SSDs, which are capable of handling heavy read and write workloads. Additionally, data is sharded across multiple partitions containing one leader and two follower nodes using Raft for consensus.
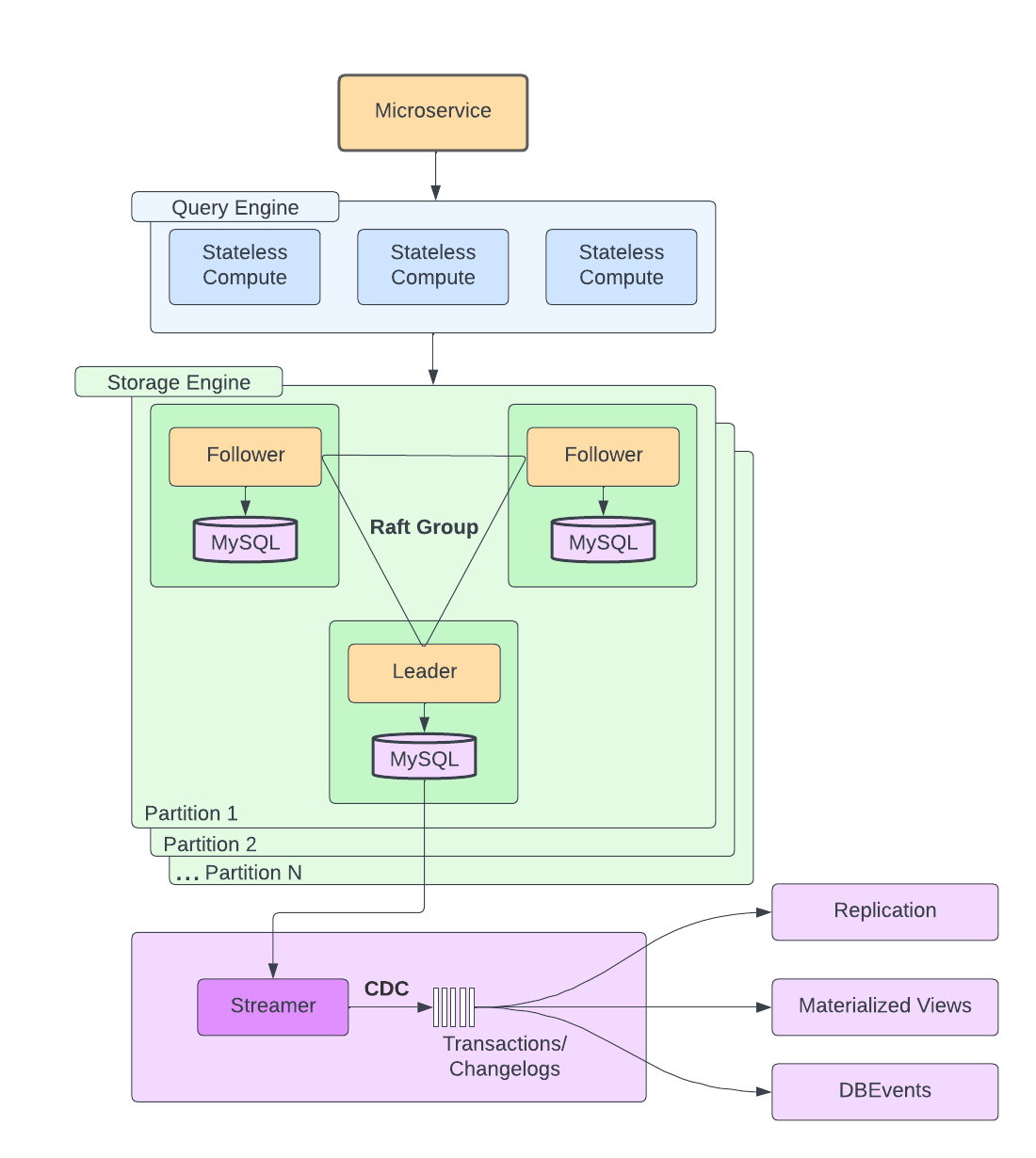
Now let’s look at some of the challenges faced when services demand low-latency reads at a high scale:
- Speed of data retrieval from disk has a threshold: There’s a limit to how far one can optimize application data models and queries to improve database latency and performance. Beyond that, squeezing out more performance is not possible.
- Vertical scaling: Assigning more resources or upgrading to better hosts with higher performance has its limitations where the database engine itself becomes a bottleneck.
- Horizontal scaling: Splitting shards further across more numerous partitions helps solve the challenges to an extent however doing so is an operationally more complex and lengthy process. We have to ensure data durability and resiliency without any downtime. Also this solution doesn’t fully help to solve the issues of hot keys/partitions/shards.
- Request imbalance: Oftentimes the incoming rate of read requests is orders of magnitude higher than write requests. In such cases, the underlying MySQL node will struggle to keep up with the heavy workload and further impact latencies.
- Cost: Vertical and horizontal scaling to improve latencies are costly in the long term. Costs are multiplied 6x to handle each of the 3 stateful nodes across both regions. Additionally, scaling doesn’t fully address the problem.
To overcome this, microservices make use of caching. At Uber we provide Redis™ as a distributed caching solution. A typical design pattern for microservices is to write to database and cache while serving reads from the cache for improved latencies. However, this approach has following challenges:
- Each team has to provision and maintain their own Redis cache for their respective services
- Cache invalidation logic is implemented decentrally within each microservices
- In case of region failover, services either have to maintain caching replication to stay hot or suffer higher latencies while the cache is warming up in other regions
Individual teams have to expend a large amount of effort to implement their own custom caching solutions with the database. It became imperative to find a better, more efficient solution that not only serves requests at low latency, but is also easy to use and improves developer productivity.
CacheFront
We decided to build an integrated caching solution, CacheFront for Docstore, with following goals in mind:
- Minimize the need for vertical and/or horizontal scaling to support low-latency read requests
- Reduce resource allocation to the database engine layer; caching can be built from relatively cheap hosts, so overall cost efficiency is improved
- Improve P50 and P99 latencies, and stabilize read latency spikes during microbursts
- Replace most of the custom-built caching solutions that were (or will be) built by the individual teams to answer their needs, especially in the cases where the caching is not the core business or competency of the team
- Make it transparent by reusing existing Docstore client without any additional boilerplate to allow benefiting from caching
- Increase developer productivity and allow us to release new features or replace the underlying caching technology transparently to customers
- Detach caching solution from Docstore’s underlying sharding scheme to avoid problems that arise from hot keys, shards, or partitions
- Allow us to horizontally scale out caching layer, independently of the storage engine
- Move ownership for maintaining and on calling Redis from feature teams to the Docstore team
CacheFront Design
Docstore Query Patterns
Docstore supports different ways to query by either primary key or partition key and optionally filtering the data. At a high level it can be mainly be divided into following:
| Key-type / Filter | No Filter | Filter by WHERE clause |
| Rows | ReadRows | – |
| Partitions | ReadPartition | QueryRows |
We wanted to build our solution incrementally, beginning with most common query patterns. It turned out that more than 50% of the queries coming to Docstore are ReadRows requests, and since this also happened to be the simplest use case–no filters and point reads–it was a natural place to start with the integration.
High-Level Architecture
Since Docstore’s query engine layer is responsible for serving reads and writes to clients, it is well suited to integrate the caching layer. It also decouples the cache from disk-based storage, allowing us to scale either of them independently. The query engine layer implements an interface to Redis for storing cached data along with a mechanism to invalidate cached entries. A high-level architecture looks like the following:
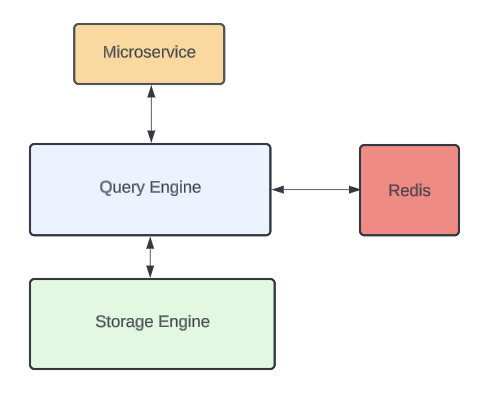
Docstore is a strongly consistent database. Although integrated caching provides faster query responses, some of the semantics around consistency may not be acceptable for every microservice while using cache. For example, cache invalidation may fail or lag behind database writes. For this reason, we made integrated caching an opt-in feature. Services can configure cache usage on a per-database, per-table, and even per-request basis.
If certain flows require strong consistency (such as getting items in an eater’s cart) then the cache can be bypassed, whereas other flows with low write throughput (such as fetching a restaurant’s menu) would benefit from the cache.
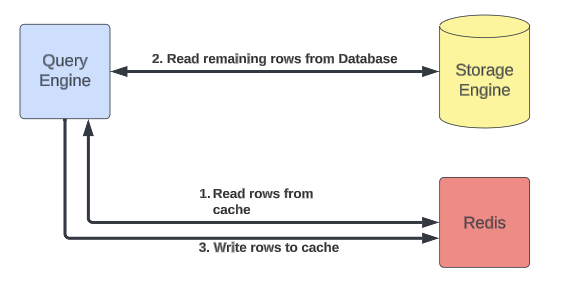
Cached Reads
CacheFront uses a cache aside strategy to implement cached reads:
- Query engine layer gets read request for one more rows
- If caching is enabled, try getting rows from Redis; stream response to users
- Retrieve remaining rows (if any) from the storage engine
- Asynchronously populate Redis with the remaining rows
- Stream remaining rows to users
Cache Invalidation
“There are only two hard things in Computer Science: cache invalidation and naming things.”
– Phil Karlton
Although the caching strategy in the previous section may seem simple, many details had to be considered in order to ensure the cache would work, especially cache invalidation. Without any explicit cache invalidation, cache entries will expire with the configured TTL (by default, 5 minutes). While this may be OK in some cases, most users expect changes to be reflected faster than the TTL. The default TTL could be lowered however this would reduce our cache hit rate without meaningfully improving consistency guarantees.
Conditional Update
Docstore supports conditional updates where one or more rows can be updated based on a filter condition. For example, update the holiday schedule for all restaurant chains in a specified region. Since the results of a given filter can change, our caching layer can’t determine which rows would be affected by a conditional update until the actual rows are updated in the database engine. Due to this, we can’t invalidate and populate cached rows for conditional update in the stateless query engine layer’s write path.
Leveraging Change Data Capture for Cache Invalidation
To fix this, we leveraged Docstore’s change data capture and streaming service, Flux. Flux tails the MySQL binlog events for each of the clusters in our storage engine layer and publishes the events to a list of consumers. Flux powers Docstore CDC (Change Data Capture), replication, materialized views, data lake ingestion, and validating data consistency among nodes in a cluster.
A new consumer was written, which subscribes to data events and either invalidates or upserts the new rows in Redis. Now with this invalidation strategy, a conditional update will result in database change events for affected rows, which will be used to invalidate or populate rows in cache. As a result, we were able to make the cache consistent within seconds of the database change, as opposed to minutes. Additionally, by using binlogs, we don’t run the risk of letting uncommitted transactions pollute the cache.
The final read and write path with cache invalidation looks like the following:
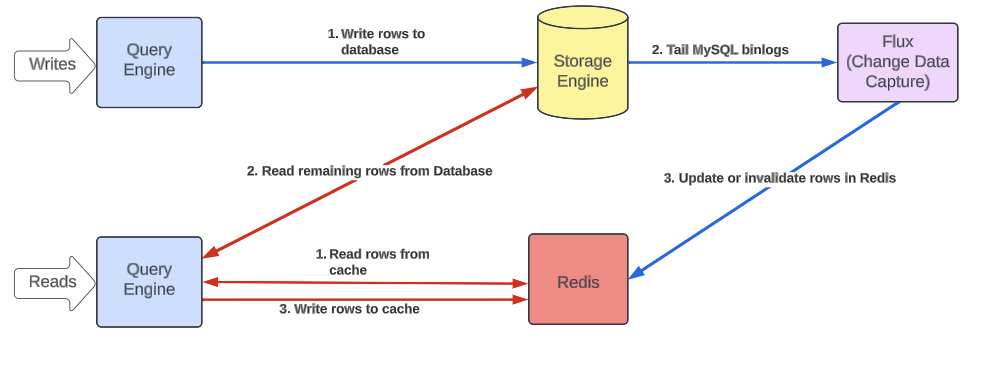
Deduplicating Cache Writes Between Query Engine and Flux
However, the above cache invalidation strategy has a flaw. Since writes happen to the cache simultaneously between the read path as well as the write path, it is possible that we inadvertently write a stale row to the cache, overwriting the newest value that was retrieved from the database. To solve this, we deduplicate writes based on the timestamp of the row set in MySQL, which effectively serves as its version. The timestamp is parsed out from the encoded row value in Redis (see later section on codec).
Redis supports executing custom Lua scripts atomically using the EVAL command. This script takes the same parameters as MSET, however, it also performs the deduplication logic, checking the timestamp values of any rows already written to the cache and ensuring that the value to be written is newer. By using EVAL, all of this can be performed in a single request instead of requiring multiple round trips between the query engine layer and cache.
Stronger Consistency Guarantees for Point Writes
While Flux allows us to invalidate the cache much faster than if we were relying solely on Redis TTLs for expiration of cached entries, it still provides us with eventual consistency semantics. Yet, some use cases require stronger consistency, such as reading-own-writes, so for these scenarios we added a dedicated API to the query engine that lets our users explicitly invalidate the cached rows after the corresponding writes have completed. This allowed us to provide stronger consistency guarantees for point writes, but not for conditional updates, which remain to be invalidated by Flux.
Table Schemas
Before getting into more details about the implementation let’s define a few key terms. Docstore tables have a primary key and partition key.
A primary key (often referred to as a row key) uniquely identifies a row in the Docstore table and enforces a uniqueness constraint. Every table must have a primary key, which can be composed of one or more columns.
A partition key is a prefix of the entire primary key and determines which shard the row will live in. They are not completely separate–rather, partition keys are simply a part of (or equal to) the primary.
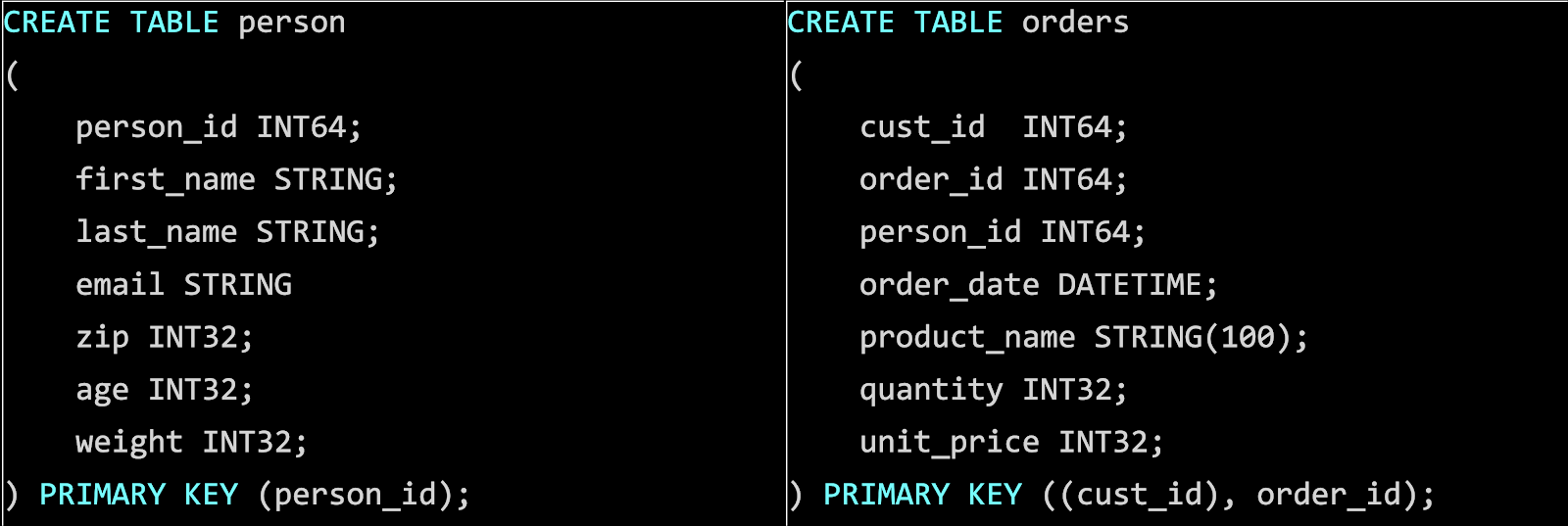
In the example above person_id is both the primary and partition key for the person table. While for orders table cust_id is a partition key and both cust_id and order_id together form a primary key.
Redis Codec
Since primarily we will be caching row reads, we can uniquely identify a row value with a given row key. Since Redis keys and values are stored as strings, we need a special codec to encode the MySQL data in a format that Redis accepts.
The following codec was settled on, as it allows cache resources to be shared by different databases while still maintaining data isolation.

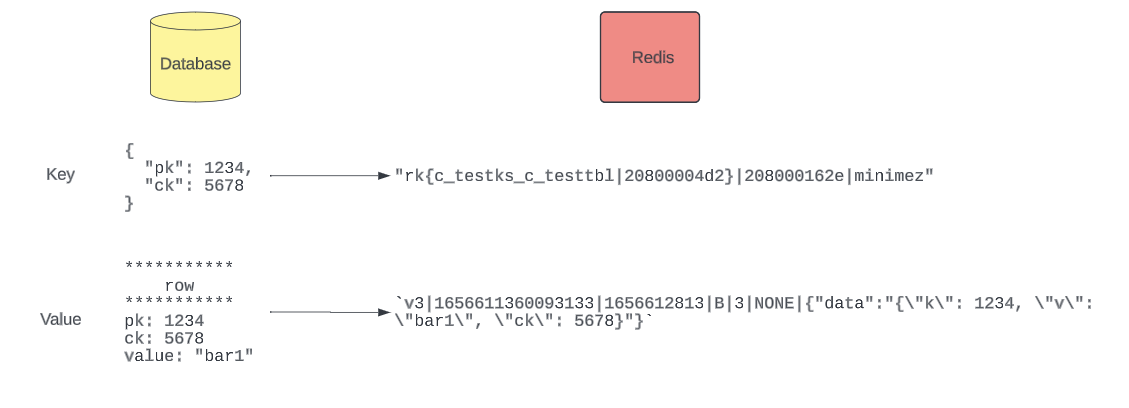
Features
After completing the high-level design, our solution was functional. Now it was time for us to think about scale and resiliency:
- How to verify consistency between the database and cache in real time
- How to tolerate zone/region failures
- How to tolerate Redis failures
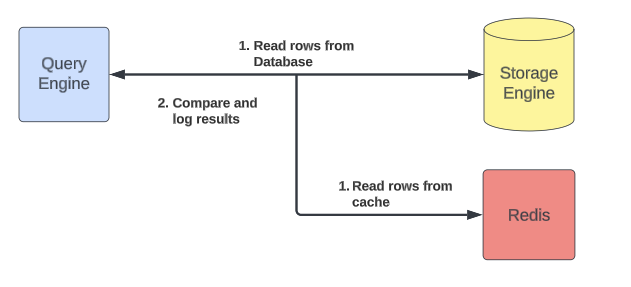
Compare Cache
All this talk about improving consistency means nothing if it’s not measurable, so we added a special mode that shadows read requests to the cache. When reading back, we compare the cached and database data and verify that they are the same. Any mismatches–either stale rows present in the cache or rows present in the cache, but not the database–are logged and emitted as metrics. With the addition of cache invalidation using Flux, the cache is 99.99% consistent.
Cache Warming
A Docstore instance spawns two different geographical regions to ensure high availability and fault tolerance. The deployment is active-active, meaning requests can be issued and served in any region and all writes are replicated across regions. In case of a region failover, another region must be able to serve all requests.
This model poses a challenge for CacheFront, since caches should always be warm across regions. If they are not, a region fail-over will increase the number of requests to the database due to cache misses from the traffic originally served in the failed region. This will prevent us from scaling down the storage engine and reclaiming any capacity, since the database load would be as high as it would have been without any caching.
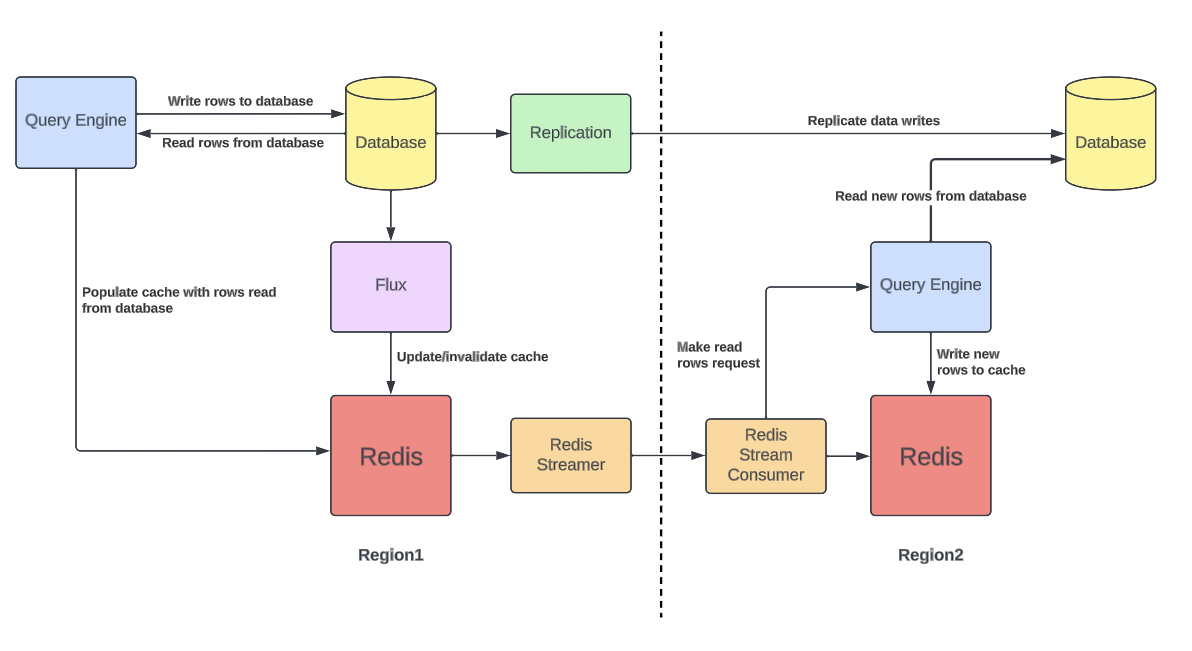
The cold cache problem can be solved with cross-region Redis replication, but it poses a problem. Docstore has its own cross-region replication mechanism. If we replicate the cache content using Redis cross-region replication, we will have two independent replication mechanisms, which could lead to cache vs. storage engine inconsistency. In order to avoid this cache inconsistency problem for CacheFront, we enhanced Redis cross-region replication components by adding a new cache warming mode.
To ensure that the cache is always warm, we tail the Redis write stream and replicate keys to the remote region. In the remote region instead of directly updating the remote cache, read requests are issued to the query engine layer which, upon a cache miss, reads from the database and writes to the cache as described in the Cached Reads section of the design. By only issuing read requests upon a cache miss, we also avoid unnecessarily overloading the storage engine. The response stream of read rows from the query engine layer is simply discarded, since we are not really interested in the result.
By replicating keys instead of values, we always ensure that the data in the cache is consistent with the database in its respective region and we keep the same working set of cached rows in Redis in both regions, while also limiting the amount of cross-region bandwidth used.
Negative Caching
In scenarios where many of the reads are for non-existent rows, it would be good to cache the negative result instead of having a cache miss and querying the database each time. To enable this, we built negative caching into Cachefront. Similar to the regular cache population strategy where all rows returned from the database are written to the cache, we also keep track of any rows that were queried but not read from the database. These non-existent rows are written to the cache with a special flag and in future reads, if the flag is found, we ignore the row when querying the database and also do not return any data back to the user for the row.
Sharding
Although Redis is not heavily impacted by hot partition issues, some of Docstore’s large customers generate a very large number of read-write requests, which would be challenging to cache in a single Redis cluster, typically limited in the maximum number of nodes it can have. To mitigate this, we allow a single Docstore instance to map to multiple Redis clusters. This also avoids a complete database meltdown where a large number of requests can be issued against it, in case multiple nodes in a single Redis cluster are down and cache is not available for certain ranges of keys.
However even with data sharded across multiple Redis clusters, a single Redis cluster going down may create a hot-shard issue on the database. To mitigate this, we decided to shard Redis clusters by partition key, which is different from the database sharding scheme in Docstore. Now we can avoid overloading a single database shard when a single Redis cluster goes down. All requests from a failed Redis shard will be distributed among all database shards, as shown below:
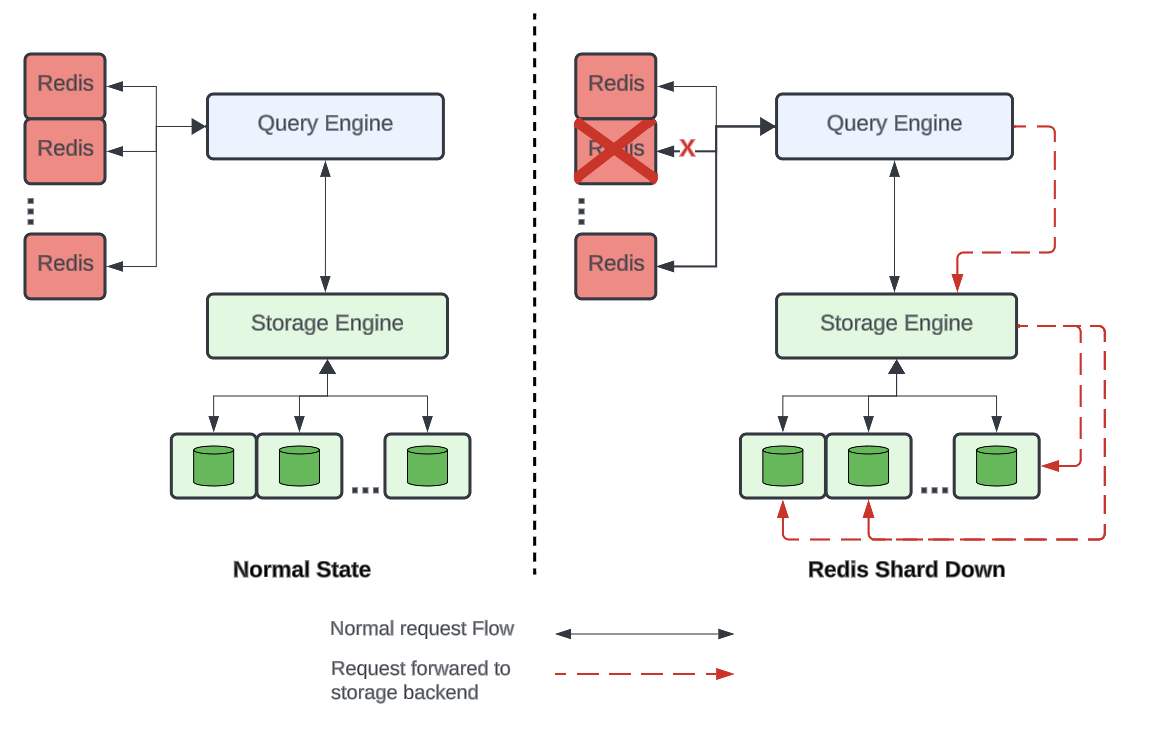
Circuit Breakers
If a Redis node goes down, we’d like to be able to short circuit requests to that node to avoid the unnecessary latency penalty of a Redis get/set request for which we have high confidence that it will fail. To achieve this, we use a sliding window circuit breaker. We count the number of errors on each node per time bucket and compute the number of errors in the sliding window width.

The circuit breaker is configured to short circuit a fraction of the requests to that node, proportional to the error count. Once the maximum allowed error count is hit, the circuit breaker is tripped and no more requests can be made to the node until the sliding window passes.
Adaptive Timeouts
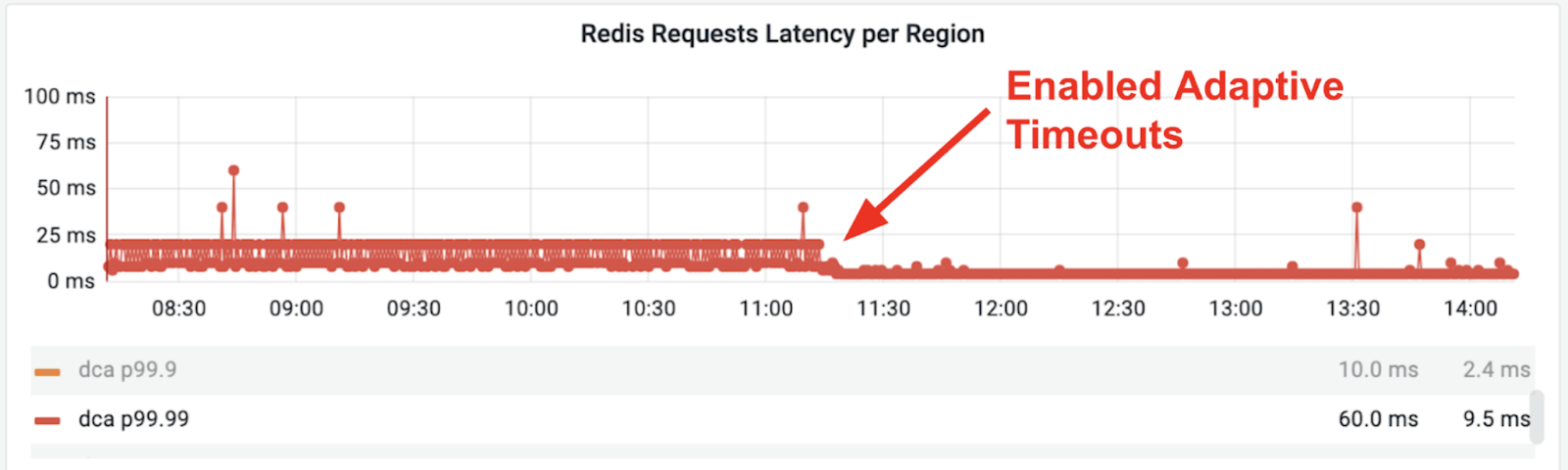
We realized that it is sometimes difficult to set the right timeouts for Redis operations. A timeout that is too short causes Redis requests to fail too early, wasting Redis resources and putting extra load on the database engine. A timeout that is too long impacts the P99.9 and P99.99 latencies, and in the worst case a request may exhaust the entire timeout that is passed in the query. While it’s possible to mitigate these issues by configuring an arbitrarily low default timeout, we risk setting a timeout too low where many requests bypass the cache and go to the database or setting a timeout too high, which leads us back to the original issue.
We needed to adjust request timeouts automatically and dynamically such that the P99 of requests to Redis are succeeding within the allocated timeout, while at the same time cutting down entirely the long tail of latencies. Configuring adaptive timeouts means allowing the Redis get/set timeout value to be adjusted dynamically. By allowing adaptive timeouts, we can set a timeout equivalent to the P99.99 latency of cache requests, thereby letting 99.99% of requests go to the cache with a fast response. The remaining 0.01% of requests, which would have taken too long, can be canceled quicker and served from the database.
With the enabling of adaptive timeouts, we no longer need to tune the timeouts manually to match the desired P99 latency, and instead can only set the maximum acceptable timeout limit, beyond which the framework is not allowed to go (because the maximum timeout is set by the client request anyways).
Results
So did we succeed? We originally set out to build an integrated cache that’s transparent to our users. We wanted our solution to help improve latencies, be easily scalable, help curb load and costs on our storage engine and all while having good consistency guarantees.
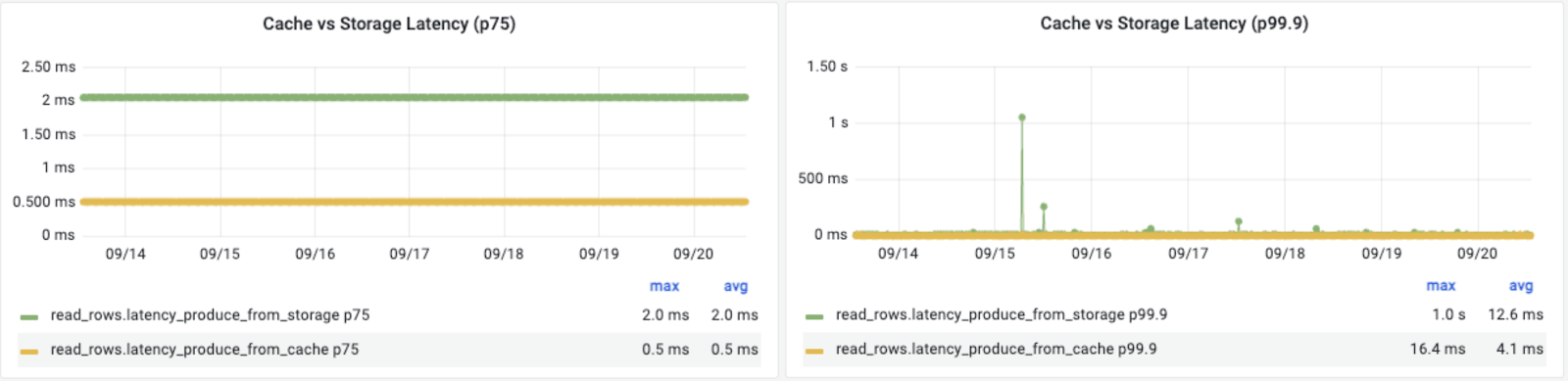
- Request latencies with integrated cache are significantly better. P75 latency is down 75% and P99.9 latency is down over 67% while also limiting latency spikes, as seen above.
- Cache Invalidation using Flux and Compare cache mode help us ensure good consistency.
- Since it sits behind our existing APIs, it is transparent to users and can be managed internally while still giving flexibility to users through header-based options.
- Sharding and cache warming allow it to be scalable and fault tolerant. In fact, one of our largest initial use cases drives over 6M RPS with a 99% cache hit rate with a proven successful failover where all traffic was redirected to the remote region.
- The same use-case would have originally required approximately 60K CPU cores in order to serve 6M RPS from the storage engine directly. With CacheFront we serve approximately 99.9% cache hits with only 3K Redis cores, allowing us to reduce the capacity.
Today CacheFront supports over 40M requests per second across all Docstore instances in production, and the number is growing.
We’ve addressed one of the core challenges in scaling the read workload on Docstore via CacheFront. It not only made it possible to onboard large-scale use cases that demand high throughput and low-latency reads, but also helped us reduce load on the storage engine and save resources, improving the overall cost of storage and allowing developers to focus on building products instead of managing infrastructure.
If you like challenges related to distributed systems, databases, storage, and cache, please explore and apply to open positions here.
Oracle, Java, MySQL, and NetSuite are registered trademarks of Oracle and/or its affiliates. Other names may be trademarks of their respective owners.
Redis is a trademark of Redis Labs Ltd. Any rights therein are reserved to Redis Labs Ltd. Any use herein is for referential purposes only and does not indicate any sponsorship, endorsement or affiliation between Redis and Uber.

Preetham Narayanareddy
Preetham Narayanareddy is a Senior Software Engineer on the Core Storage team at Uber. He has worked on the design and implementation of many Docstore and CacheFront features and is focused on creating customer-centric products that enhance user experiences. In his free time he enjoys solving Rubik's cubes, cycling, bouldering, and sharing his passions through writing and videos.

Eli Pozniansky
Eli Pozniansky is a Sr Staff Engineer on the Core Storage team at Uber. He is the tech lead and one of the main developers of both CacheFront and Flux, responsible for leading the design, development and rollout to production of both projects from their inception to serving 10s of millions of cache hits per second.

Zurab Kutsia
Zurab Kutsia is a Staff Engineer, TLM on the Core Storage team at Uber. He is one of the main authors of Docstore and has designed and implemented multiple critical components of the database since its inception. Zurab now leads and manages the query engine layer of the Docstore ecosystem.

Afshin Salek
Afshin Salek is a Staff Engineer on the Core Storage team at Uber leading the Redis team. The Redis team at Uber manages tens of thousands of Redis nodes serving 100s of TiBs of capacity and 100s of millions of requests-per-second. Redis is used by 100s of microservices and virtually all the critical ones providing super low latency access to required data. In his free time, he enjoys traveling, photography, reading books and building Legos.

Piyush Patel
Piyush Patel is a Sr. Engineering Manager on the Core Storage Platform team at Uber. The team provides a world-class platform that powers all the critical functions and lines of business at Uber. The Core Storage Platform serves tens of millions of QPS with an availability of 99.99% or more and stores tens of Petabytes of operational data. His interests include large scale distributed systems, data storage and retrieval, and cloud computing.
Posted by Preetham Narayanareddy, Eli Pozniansky, Zurab Kutsia, Afshin Salek, Piyush Patel
Related articles



Most popular

MySQL At Uber

Adopting Arm at Scale: Bootstrapping Infrastructure

Adopting Arm at Scale: Transitioning to a Multi-Architecture Environment
